 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Driving Maps by Deep Learning-based Trail Map Extraction
May 15, 2025High-definition (HD) maps offer extensive and accurate environmental information about the driving scene, making them a crucial and essential element for planning within autonomous driving systems. To avoid extensive efforts from manual labeling, methods for automating the map creation have emerged. Recent trends have moved from offline mapping to online mapping, ensuring availability and actuality of the utilized maps. While the performance has increased in recent years, online mapping still faces challenges regarding temporal consistency, sensor occlusion, runtime, and generalization. We propose a novel offline mapping approach that integrates trails - informal routes used by drivers - into the map creation process. Our method aggregates trail data from the ego vehicle and other traffic participants to construct a comprehensive global map using transformer-based deep learning models. Unlike traditional offline mapping, our approach enables continuous updates while remaining sensor-agnostic, facilitating efficient data transfer. Our method demonstrates superior performance compared to state-of-the-art online mapping approaches, achieving improved generalization to previously unseen environments and sensor configurations. We validate our approach on two benchmark datasets, highlighting its robustness and applicability in autonomous driving systems.
Adverse Weather Conditions Augmentation of LiDAR Scenes with Latent Diffusion Models
Jan 03, 2025LiDAR scenes constitute a fundamental source for several autonomous driving applications. Despite the existence of several datasets, scenes from adverse weather conditions are rarely available. This limits the robustness of downstream machine learning models, and restrains the reliability of autonomous driving systems in particular locations and seasons. Collecting feature-diverse scenes under adverse weather conditions is challenging due to seasonal limitations. Generative models are therefore essentials, especially for generating adverse weather conditions for specific driving scenarios. In our work, we propose a latent diffusion process constituted by autoencoder and latent diffusion models. Moreover, we leverage the clear condition LiDAR scenes with a postprocessing step to improve the realism of the generated adverse weather condition scenes.
A Preprocessing and Postprocessing Voxel-based Method for LiDAR Semantic Segmentation Improvement in Long Distance
May 16, 2024In recent years considerable research in LiDAR semantic segmentation was conducted, introducing several new state of the art models. However, most research focuses on single-scan point clouds, limiting performance especially in long distance outdoor scenarios, by omitting time-sequential information. Moreover, varying-density and occlusions constitute significant challenges in single-scan approaches. In this paper we propose a LiDAR point cloud preprocessing and postprocessing method. This multi-stage approach, in conjunction with state of the art models in a multi-scan setting, aims to solve those challenges. We demonstrate the benefits of our method through quantitative evaluation with the given models in single-scan settings. In particular, we achieve significant improvements in mIoU performance of over 5 percentage point in medium range and over 10 percentage point in far range. This is essential for 3D semantic scene understanding in long distance as well as for applications where offline processing is permissible.
LMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
Fake it, Mix it, Segment it: Bridging the Domain Gap Between Lidar Sensors
Dec 19, 2022


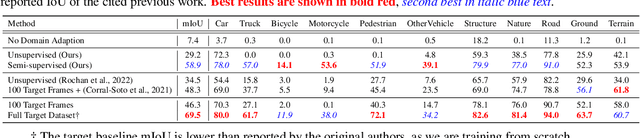
Segmentation of lidar data is a task that provides rich, point-wise information about the environment of robots or autonomous vehicles. Currently best performing neural networks for lidar segmentation are fine-tuned to specific datasets. Switching the lidar sensor without retraining on a big set of annotated data from the new sensor creates a domain shift, which causes the network performance to drop drastically. In this work we propose a new method for lidar domain adaption, in which we use annotated panoptic lidar datasets and recreate the recorded scenes in the structure of a different lidar sensor. We narrow the domain gap to the target data by recreating panoptic data from one domain in another and mixing the generated data with parts of (pseudo) labeled target domain data. Our method improves the nuScenes to SemanticKITTI unsupervised domain adaptation performance by 15.2 mean Intersection over Union points (mIoU) and by 48.3 mIoU in our semi-supervised approach. We demonstrate a similar improvement for the SemanticKITTI to nuScenes domain adaptation by 21.8 mIoU and 51.5 mIoU, respectively. We compare our method with two state of the art approaches for semantic lidar segmentation domain adaptation with a significant improvement for unsupervised and semi-supervised domain adaptation. Furthermore we successfully apply our proposed method to two entirely unlabeled datasets of two state of the art lidar sensors Velodyne Alpha Prime and InnovizTwo, and train well performing semantic segmentation networks for both.
