 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASPNet++: Joint Multi-Agent Motion Prediction
Aug 15, 2023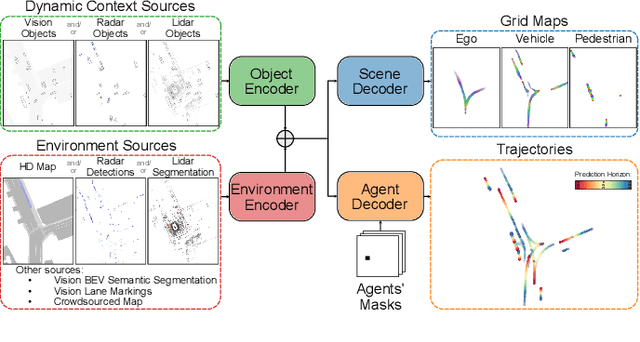
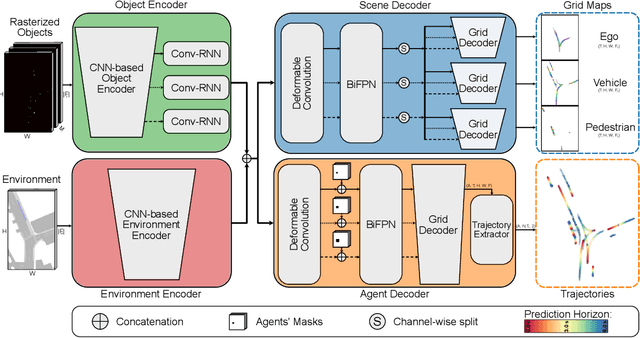
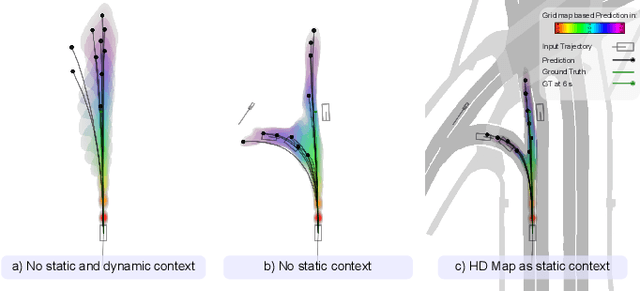
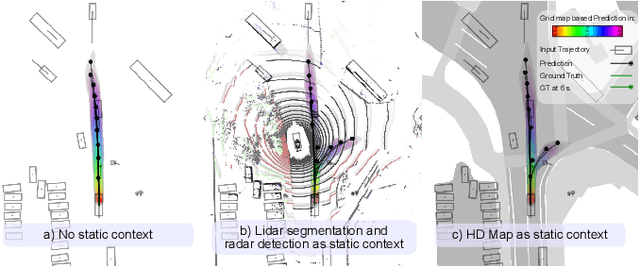
The prediction of road users' future motion is a critical task in supporting advanced driver-assistance systems (ADAS). It plays an even more crucial role for autonomous driving (AD) in enabling the planning and execution of safe driving maneuvers. Based on our previous work, Context-Aware Scene Prediction Network (CASPNet), an improved system, CASPNet++, is proposed. In this work, we focus on further enhancing the interaction modeling and scene understanding to support the joint prediction of all road users in a scene using spatiotemporal grids to model future occupancy. Moreover, an instance-based output head is introduced to provide multi-modal trajectories for agents of interest. In extensive quantitative and qualitative analysis, we demonstrate the scalability of CASPNet++ in utilizing and fusing diverse environmental input sources such as HD maps, Radar detection, and Lidar segmentation. Tested on the urban-focused prediction dataset nuScenes, CASPNet++ reaches state-of-the-art performance. The model has been deployed in a testing vehicle, running in real-time with moderate computational resources.
