 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Label Spreading: Efficient and Consistent Estimation of Soft Labels with Epistemic Uncertainty on Graphs
Feb 04, 2026Safe artificial intelligence for perception tasks remains a major challenge, partly due to the lack of data with high-quality labels. Annotations themselves are subject to aleatoric and epistemic uncertainty, which is typically ignored during annotation and evaluation. While crowdsourcing enables collecting multiple annotations per image to estimate these uncertainties, this approach is impractical at scale due to the required annotation effort. We introduce a probabilistic label spreading method that provides reliable estimates of aleatoric and epistemic uncertainty of labels. Assuming label smoothness over the feature space, we propagate single annotations using a graph-based diffusion method. We prove that label spreading yields consistent probability estimators even when the number of annotations per data point converges to zero. We present and analyze a scalable implementation of our method. Experimental results indicate that, compared to baselines, our approach substantially reduces the annotation budget required to achieve a desired label quality on common image datasets and achieves a new state of the art on the Data-Centric Image Classification benchmark.
Learning to Detect Label Errors by Making Them: A Method for Segmentation and Object Detection Datasets
Aug 25, 2025Recently, detection of label errors and improvement of label quality in datasets for supervised learning tasks has become an increasingly important goal in both research and industry. The consequences of incorrectly annotated data include reduced model performance, biased benchmark results, and lower overall accuracy. Current state-of-the-art label error detection methods often focus on a single computer vision task and, consequently, a specific type of dataset, containing, for example, either bounding boxes or pixel-wise annotations. Furthermore, previous methods are not learning-based. In this work, we overcome this research gap. We present a unified method for detecting label errors in object detection, semantic segmentation, and instance segmentation datasets. In a nutshell, our approach - learning to detect label errors by making them - works as follows: we inject different kinds of label errors into the ground truth. Then, the detection of label errors, across all mentioned primary tasks, is framed as an instance segmentation problem based on a composite input. In our experiments, we compare the label error detection performance of our method with various baselines and state-of-the-art approaches of each task's domain on simulated label errors across multiple tasks, datasets, and base models. This is complemented by a generalization study on real-world label errors. Additionally, we release 459 real label errors identified in the Cityscapes dataset and provide a benchmark for real label error detection in Cityscapes.
Deep Active Learning with Noisy Oracle in Object Detection
Sep 30, 2023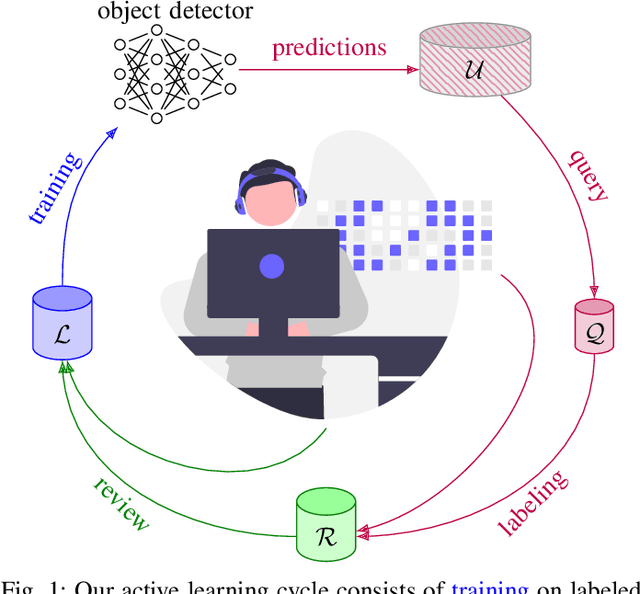


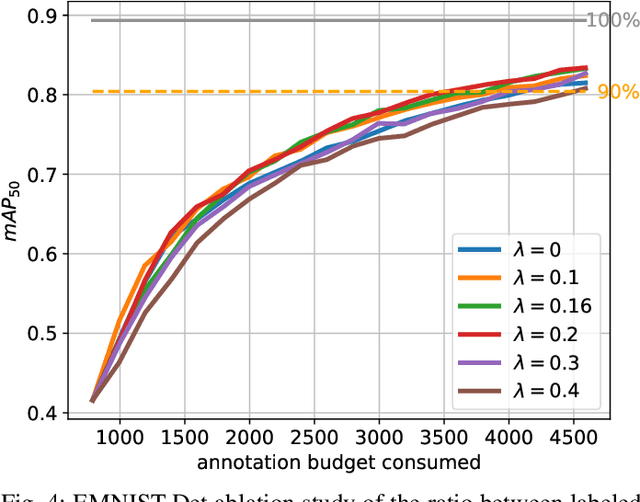
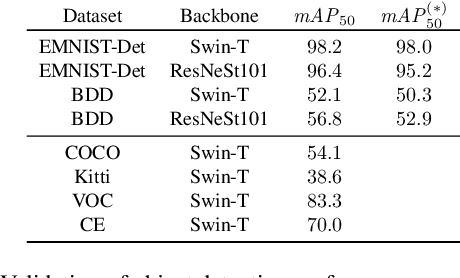
Obtaining annotations for complex computer vision tasks such as object detection is an expensive and time-intense endeavor involving a large number of human workers or expert opinions. Reducing the amount of annotations required while maintaining algorithm performance is, therefore, desirable for machine learning practitioners and has been successfully achieved by active learning algorithms. However, it is not merely the amount of annotations which influences model performance but also the annotation quality. In practice, the oracles that are queried for new annotations frequently contain significant amounts of noise. Therefore, cleansing procedures are oftentimes necessary to review and correct given labels. This process is subject to the same budget