 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty estimates for semantic segmentation: providing enhanced reliability for automated motor claims handling
Jan 17, 2024Deep neural network models for image segmentation can be a powerful tool for the automation of motor claims handling processes in the insurance industry. A crucial aspect is the reliability of the model outputs when facing adverse conditions, such as low quality photos taken by claimants to document damages. We explore the use of a meta-classification model to assess the precision of segments predicted by a model trained for the semantic segmentation of car body parts. Different sets of features correlated with the quality of a segment are compared, and an AUROC score of 0.915 is achieved for distinguishing between high- and low-quality segments. By removing low-quality segments, the average mIoU of the segmentation output is improved by 16 percentage points and the number of wrongly predicted segments is reduced by 77%.
ResBuilder: Automated Learning of Depth with Residual Structures
Aug 16, 2023In this work, we develop a neural architecture search algorithm, termed Resbuilder, that develops ResNet architectures from scratch that achieve high accuracy at moderate computational cost. It can also be used to modify existing architectures and has the capability to remove and insert ResNet blocks, in this way searching for suitable architectures in the space of ResNet architectures. In our experiments on different image classification datasets, Resbuilder achieves close to state-of-the-art performance while saving computational cost compared to off-the-shelf ResNets. Noteworthy, we once tune the parameters on CIFAR10 which yields a suitable default choice for all other datasets. We demonstrate that this property generalizes even to industrial applications by applying our method with default parameters on a proprietary fraud detection dataset.
Identifying Label Errors in Object Detection Datasets by Loss Inspection
Mar 13, 2023
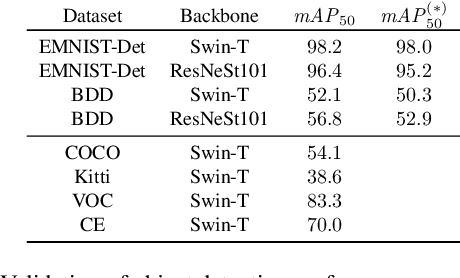
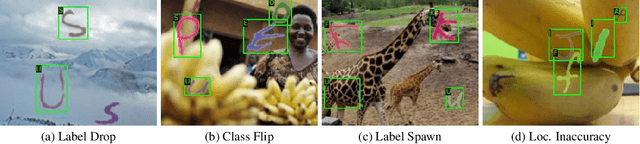
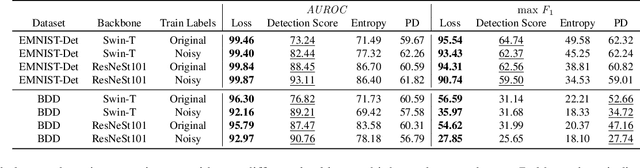
Labeling datasets for supervised object detection is a dull and time-consuming task. Errors can be easily introduced during annotation and overlooked during review, yielding inaccurate benchmarks and performance degradation of deep neural networks trained on noisy labels. In this work, we for the first time introduce a benchmark for label error detection methods on object detection datasets as well as a label error detection method and a number of baselines. We simulate four different types of randomly introduced label errors on train and test sets of well-labeled object detection datasets. For our label error detection method we assume a two-stage object detector to be given and consider the sum of both stages' classification and regression losses. The losses are computed with respect to the predictions and the noisy labels including simulated label errors, aiming at detecting the latter. We compare our method to three baselines: a naive one without deep learning, the object detector's score and the entropy of the classification softmax distribution. We outperform all baselines and demonstrate that among the considered methods, ours is the only one that detects label errors of all four types efficiently. Furthermore, we detect real label errors a) on commonly used test datasets in object detection and b) on a proprietary dataset. In both cases we achieve low false positives rates, i.e., when considering 200 proposals from our method, we detect label errors with a precision for a) of up to 71.5% and for b) with 97%.