Deep Learning Method for Cell-Wise Object Tracking, Velocity Estimation and Projection of Sensor Data over Time
Jun 18, 2023Current Deep Learning methods for environment segmentation and velocity estimation rely on Convolutional Recurrent Neural Networks to exploit spatio-temporal relationships within obtained sensor data. These approaches derive scene dynamics implicitly by correlating novel input and memorized data utilizing ConvNets. We show how ConvNets suffer from architectural restrictions for this task. Based on these findings, we then provide solutions to various issues on exploiting spatio-temporal correlations in a sequence of sensor recordings by presenting a novel Recurrent Neural Network unit utilizing Transformer mechanisms. Within this unit, object encodings are tracked across consecutive frames by correlating key-query pairs derived from sensor inputs and memory states, respectively. We then use resulting tracking patterns to obtain scene dynamics and regress velocities. In a last step, the memory state of the Recurrent Neural Network is projected based on extracted velocity estimates to resolve aforementioned spatio-temporal misalignment.
Quantification of Uncertainties in Deep Learning-based Environment Perception
Jun 05, 2023In this work, we introduce a novel Deep Learning-based method to perceive the environment of a vehicle based on radar scans while accounting for uncertainties in its predictions. The environment of the host vehicle is segmented into equally sized grid cells which are classified individually. Complementary to the segmentation output, our Deep Learning-based algorithm is capable of differentiating uncertainties in its predictions as being related to an inadequate model (epistemic uncertainty) or noisy data (aleatoric uncertainty). To this end, weights are described as probability distributions accounting for uncertainties in the model parameters. Distributions are learned in a supervised fashion using gradient descent. We prove that uncertainties in the model output correlate with the precision of its predictions. Compared to previous concepts, we show superior performance of our approach to reliably perceive the environment of a vehicle.
Semantic Segmentation of Radar Detections using Convolutions on Point Clouds
May 22, 2023For autonomous driving, radar sensors provide superior reliability regardless of weather conditions as well as a significantly high detection range. State-of-the-art algorithms for environment perception based on radar scans build up on deep neural network architectures that can be costly in terms of memory and computation. By processing radar scans as point clouds, however, an increase in efficiency can be achieved in this respect. While Convolutional Neural Networks show superior performance on pattern recognition of regular data formats like images, the concept of convolutions is not yet fully established in the domain of radar detections represented as point clouds. The main challenge in convolving point clouds lies in their irregular and unordered data format and the associated permutation variance. Therefore, we apply a deep-learning based method introduced by PointCNN that weights and permutes grouped radar detections allowing the resulting permutation invariant cluster to be convolved. In addition, we further adapt this algorithm to radar-specific properties through distance-dependent clustering and pre-processing of input point clouds. Finally, we show that our network outperforms state-of-the-art approaches that are based on PointNet++ on the task of semantic segmentation of radar point clouds.
* 5th International Conference on Artificial Intelligence, Automation and Control Technologies (AIACT 2021), 26-28 March 2021, Shanghai, China
Fake it, Mix it, Segment it: Bridging the Domain Gap Between Lidar Sensors
Dec 19, 2022


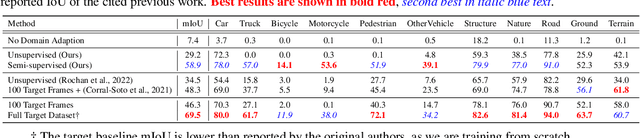
Segmentation of lidar data is a task that provides rich, point-wise information about the environment of robots or autonomous vehicles. Currently best performing neural networks for lidar segmentation are fine-tuned to specific datasets. Switching the lidar sensor without retraining on a big set of annotated data from the new sensor creates a domain shift, which causes the network performance to drop drastically. In this work we propose a new method for lidar domain adaption, in which we use annotated panoptic lidar datasets and recreate the recorded scenes in the structure of a different lidar sensor. We narrow the domain gap to the target data by recreating panoptic data from one domain in another and mixing the generated data with parts of (pseudo) labeled target domain data. Our method improves the nuScenes to SemanticKITTI unsupervised domain adaptation performance by 15.2 mean Intersection over Union points (mIoU) and by 48.3 mIoU in our semi-supervised approach. We demonstrate a similar improvement for the SemanticKITTI to nuScenes domain adaptation by 21.8 mIoU and 51.5 mIoU, respectively. We compare our method with two state of the art approaches for semantic lidar segmentation domain adaptation with a significant improvement for unsupervised and semi-supervised domain adaptation. Furthermore we successfully apply our proposed method to two entirely unlabeled datasets of two state of the art lidar sensors Velodyne Alpha Prime and InnovizTwo, and train well performing semantic segmentation networks for both.
