 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMD: Light-weight Prediction Quality Estimation for Object Detection in Lidar Point Clouds
Jun 15, 2023Object detection on Lidar point cloud data is a promising technology for autonomous driving and robotics which has seen a significant rise in performance and accuracy during recent years. Particularly uncertainty estimation is a crucial component for down-stream tasks and deep neural networks remain error-prone even for predictions with high confidence. Previously proposed methods for quantifying prediction uncertainty tend to alter the training scheme of the detector or rely on prediction sampling which results in vastly increased inference time. In order to address these two issues, we propose LidarMetaDetect (LMD), a light-weight post-processing scheme for prediction quality estimation. Our method can easily be added to any pre-trained Lidar object detector without altering anything about the base model and is purely based on post-processing, therefore, only leading to a negligible computational overhead. Our experiments show a significant increase of statistical reliability in separating true from false predictions. We propose and evaluate an additional application of our method leading to the detection of annotation errors. Explicit samples and a conservative count of annotation error proposals indicates the viability of our method for large-scale datasets like KITTI and nuScenes. On the widely-used nuScenes test dataset, 43 out of the top 100 proposals of our method indicate, in fact, erroneous annotations.
False Positive Detection and Prediction Quality Estimation for LiDAR Point Cloud Segmentation
Oct 29, 2021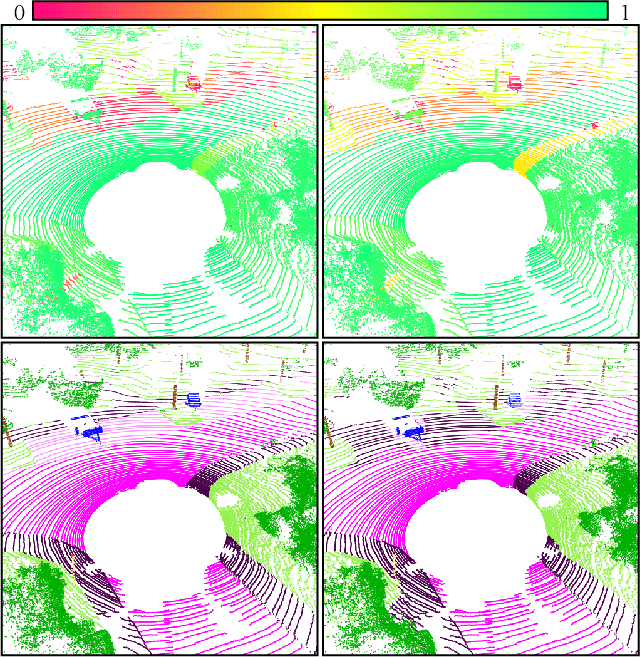
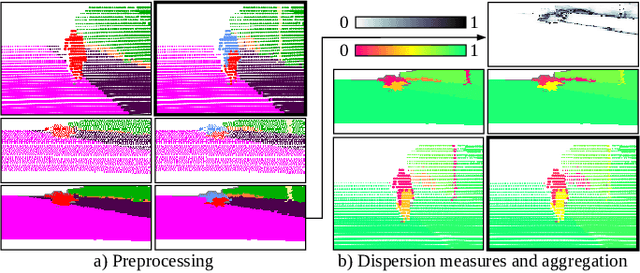
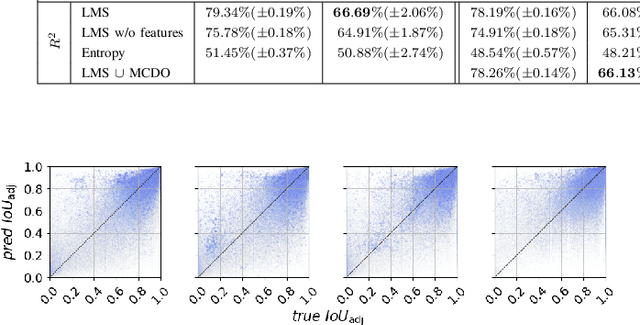
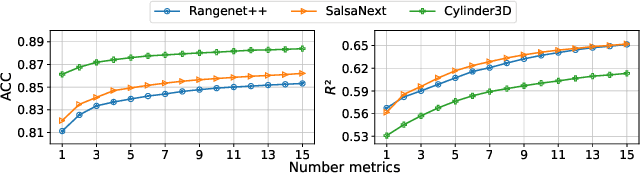
We present a novel post-processing tool for semantic segmentation of LiDAR point cloud data, called LidarMetaSeg, which estimates the prediction quality segmentwise. For this purpose we compute dispersion measures based on network probability outputs as well as feature measures based on point cloud input features and aggregate them on segment level. These aggregated measures are used to train a meta classification model to predict whether a predicted segment is a false positive or not and a meta regression model to predict the segmentwise intersection over union. Both models can then be applied to semantic segmentation inferences without knowing the ground truth. In our experiments we use different LiDAR segmentation models and datasets and analyze the power of our method. We show that our results outperform other standard approaches.