False Positive Detection and Prediction Quality Estimation for LiDAR Point Cloud Segmentation
Oct 29, 2021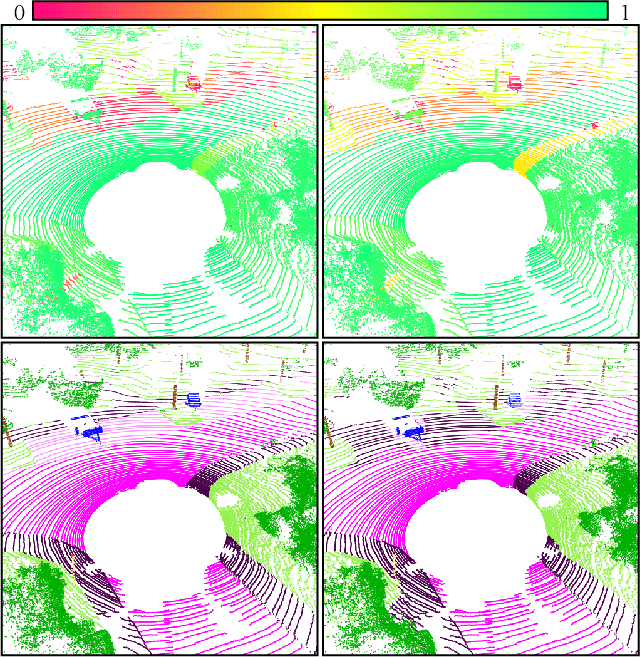
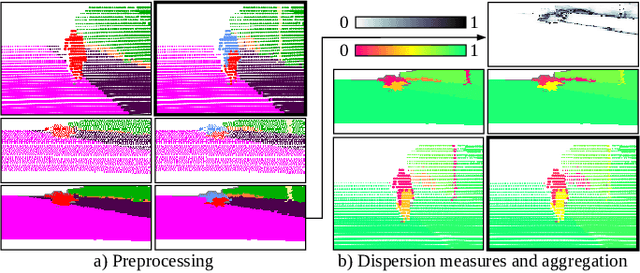
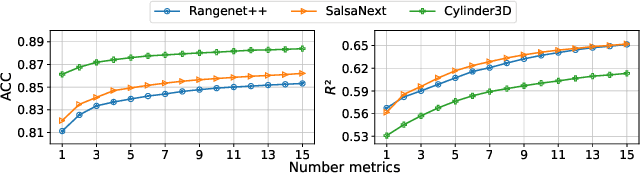
We present a novel post-processing tool for semantic segmentation of LiDAR point cloud data, called LidarMetaSeg, which estimates the prediction quality segmentwise. For this purpose we compute dispersion measures based on network probability outputs as well as feature measures based on point cloud input features and aggregate them on segment level. These aggregated measures are used to train a meta classification model to predict whether a predicted segment is a false positive or not and a meta regression model to predict the segmentwise intersection over union. Both models can then be applied to semantic segmentation inferences without knowing the ground truth. In our experiments we use different LiDAR segmentation models and datasets and analyze the power of our method. We show that our results outperform other standard approaches.
MetaBox+: A new Region Based Active Learning Method for Semantic Segmentation using Priority Maps
Oct 05, 2020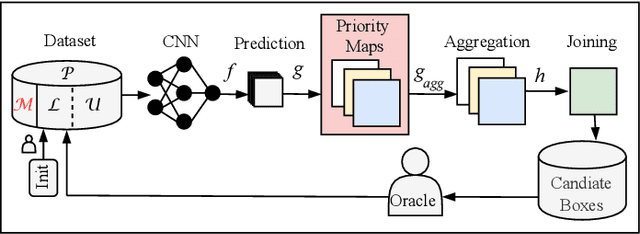
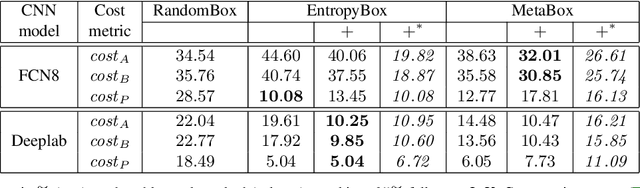
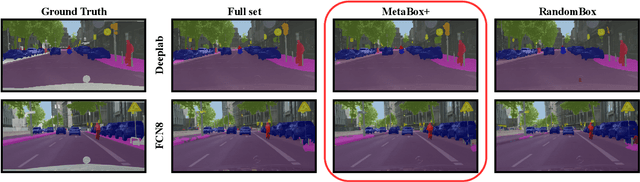
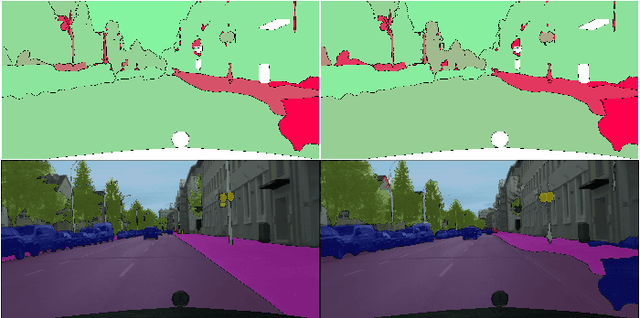
We present a novel region based active learning method for semantic image segmentation, called MetaBox+. For acquisition, we train a meta regression model to estimate the segment-wise Intersection over Union (IoU) of each predicted segment of unlabeled images. This can be understood as an estimation of segment-wise prediction quality. Queried regions are supposed to minimize to competing targets, i.e., low predicted IoU values / segmentation quality and low estimated annotation costs. For estimating the latter we propose a simple but practical method for annotation cost estimation. We compare our method to entropy based methods, where we consider the entropy as uncertainty of the prediction. The comparison and analysis of the results provide insights into annotation costs as well as robustness and variance of the methods. Numerical experiments conducted with two different networks on the Cityscapes dataset clearly demonstrate a reduction of annotation effort compared to random acquisition. Noteworthily, we achieve 95%of the mean Intersection over Union (mIoU), using MetaBox+ compared to when training with the full dataset, with only 10.47% / 32.01% annotation effort for the two networks, respectively.
