 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipal Component Clustering for Semantic Segmentation in Synthetic Data Generation
Jun 25, 2024



This technical report outlines our method for generating a synthetic dataset for semantic segmentation using a latent diffusion model. Our approach eliminates the need for additional models specifically trained on segmentation data and is part of our submission to the CVPR 2024 workshop challenge, entitled CVPR 2024 workshop challenge "SyntaGen Harnessing Generative Models for Synthetic Visual Datasets". Our methodology uses self-attentions to facilitate a novel head-wise semantic information condensation, thereby enabling the direct acquisition of class-agnostic image segmentation from the Stable Diffusion latents. Furthermore, we employ non-prompt-influencing cross-attentions from text to pixel, thus facilitating the classification of the previously generated masks. Finally, we propose a mask refinement step by using only the output image by Stable Diffusion.
Fake it, Mix it, Segment it: Bridging the Domain Gap Between Lidar Sensors
Dec 19, 2022


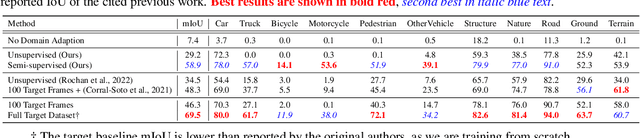
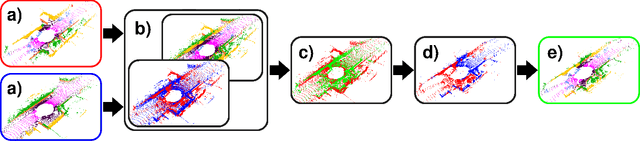
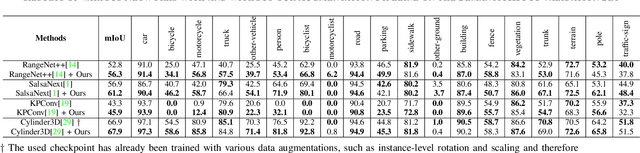
Segmentation of lidar data is a task that provides rich, point-wise information about the environment of robots or autonomous vehicles. Currently best performing neural networks for lidar segmentation are fine-tuned to specific datasets. Switching the lidar sensor without retraining on a big set of annotated data from the new sensor creates a domain shift, which causes the network performance to drop drastically. In this work we propose a new method for lidar domain adaption, in which we use annotated panoptic lidar datasets and recreate the recorded scenes in the structure of a different lidar sensor. We narrow the domain gap to the target data by recreating panoptic data from one domain in another and mixing the generated data with parts of (pseudo) labeled target domain data. Our method improves the nuScenes to SemanticKITTI unsupervised domain adaptation performance by 15.2 mean Intersection over Union points (mIoU) and by 48.3 mIoU in our semi-supervised approach. We demonstrate a similar improvement for the SemanticKITTI to nuScenes domain adaptation by 21.8 mIoU and 51.5 mIoU, respectively. We compare our method with two state of the art approaches for semantic lidar segmentation domain adaptation with a significant improvement for unsupervised and semi-supervised domain adaptation. Furthermore we successfully apply our proposed method to two entirely unlabeled datasets of two state of the art lidar sensors Velodyne Alpha Prime and InnovizTwo, and train well performing semantic segmentation networks for both.
What Can be Seen is What You Get: Structure Aware Point Cloud Augmentation
Jun 20, 2022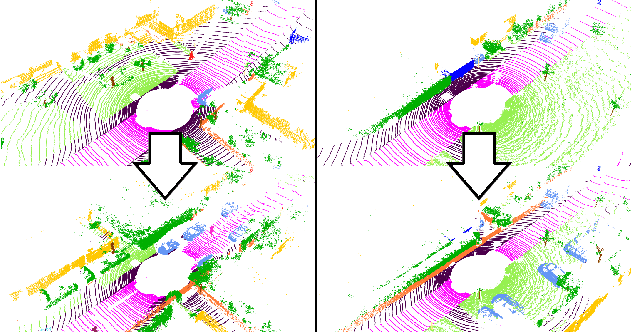
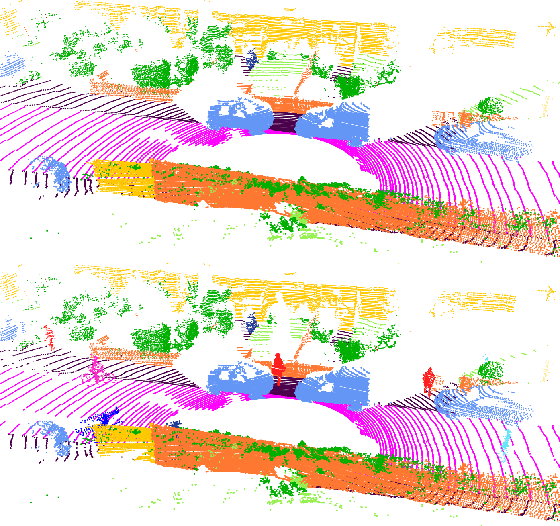
To train a well performing neural network for semantic segmentation, it is crucial to have a large dataset with available ground truth for the network to generalize on unseen data. In this paper we present novel point cloud augmentation methods to artificially diversify a dataset. Our sensor-centric methods keep the data structure consistent with the lidar sensor capabilities. Due to these new methods, we are able to enrich low-value data with high-value instances, as well as create entirely new scenes. We validate our methods on multiple neural networks with the public SemanticKITTI dataset and demonstrate that all networks improve compared to their respective baseline. In addition, we show that our methods enable the use of very small datasets, saving annotation time, training time and the associated costs.
* Published in IEEE IV 2022
Fast Object Classification and Meaningful Data Representation of Segmented Lidar Instances
Jun 17, 2020


