 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLFA applied to CNNs: Efficient Singular Value Decomposition of Convolutional Mappings by Local Fourier Analysis
Jun 05, 2025The singular values of convolutional mappings encode interesting spectral properties, which can be used, e.g., to improve generalization and robustness of convolutional neural networks as well as to facilitate model compression. However, the computation of singular values is typically very resource-intensive. The naive approach involves unrolling the convolutional mapping along the input and channel dimensions into a large and sparse two-dimensional matrix, making the exact calculation of all singular values infeasible due to hardware limitations. In particular, this is true for matrices that represent convolutional mappings with large inputs and a high number of channels. Existing efficient methods leverage the Fast Fourier transformation (FFT) to transform convolutional mappings into the frequency domain, enabling the computation of singular values for matrices representing convolutions with larger input and channel dimensions. For a constant number of channels in a given convolution, an FFT can compute N singular values in O(N log N) complexity. In this work, we propose an approach of complexity O(N) based on local Fourier analysis, which additionally exploits the shift invariance of convolutional operators. We provide a theoretical analysis of our algorithm's runtime and validate its efficiency through numerical experiments. Our results demonstrate that our proposed method is scalable and offers a practical solution to calculate the entire set of singular values - along with the corresponding singular vectors if needed - for high-dimensional convolutional mappings.
Poly-MgNet: Polynomial Building Blocks in Multigrid-Inspired ResNets
Mar 13, 2025The structural analogies of ResNets and Multigrid (MG) methods such as common building blocks like convolutions and poolings where already pointed out by He et al.\ in 2016. Multigrid methods are used in the context of scientific computing for solving large sparse linear systems arising from partial differential equations. MG methods particularly rely on two main concepts: smoothing and residual restriction / coarsening. Exploiting these analogies, He and Xu developed the MgNet framework, which integrates MG schemes into the design of ResNets. In this work, we introduce a novel neural network building block inspired by polynomial smoothers from MG theory. Our polynomial block from an MG perspective naturally extends the MgNet framework to Poly-Mgnet and at the same time reduces the number of weights in MgNet. We present a comprehensive study of our polynomial block, analyzing the choice of initial coefficients, the polynomial degree, the placement of activation functions, as well as of batch normalizations. Our results demonstrate that constructing (quadratic) polynomial building blocks based on real and imaginary polynomial roots enhances Poly-MgNet's capacity in terms of accuracy. Furthermore, our approach achieves an improved trade-off of model accuracy and number of weights compared to ResNet as well as compared to specific configurations of MgNet.
Reducing Texture Bias of Deep Neural Networks via Edge Enhancing Diffusion
Feb 14, 2024Convolutional neural networks (CNNs) for image processing tend to focus on localized texture patterns, commonly referred to as texture bias. While most of the previous works in the literature focus on the task of image classification, we go beyond this and study the texture bias of CNNs in semantic segmentation. In this work, we propose to train CNNs on pre-processed images with less texture to reduce the texture bias. Therein, the challenge is to suppress image texture while preserving shape information. To this end, we utilize edge enhancing diffusion (EED), an anisotropic image diffusion method initially introduced for image compression, to create texture reduced duplicates of existing datasets. Extensive numerical studies are performed with both CNNs and vision transformer models trained on original data and EED-processed data from the Cityscapes dataset and the CARLA driving simulator. We observe strong texture-dependence of CNNs and moderate texture-dependence of transformers. Training CNNs on EED-processed images enables the models to become completely ignorant with respect to texture, demonstrating resilience with respect to texture re-introduction to any degree. Additionally we analyze the performance reduction in depth on a level of connected components in the semantic segmentation and study the influence of EED pre-processing on domain generalization as well as adversarial robustness.