What Can be Seen is What You Get: Structure Aware Point Cloud Augmentation
Jun 20, 2022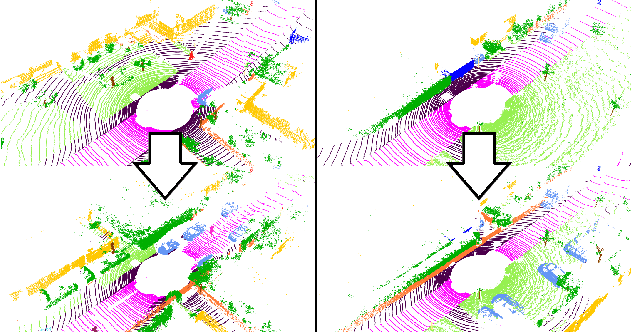
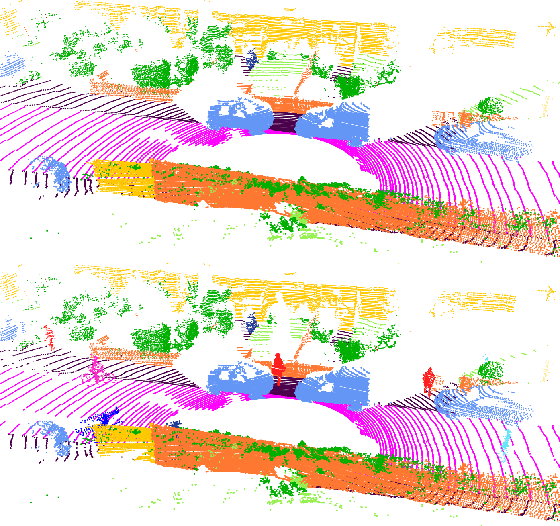
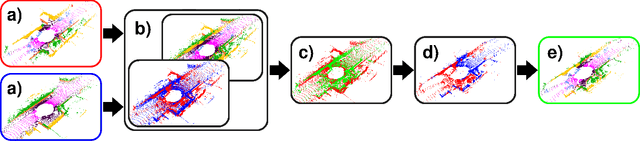
To train a well performing neural network for semantic segmentation, it is crucial to have a large dataset with available ground truth for the network to generalize on unseen data. In this paper we present novel point cloud augmentation methods to artificially diversify a dataset. Our sensor-centric methods keep the data structure consistent with the lidar sensor capabilities. Due to these new methods, we are able to enrich low-value data with high-value instances, as well as create entirely new scenes. We validate our methods on multiple neural networks with the public SemanticKITTI dataset and demonstrate that all networks improve compared to their respective baseline. In addition, we show that our methods enable the use of very small datasets, saving annotation time, training time and the associated costs.
