 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Object Captioning for Street Scene Videos from LiDAR Tracks
May 22, 2025Video captioning models have seen notable advancements in recent years, especially with regard to their ability to capture temporal information. While many research efforts have focused on architectural advancements, such as temporal attention mechanisms, there remains a notable gap in understanding how models capture and utilize temporal semantics for effective temporal feature extraction, especially in the context of Advanced Driver Assistance Systems. We propose an automated LiDAR-based captioning procedure that focuses on the temporal dynamics of traffic participants. Our approach uses a rule-based system to extract essential details such as lane position and relative motion from object tracks, followed by a template-based caption generation. Our findings show that training SwinBERT, a video captioning model, using only front camera images and supervised with our template-based captions, specifically designed to encapsulate fine-grained temporal behavior, leads to improved temporal understanding consistently across three datasets. In conclusion, our results clearly demonstrate that integrating LiDAR-based caption supervision significantly enhances temporal understanding, effectively addressing and reducing the inherent visual/static biases prevalent in current state-of-the-art model architectures.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
On the Robustness of Active Learning
Jun 18, 2020
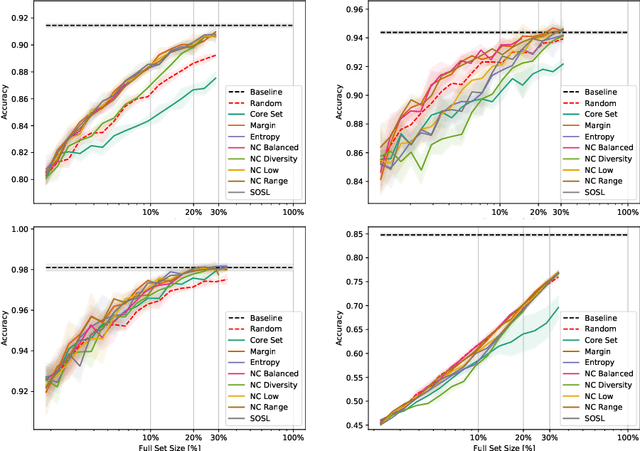
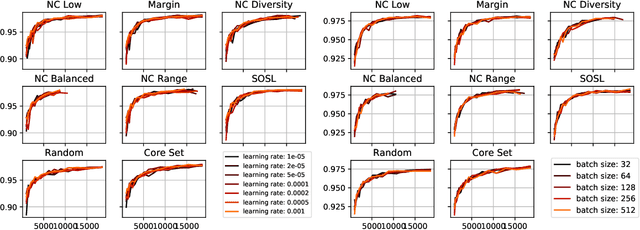
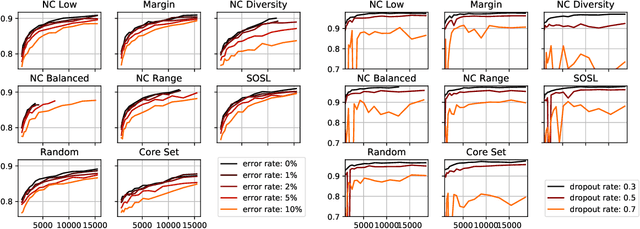
Active Learning is concerned with the question of how to identify the most useful samples for a Machine Learning algorithm to be trained with. When applied correctly, it can be a very powerful tool to counteract the immense data requirements of Artificial Neural Networks. However, we find that it is often applied with not enough care and domain knowledge. As a consequence, unrealistic hopes are raised and transfer of the experimental results from one dataset to another becomes unnecessarily hard. In this work we analyse the robustness of different Active Learning methods with respect to classifier capacity, exchangeability and type, as well as hyperparameters and falsely labelled data. Experiments reveal possible biases towards the architecture used for sample selection, resulting in suboptimal performance for other classifiers. We further propose the new "Sum of Squared Logits" method based on the Simpson diversity index and investigate the effect of using the confusion matrix for balancing in sample selection.
* 11 pages, 6 figures, 1 table; as published in the proceedings of the 5th Global Conference on Artificial Intelligence (GCAI), EPiC Series in Computing, Volume 65, pages 152-162, https://doi.org/10.29007/thws, 2019