Deep Active Learning with Noisy Oracle in Object Detection
Sep 30, 2023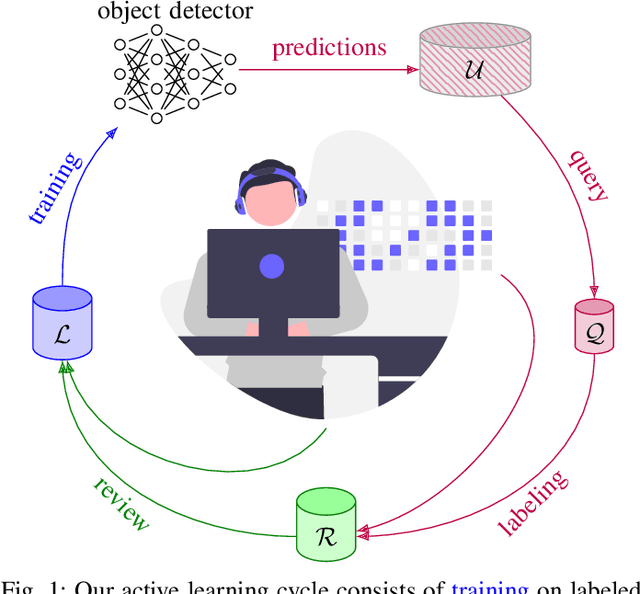


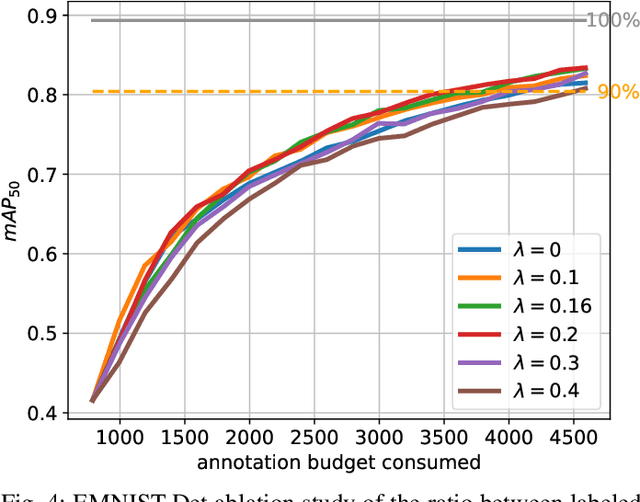
Obtaining annotations for complex computer vision tasks such as object detection is an expensive and time-intense endeavor involving a large number of human workers or expert opinions. Reducing the amount of annotations required while maintaining algorithm performance is, therefore, desirable for machine learning practitioners and has been successfully achieved by active learning algorithms. However, it is not merely the amount of annotations which influences model performance but also the annotation quality. In practice, the oracles that are queried for new annotations frequently contain significant amounts of noise. Therefore, cleansing procedures are oftentimes necessary to review and correct given labels. This process is subject to the same budget as the initial annotation itself since it requires human workers or even domain experts. Here, we propose a composite active learning framework including a label review module for deep object detection. We show that utilizing part of the annotation budget to correct the noisy annotations partially in the active dataset leads to early improvements in model performance, especially when coupled with uncertainty-based query strategies. The precision of the label error proposals has a significant influence on the measured effect of the label review. In our experiments we achieve improvements of up to 4.5 mAP points of object detection performance by incorporating label reviews at equal annotation budget.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
Identifying Label Errors in Object Detection Datasets by Loss Inspection
Mar 13, 2023
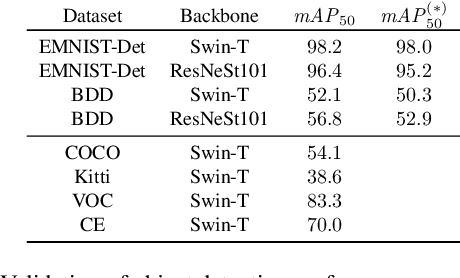
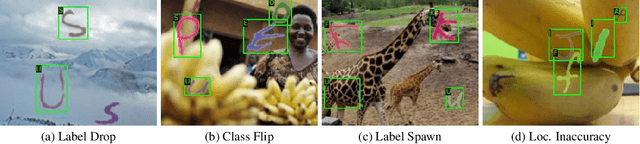
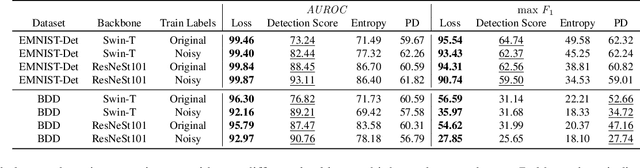
Labeling datasets for supervised object detection is a dull and time-consuming task. Errors can be easily introduced during annotation and overlooked during review, yielding inaccurate benchmarks and performance degradation of deep neural networks trained on noisy labels. In this work, we for the first time introduce a benchmark for label error detection methods on object detection datasets as well as a label error detection method and a number of baselines. We simulate four different types of randomly introduced label errors on train and test sets of well-labeled object detection datasets. For our label error detection method we assume a two-stage object detector to be given and consider the sum of both stages' classification and regression losses. The losses are computed with respect to the predictions and the noisy labels including simulated label errors, aiming at detecting the latter. We compare our method to three baselines: a naive one without deep learning, the object detector's score and the entropy of the classification softmax distribution. We outperform all baselines and demonstrate that among the considered methods, ours is the only one that detects label errors of all four types efficiently. Furthermore, we detect real label errors a) on commonly used test datasets in object detection and b) on a proprietary dataset. In both cases we achieve low false positives rates, i.e., when considering 200 proposals from our method, we detect label errors with a precision for a) of up to 71.5% and for b) with 97%.