* Published in IEEE IV 2022
Context-Aware Scene Prediction Network (CASPNet)
Jan 18, 2022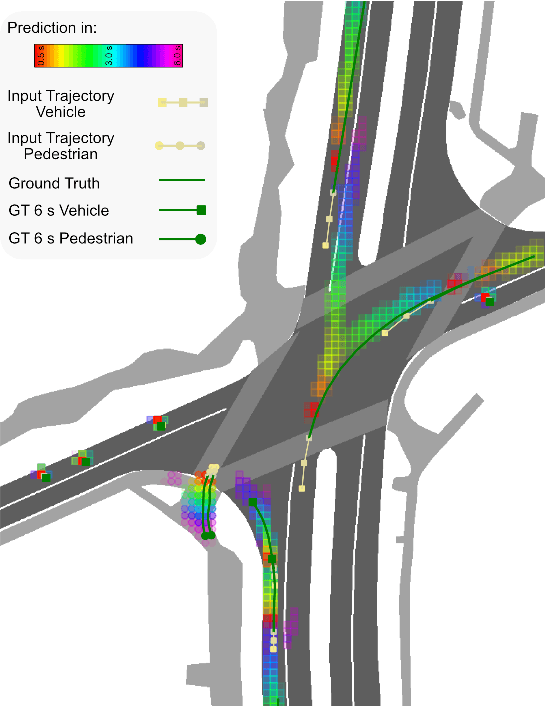
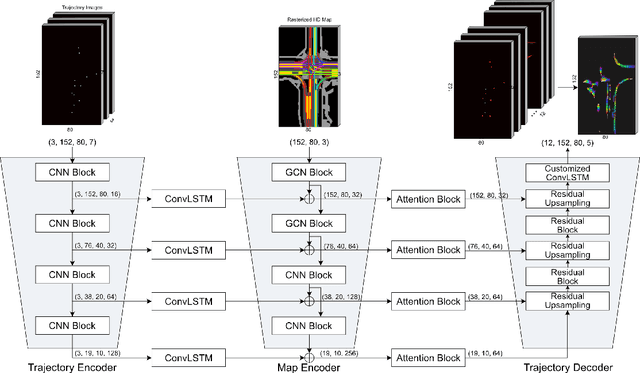
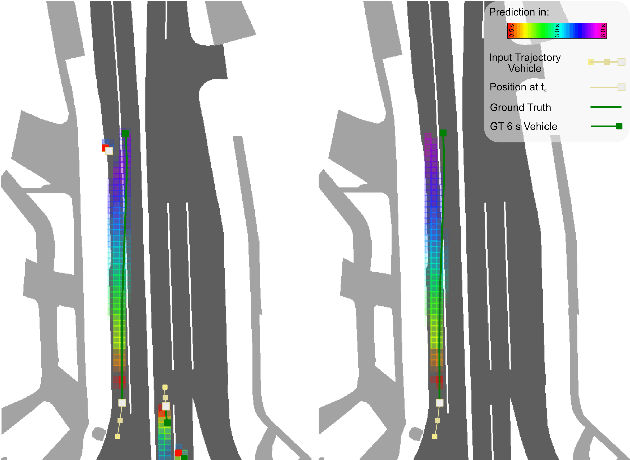
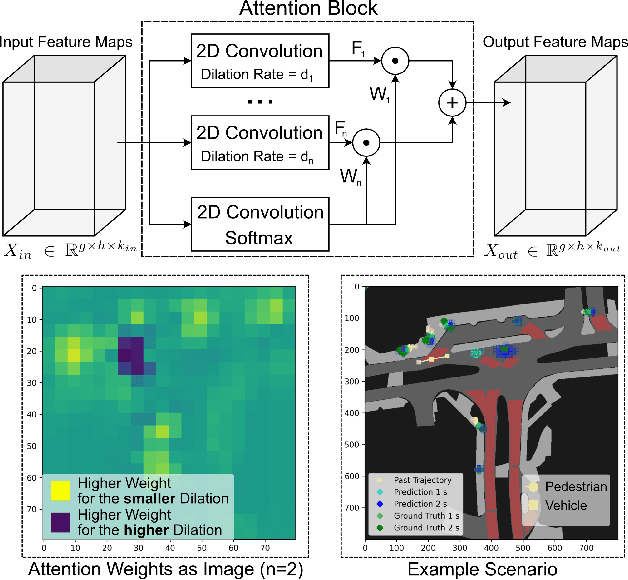
Predicting the future motion of surrounding road users is a crucial and challenging task for autonomous driving (AD) and various advanced driver-assistance systems (ADAS). Planning a safe future trajectory heavily depends on understanding the traffic scene and anticipating its dynamics. The challenges do not only lie in understanding the complex driving scenarios but also the numerous possible interactions among road users and environments, which are practically not feasible for explicit modeling. In this work, we tackle the above challenges by jointly learning and predicting the motion of all road users in a scene, using a novel convolutional neural network (CNN) and recurrent neural network (RNN) based architecture. Moreover, by exploiting grid-based input and output data structures, the computational cost is independent of the number of road users and multi-modal predictions become inherent properties of our proposed method. Evaluation on the nuScenes dataset shows that our approach reaches state-of-the-art results in the prediction benchmark.
