 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Bayesian Active Semi-Supervised Learning
Paper and Code



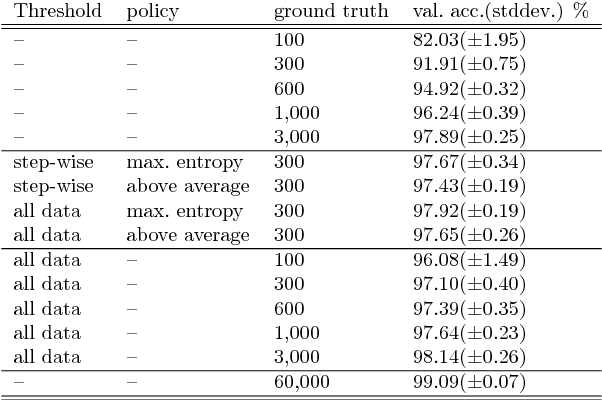
In many applications the process of generating label information is expensive and time consuming. We present a new method that combines active and semi-supervised deep learning to achieve high generalization performance from a deep convolutional neural network with as few known labels as possible. In a setting where a small amount of labeled data as well as a large amount of unlabeled data is available, our method first learns the labeled data set. This initialization is followed by an expectation maximization algorithm, where further training reduces classification entropy on the unlabeled data by targeting a low entropy fit which is consistent with the labeled data. In addition the algorithm asks at a specified frequency an oracle for labels of data with entropy above a certain entropy quantile. Using this active learning component we obtain an agile labeling process that achieves high accuracy, but requires only a small amount of known labels. For the MNIST dataset we report an error rate of 2.06% using only 300 labels and 1.06% for 1000 labels. These results are obtained without employing any special network architecture or data augmentation.