Towards Rapid Prototyping and Comparability in Active Learning for Deep Object Detection
Dec 21, 2022



Active learning as a paradigm in deep learning is especially important in applications involving intricate perception tasks such as object detection where labels are difficult and expensive to acquire. Development of active learning methods in such fields is highly computationally expensive and time consuming which obstructs the progression of research and leads to a lack of comparability between methods. In this work, we propose and investigate a sandbox setup for rapid development and transparent evaluation of active learning in deep object detection. Our experiments with commonly used configurations of datasets and detection architectures found in the literature show that results obtained in our sandbox environment are representative of results on standard configurations. The total compute time to obtain results and assess the learning behavior can thereby be reduced by factors of up to 14 when comparing with Pascal VOC and up to 32 when comparing with BDD100k. This allows for testing and evaluating data acquisition and labeling strategies in under half a day and contributes to the transparency and development speed in the field of active learning for object detection.
MGiaD: Multigrid in all dimensions. Efficiency and robustness by coarsening in resolution and channel dimensions
Nov 10, 2022Current state-of-the-art deep neural networks for image classification are made up of 10 - 100 million learnable weights and are therefore inherently prone to overfitting. The complexity of the weight count can be seen as a function of the number of channels, the spatial extent of the input and the number of layers of the network. Due to the use of convolutional layers the scaling of weight complexity is usually linear with regards to the resolution dimensions, but remains quadratic with respect to the number of channels. Active research in recent years in terms of using multigrid inspired ideas in deep neural networks have shown that on one hand a significant number of weights can be saved by appropriate weight sharing and on the other that a hierarchical structure in the channel dimension can improve the weight complexity to linear. In this work, we combine these multigrid ideas to introduce a joint framework of multigrid inspired architectures, that exploit multigrid structures in all relevant dimensions to achieve linear weight complexity scaling and drastically reduced weight counts. Our experiments show that this structured reduction in weight count is able to reduce overfitting and thus shows improved performance over state-of-the-art ResNet architectures on typical image classification benchmarks at lower network complexity.
MetaDetect: Uncertainty Quantification and Prediction Quality Estimates for Object Detection
Oct 06, 2020



In object detection with deep neural networks, the box-wise objectness score tends to be overconfident, sometimes even indicating high confidence in presence of inaccurate predictions. Hence, the reliability of the prediction and therefore reliable uncertainties are of highest interest. In this work, we present a post processing method that for any given neural network provides predictive uncertainty estimates and quality estimates. These estimates are learned by a post processing model that receives as input a hand-crafted set of transparent metrics in form of a structured dataset. Therefrom, we learn two tasks for predicted bounding boxes. We discriminate between true positives ($\mathit{IoU}\geq0.5$) and false positives ($\mathit{IoU} < 0.5$) which we term meta classification, and we predict $\mathit{IoU}$ values directly which we term meta regression. The probabilities of the meta classification model aim at learning the probabilities of success and failure and therefore provide a modelled predictive uncertainty estimate. On the other hand, meta regression gives rise to a quality estimate. In numerical experiments, we use the publicly available YOLOv3 network and the Faster-RCNN network and evaluate meta classification and regression performance on the Kitti, Pascal VOC and COCO datasets. We demonstrate that our metrics are indeed well correlated with the $\mathit{IoU}$. For meta classification we obtain classification accuracies of up to 98.92% and AUROCs of up to 99.93%. For meta regression we obtain an $R^2$ value of up to 91.78%. These results yield significant improvements compared to other network's objectness score and other baseline approaches. Therefore, we obtain more reliable uncertainty and quality estimates which is particularly interesting in the absence of ground truth.
Deep Bayesian Active Semi-Supervised Learning
Mar 03, 2018


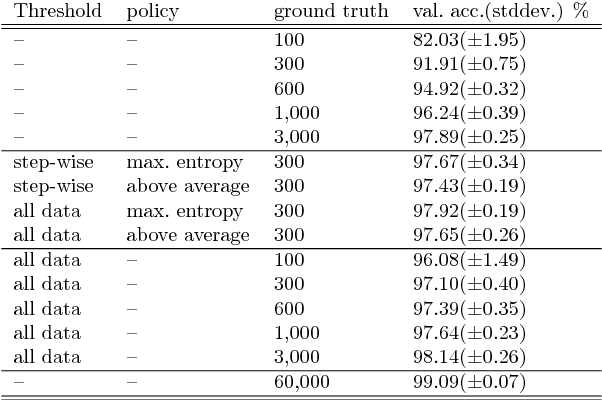
In many applications the process of generating label information is expensive and time consuming. We present a new method that combines active and semi-supervised deep learning to achieve high generalization performance from a deep convolutional neural network with as few known labels as possible. In a setting where a small amount of labeled data as well as a large amount of unlabeled data is available, our method first learns the labeled data set. This initialization is followed by an expectation maximization algorithm, where further training reduces classification entropy on the unlabeled data by targeting a low entropy fit which is consistent with the labeled data. In addition the algorithm asks at a specified frequency an oracle for labels of data with entropy above a certain entropy quantile. Using this active learning component we obtain an agile labeling process that achieves high accuracy, but requires only a small amount of known labels. For the MNIST dataset we report an error rate of 2.06% using only 300 labels and 1.06% for 1000 labels. These results are obtained without employing any special network architecture or data augmentation.