as the initial annotation itself since it requires human workers or even domain experts. Here, we propose a composite active learning framework including a label review module for deep object detection. We show that utilizing part of the annotation budget to correct the noisy annotations partially in the active dataset leads to early improvements in model performance, especially when coupled with uncertainty-based query strategies. The precision of the label error proposals has a significant influence on the measured effect of the label review. In our experiments we achieve improvements of up to 4.5 mAP points of object detection performance by incorporating label reviews at equal annotation budget.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
Pixel-wise Gradient Uncertainty for Convolutional Neural Networks applied to Out-of-Distribution Segmentation
Mar 13, 2023



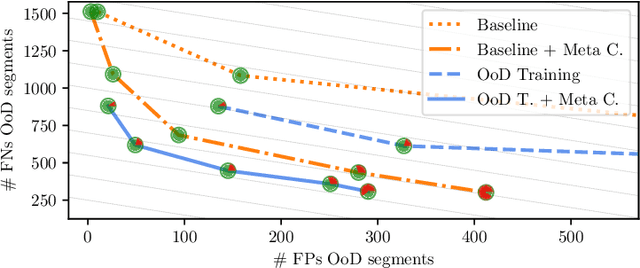
In recent years, deep neural networks have defined the state-of-the-art in semantic segmentation where their predictions are constrained to a predefined set of semantic classes. They are to be deployed in applications such as automated driving, although their categorically confined expressive power runs contrary to such open world scenarios. Thus, the detection and segmentation of objects from outside their predefined semantic space, i.e., out-of-distribution (OoD) objects, is of highest interest. Since uncertainty estimation methods like softmax entropy or Bayesian models are sensitive to erroneous predictions, these methods are a natural baseline for OoD detection. Here, we present a method for obtaining uncertainty scores from pixel-wise loss gradients which can be computed efficiently during inference. Our approach is simple to implement for a large class of models, does not require any additional training or auxiliary data and can be readily used on pre-trained segmentation models. Our experiments show the ability of our method to identify wrong pixel classifications and to estimate prediction quality. In particular, we observe superior performance in terms of OoD segmentation to comparable baselines on the SegmentMeIfYouCan benchmark, clearly outperforming methods which are similarly flexible to implement.
Identifying Label Errors in Object Detection Datasets by Loss Inspection
Mar 13, 2023
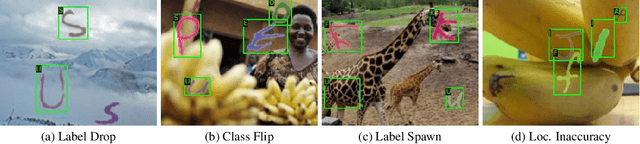
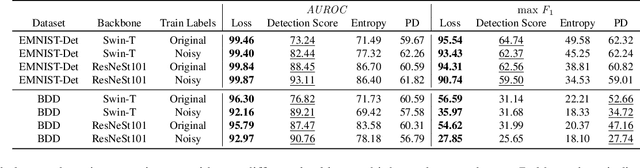
Labeling datasets for supervised object detection is a dull and time-consuming task. Errors can be easily introduced during annotation and overlooked during review, yielding inaccurate benchmarks and performance degradation of deep neural networks trained on noisy labels. In this work, we for the first time introduce a benchmark for label error detection methods on object detection datasets as well as a label error detection method and a number of baselines. We simulate four different types of randomly introduced label errors on train and test sets of well-labeled object detection datasets. For our label error detection method we assume a two-stage object detector to be given and consider the sum of both stages' classification and regression losses. The losses are computed with respect to the predictions and the noisy labels including simulated label errors, aiming at detecting the latter. We compare our method to three baselines: a naive one without deep learning, the object detector's score and the entropy of the classification softmax distribution. We outperform all baselines and demonstrate that among the considered methods, ours is the only one that detects label errors of all four types efficiently. Furthermore, we detect real label errors a) on commonly used test datasets in object detection and b) on a proprietary dataset. In both cases we achieve low false positives rates, i.e., when considering 200 proposals from our method, we detect label errors with a precision for a) of up to 71.5% and for b) with 97%.
