 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Detect Label Errors by Making Them: A Method for Segmentation and Object Detection Datasets
Aug 25, 2025Recently, detection of label errors and improvement of label quality in datasets for supervised learning tasks has become an increasingly important goal in both research and industry. The consequences of incorrectly annotated data include reduced model performance, biased benchmark results, and lower overall accuracy. Current state-of-the-art label error detection methods often focus on a single computer vision task and, consequently, a specific type of dataset, containing, for example, either bounding boxes or pixel-wise annotations. Furthermore, previous methods are not learning-based. In this work, we overcome this research gap. We present a unified method for detecting label errors in object detection, semantic segmentation, and instance segmentation datasets. In a nutshell, our approach - learning to detect label errors by making them - works as follows: we inject different kinds of label errors into the ground truth. Then, the detection of label errors, across all mentioned primary tasks, is framed as an instance segmentation problem based on a composite input. In our experiments, we compare the label error detection performance of our method with various baselines and state-of-the-art approaches of each task's domain on simulated label errors across multiple tasks, datasets, and base models. This is complemented by a generalization study on real-world label errors. Additionally, we release 459 real label errors identified in the Cityscapes dataset and provide a benchmark for real label error detection in Cityscapes.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
LU-Net: Invertible Neural Networks Based on Matrix Factorization
Feb 21, 2023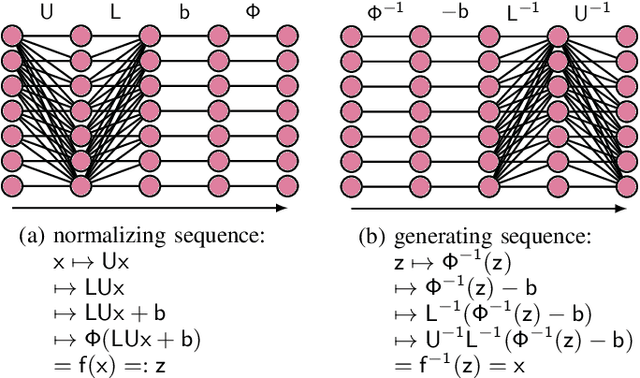
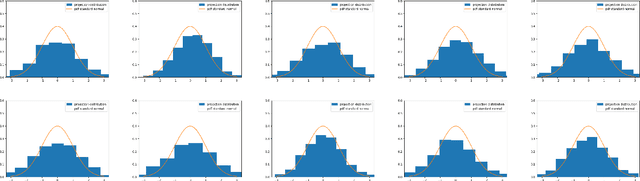
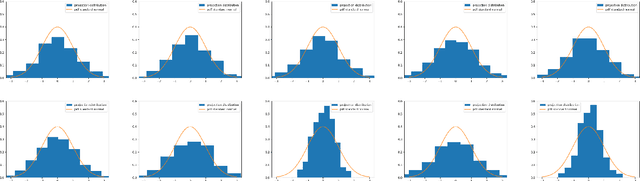
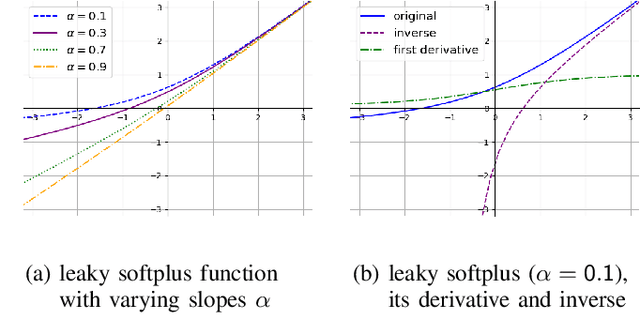
LU-Net is a simple and fast architecture for invertible neural networks (INN) that is based on the factorization of quadratic weight matrices $\mathsf{A=LU}$, where $\mathsf{L}$ is a lower triangular matrix with ones on the diagonal and $\mathsf{U}$ an upper triangular matrix. Instead of learning a fully occupied matrix $\mathsf{A}$, we learn $\mathsf{L}$ and $\mathsf{U}$ separately. If combined with an invertible activation function, such layers can easily be inverted whenever the diagonal entries of $\mathsf{U}$ are different from zero. Also, the computation of the determinant of the Jacobian matrix of such layers is cheap. Consequently, the LU architecture allows for cheap computation of the likelihood via the change of variables formula and can be trained according to the maximum likelihood principle. In our numerical experiments, we test the LU-net architecture as generative model on several academic datasets. We also provide a detailed comparison with conventional invertible neural networks in terms of performance, training as well as run time.