MetaBox+: A new Region Based Active Learning Method for Semantic Segmentation using Priority Maps
Oct 05, 2020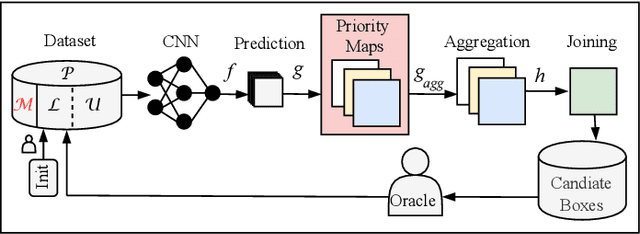
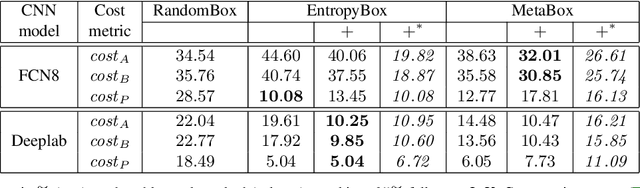
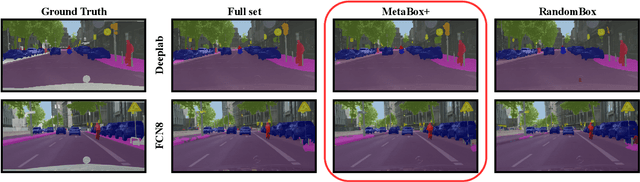
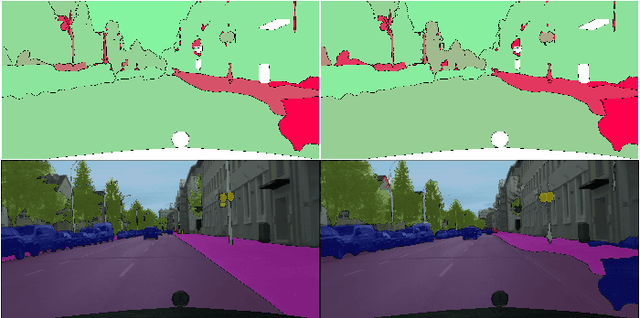
We present a novel region based active learning method for semantic image segmentation, called MetaBox+. For acquisition, we train a meta regression model to estimate the segment-wise Intersection over Union (IoU) of each predicted segment of unlabeled images. This can be understood as an estimation of segment-wise prediction quality. Queried regions are supposed to minimize to competing targets, i.e., low predicted IoU values / segmentation quality and low estimated annotation costs. For estimating the latter we propose a simple but practical method for annotation cost estimation. We compare our method to entropy based methods, where we consider the entropy as uncertainty of the prediction. The comparison and analysis of the results provide insights into annotation costs as well as robustness and variance of the methods. Numerical experiments conducted with two different networks on the Cityscapes dataset clearly demonstrate a reduction of annotation effort compared to random acquisition. Noteworthily, we achieve 95%of the mean Intersection over Union (mIoU), using MetaBox+ compared to when training with the full dataset, with only 10.47% / 32.01% annotation effort for the two networks, respectively.
On the Robustness of Active Learning
Jun 18, 2020
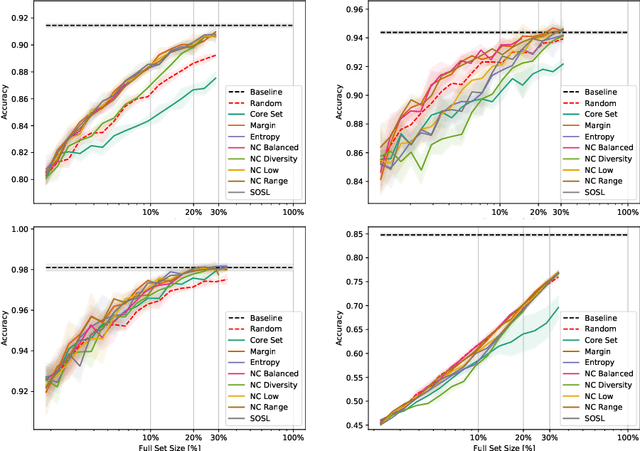
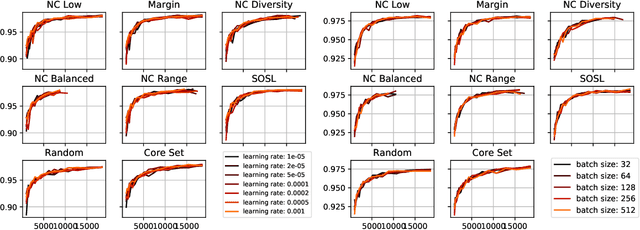
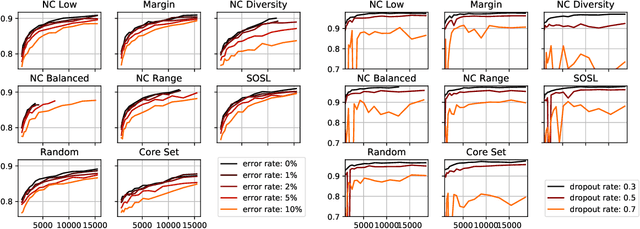
Active Learning is concerned with the question of how to identify the most useful samples for a Machine Learning algorithm to be trained with. When applied correctly, it can be a very powerful tool to counteract the immense data requirements of Artificial Neural Networks. However, we find that it is often applied with not enough care and domain knowledge. As a consequence, unrealistic hopes are raised and transfer of the experimental results from one dataset to another becomes unnecessarily hard. In this work we analyse the robustness of different Active Learning methods with respect to classifier capacity, exchangeability and type, as well as hyperparameters and falsely labelled data. Experiments reveal possible biases towards the architecture used for sample selection, resulting in suboptimal performance for other classifiers. We further propose the new "Sum of Squared Logits" method based on the Simpson diversity index and investigate the effect of using the confusion matrix for balancing in sample selection.