Towards Rapid Prototyping and Comparability in Active Learning for Deep Object Detection
Dec 21, 2022



Active learning as a paradigm in deep learning is especially important in applications involving intricate perception tasks such as object detection where labels are difficult and expensive to acquire. Development of active learning methods in such fields is highly computationally expensive and time consuming which obstructs the progression of research and leads to a lack of comparability between methods. In this work, we propose and investigate a sandbox setup for rapid development and transparent evaluation of active learning in deep object detection. Our experiments with commonly used configurations of datasets and detection architectures found in the literature show that results obtained in our sandbox environment are representative of results on standard configurations. The total compute time to obtain results and assess the learning behavior can thereby be reduced by factors of up to 14 when comparing with Pascal VOC and up to 32 when comparing with BDD100k. This allows for testing and evaluating data acquisition and labeling strategies in under half a day and contributes to the transparency and development speed in the field of active learning for object detection.
Uncertainty Quantification and Resource-Demanding Computer Vision Applications of Deep Learning
May 30, 2022

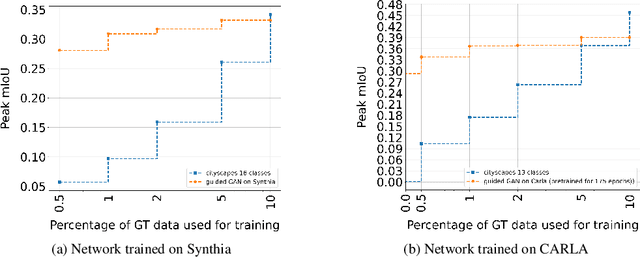
Bringing deep neural networks (DNNs) into safety critical applications such as automated driving, medical imaging and finance, requires a thorough treatment of the model's uncertainties. Training deep neural networks is already resource demanding and so is also their uncertainty quantification. In this overview article, we survey methods that we developed to teach DNNs to be uncertain when they encounter new object classes. Additionally, we present training methods to learn from only a few labels with help of uncertainty quantification. Note that this is typically paid with a massive overhead in computation of an order of magnitude and more compared to ordinary network training. Finally, we survey our work on neural architecture search which is also an order of magnitude more resource demanding then ordinary network training.
Gradient-Based Quantification of Epistemic Uncertainty for Deep Object Detectors
Jul 09, 2021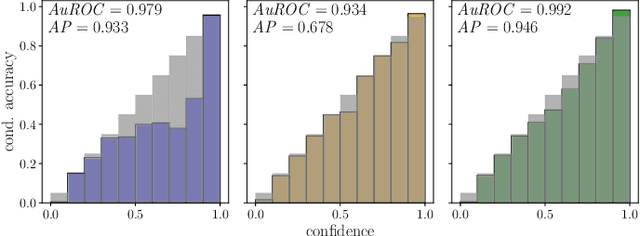
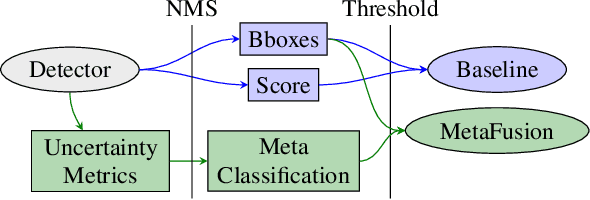
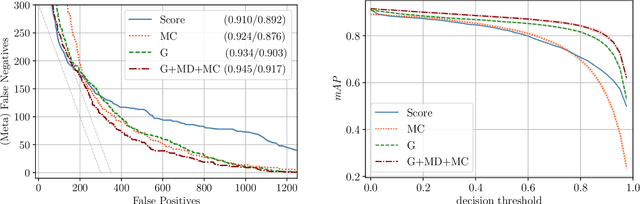
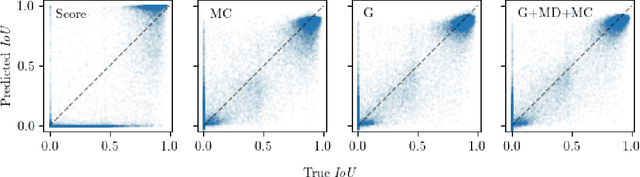
Reliable epistemic uncertainty estimation is an essential component for backend applications of deep object detectors in safety-critical environments. Modern network architectures tend to give poorly calibrated confidences with limited predictive power. Here, we introduce novel gradient-based uncertainty metrics and investigate them for different object detection architectures. Experiments on the MS COCO, PASCAL VOC and the KITTI dataset show significant improvements in true positive / false positive discrimination and prediction of intersection over union as compared to network confidence. We also find improvement over Monte-Carlo dropout uncertainty metrics and further significant boosts by aggregating different sources of uncertainty metrics.The resulting uncertainty models generate well-calibrated confidences in all instances. Furthermore, we implement our uncertainty quantification models into object detection pipelines as a means to discern true against false predictions, replacing the ordinary score-threshold-based decision rule. In our experiments, we achieve a significant boost in detection performance in terms of mean average precision. With respect to computational complexity, we find that computing gradient uncertainty metrics results in floating point operation counts similar to those of Monte-Carlo dropout.