Prediction Error Meta Classification in Semantic Segmentation: Detection via Aggregated Dispersion Measures of Softmax Probabilities
Nov 01, 2018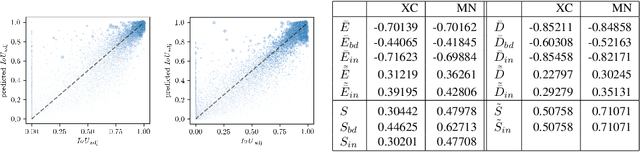
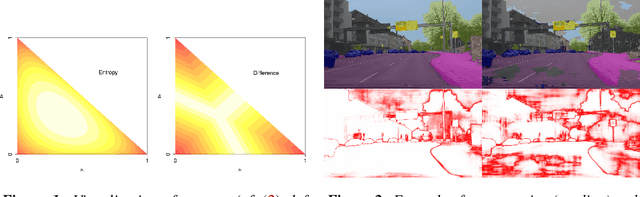
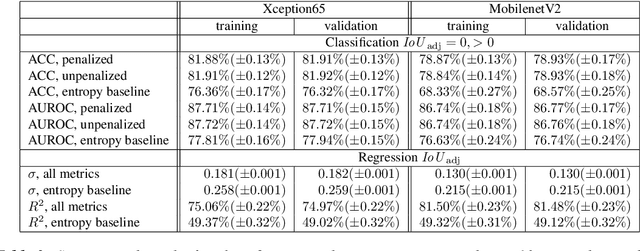
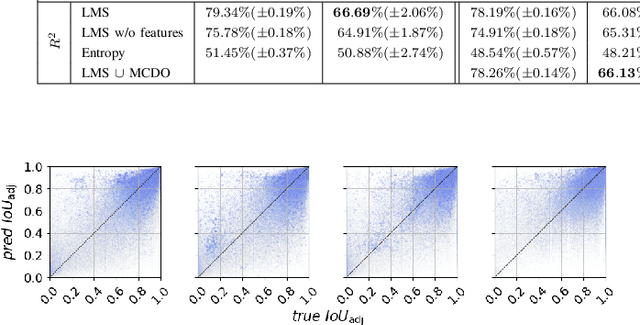
We present a method that "meta" classifies whether segments (objects) predicted by a semantic segmentation neural network intersect with the ground truth. To this end, we employ measures of dispersion for predicted pixel-wise class probability distributions, like classification entropy, that yield heat maps of the input scene's size. We aggregate these dispersion measures segment-wise and derive metrics that are well-correlated with the segment-wise $\mathit{IoU}$ of prediction and ground truth. In our tests, we use two publicly available DeepLabv3+ networks (pre-trained on the Cityscapes data set) and analyze the predictive power of different metrics and different sets of metrics. To this end, we compute logistic LASSO regression fits for the task of classifying $\mathit{IoU}=0$ vs. $\mathit{IoU} > 0$ per segment and obtain classification rates of up to $81.91\%$ and AUROC values of up to $87.71\%$ without the incorporation of advanced techniques like Monte-Carlo dropout. We complement these tests with linear regression fits to predict the segment-wise $\mathit{IoU}$ and obtain prediction standard deviations of down to $0.130$ as well as $R^2$ values of up to $81.48\%$. We show that these results clearly outperform single-metric baseline approaches.