Polynomial Trajectory Predictions for Improved Learning Performance
Jan 29, 2021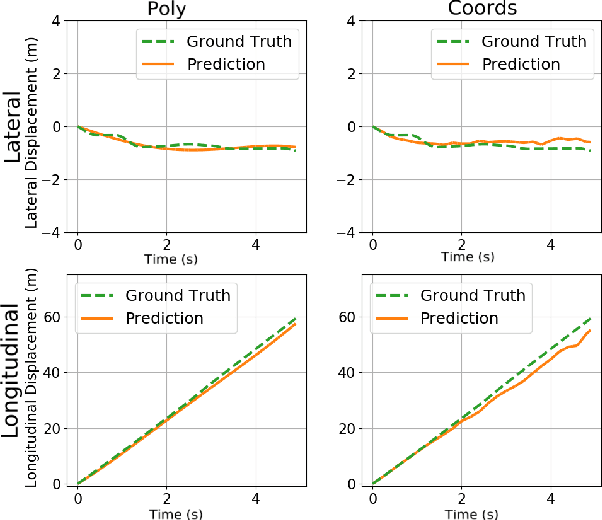
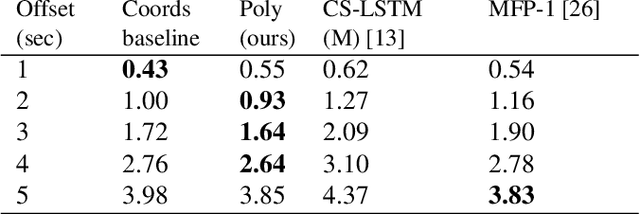
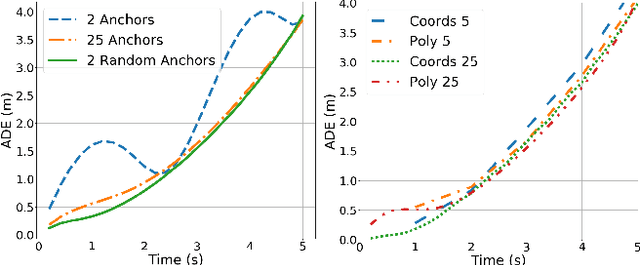
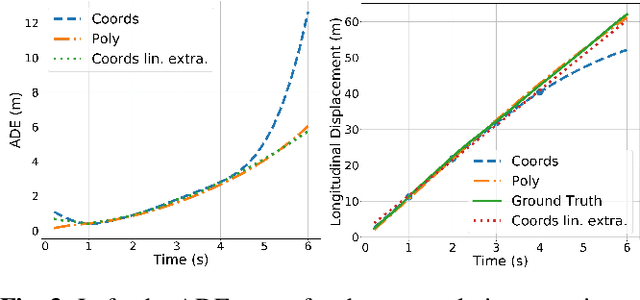
The rising demand for Active Safety systems in automotive applications stresses the need for a reliable short to mid-term trajectory prediction. Anticipating the unfolding path of road users, one can act to increase the overall safety. In this work, we propose to train artificial neural networks for movement understanding by predicting trajectories in their natural form, as a function of time. Predicting polynomial coefficients allows us to increased accuracy and improve generalisation.