* 11 pages, 6 figures, 1 table; as published in the proceedings of the 5th Global Conference on Artificial Intelligence (GCAI), EPiC Series in Computing, Volume 65, pages 152-162, https://doi.org/10.29007/thws, 2019
Fast and Reliable Architecture Selection for Convolutional Neural Networks
May 06, 2019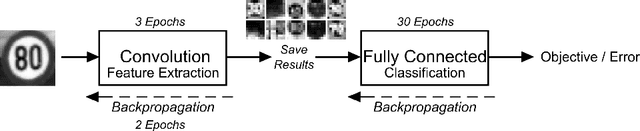


The performance of a Convolutional Neural Network (CNN) depends on its hyperparameters, like the number of layers, kernel sizes, or the learning rate for example. Especially in smaller networks and applications with limited computational resources, optimisation is key. We present a fast and efficient approach for CNN architecture selection. Taking into account time consumption, precision and robustness, we develop a heuristic to quickly and reliably assess a network's performance. In combination with Bayesian optimisation (BO), to effectively cover the vast parameter space, our contribution offers a plain and powerful architecture search for this machine learning technique.
* As published in the proceedings of the 27th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), pages 179-184, Bruges 2019. 6 pages, 2 figures, 1 table
EffNet: An Efficient Structure for Convolutional Neural Networks
Jun 05, 2018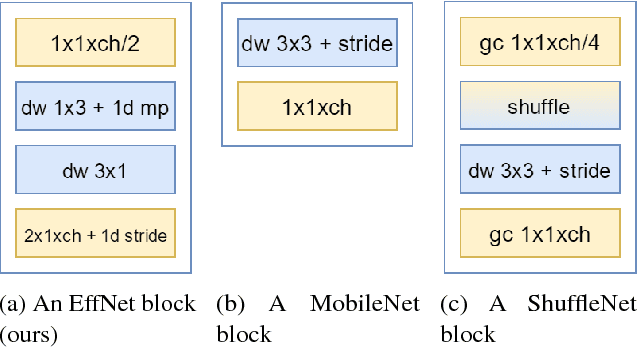
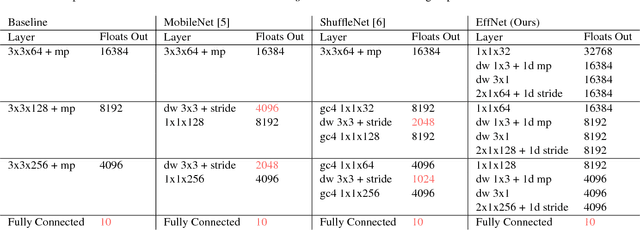
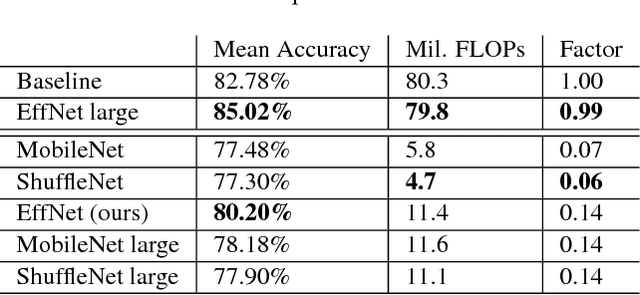
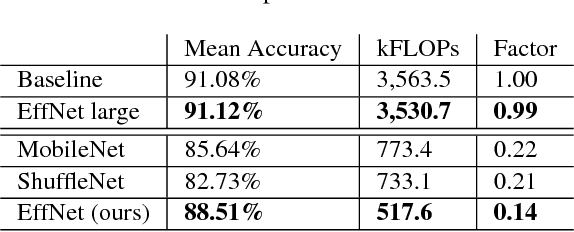
With the ever increasing application of Convolutional Neural Networks to customer products the need emerges for models to efficiently run on embedded, mobile hardware. Slimmer models have therefore become a hot research topic with various approaches which vary from binary networks to revised convolution layers. We offer our contribution to the latter and propose a novel convolution block which significantly reduces the computational burden while surpassing the current state-of-the-art. Our model, dubbed EffNet, is optimised for models which are slim to begin with and is created to tackle issues in existing models such as MobileNet and ShuffleNet.