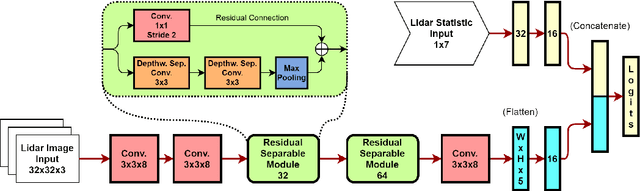
Object detection algorithms for Lidar data have seen numerous publications in recent years, reporting good results on dataset benchmarks oriented towards automotive requirements. Nevertheless, many of these are not deployable to embedded vehicle systems, as they require immense computational power to be executed close to real time. In this work, we propose a way to facilitate real-time Lidar object classification on CPU. We show how our approach uses segmented object instances to extract important features, enabling a computationally efficient batch-wise classification. For this, we introduce a data representation which translates three-dimensional information into small image patches, using decomposed normal vector images. We couple this with dedicated object statistics to handle edge cases. We apply our method on the tasks of object detection and semantic segmentation, as well as the relatively new challenge of panoptic segmentation. Through evaluation, we show, that our algorithm is capable of producing good results on public data, while running in real time on CPU without using specific optimisation.
Fast Lidar Clustering by Density and Connectivity
Mar 01, 2020

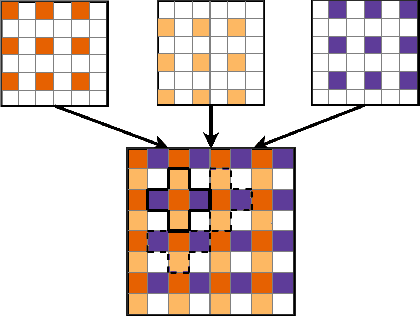

Lidar sensors are widely used in various applications, ranging from scientific fields over industrial use to integration in consumer products. With an ever growing number of different driver assistance systems, they have been introduced to automotive series production in recent years and are considered an important building block for the practical realisation of autonomous driving. However, due to the potentially large amount of Lidar points per scan, tailored algorithms are required to identify objects (e.g. pedestrians or vehicles) with high precision in a very short time. In this work, we propose an algorithmic approach for real-time instance segmentation of Lidar sensor data. We show how our method leverages the properties of the Euclidean distance to retain three-dimensional measurement information, while being narrowed down to a two-dimensional representation for fast computation. We further introduce what we call skip connections, to make our approach robust against over-segmentation and improve assignment in cases of partial occlusion. Through detailed evaluation on public data and comparison with established methods, we show how these aspects enable state-of-the-art performance and runtime on a single CPU core.