On the Robustness of Active Learning
Jun 18, 2020
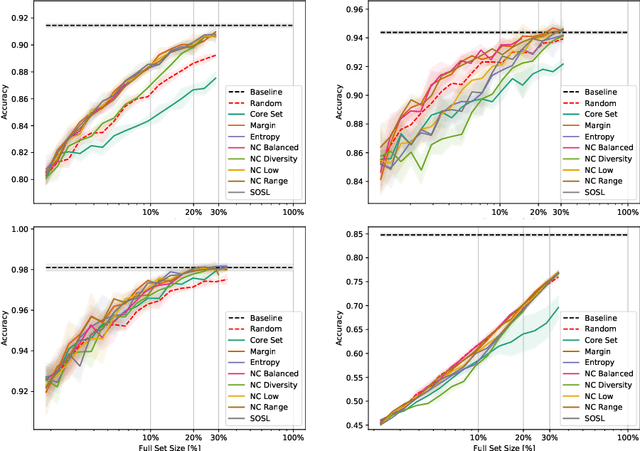
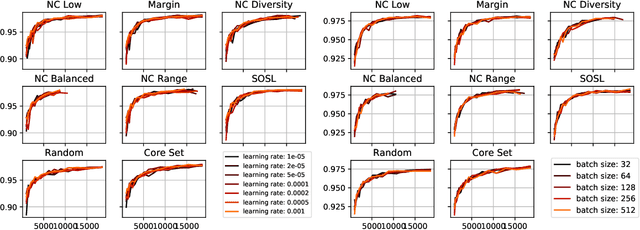
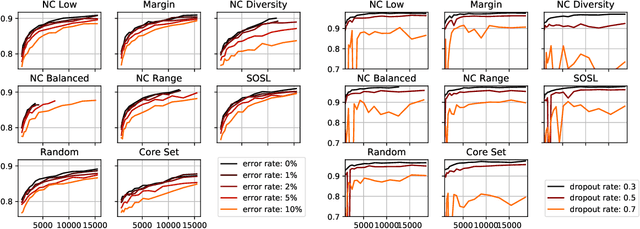
Active Learning is concerned with the question of how to identify the most useful samples for a Machine Learning algorithm to be trained with. When applied correctly, it can be a very powerful tool to counteract the immense data requirements of Artificial Neural Networks. However, we find that it is often applied with not enough care and domain knowledge. As a consequence, unrealistic hopes are raised and transfer of the experimental results from one dataset to another becomes unnecessarily hard. In this work we analyse the robustness of different Active Learning methods with respect to classifier capacity, exchangeability and type, as well as hyperparameters and falsely labelled data. Experiments reveal possible biases towards the architecture used for sample selection, resulting in suboptimal performance for other classifiers. We further propose the new "Sum of Squared Logits" method based on the Simpson diversity index and investigate the effect of using the confusion matrix for balancing in sample selection.
* 11 pages, 6 figures, 1 table; as published in the proceedings of the 5th Global Conference on Artificial Intelligence (GCAI), EPiC Series in Computing, Volume 65, pages 152-162, https://doi.org/10.29007/thws, 2019
Fast Object Classification and Meaningful Data Representation of Segmented Lidar Instances
Jun 17, 2020


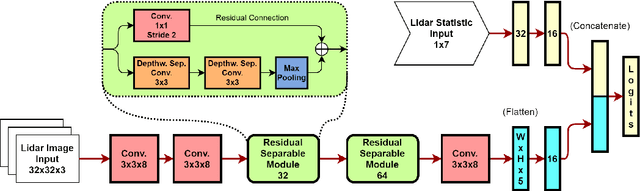
Object detection algorithms for Lidar data have seen numerous publications in recent years, reporting good results on dataset benchmarks oriented towards automotive requirements. Nevertheless, many of these are not deployable to embedded vehicle systems, as they require immense computational power to be executed close to real time. In this work, we propose a way to facilitate real-time Lidar object classification on CPU. We show how our approach uses segmented object instances to extract important features, enabling a computationally efficient batch-wise classification. For this, we introduce a data representation which translates three-dimensional information into small image patches, using decomposed normal vector images. We couple this with dedicated object statistics to handle edge cases. We apply our method on the tasks of object detection and semantic segmentation, as well as the relatively new challenge of panoptic segmentation. Through evaluation, we show, that our algorithm is capable of producing good results on public data, while running in real time on CPU without using specific optimisation.