 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Person-to-Person Virtual Try-On with Multi-Garment Virtual Try-Off
Apr 17, 2025Computer vision is transforming fashion through Virtual Try-On (VTON) and Virtual Try-Off (VTOFF). VTON generates images of a person in a specified garment using a target photo and a standardized garment image, while a more challenging variant, Person-to-Person Virtual Try-On (p2p-VTON), uses a photo of another person wearing the garment. VTOFF, on the other hand, extracts standardized garment images from clothed individuals. We introduce TryOffDiff, a diffusion-based VTOFF model. Built on a latent diffusion framework with SigLIP image conditioning, it effectively captures garment properties like texture, shape, and patterns. TryOffDiff achieves state-of-the-art results on VITON-HD and strong performance on DressCode dataset, covering upper-body, lower-body, and dresses. Enhanced with class-specific embeddings, it pioneers multi-garment VTOFF, the first of its kind. When paired with VTON models, it improves p2p-VTON by minimizing unwanted attribute transfer, such as skin color. Code is available at: https://rizavelioglu.github.io/tryoffdiff/
TryOffDiff: Virtual-Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models
Nov 27, 2024
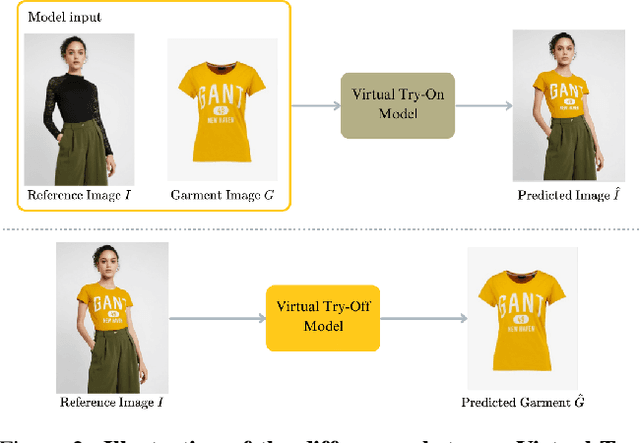


This paper introduces Virtual Try-Off (VTOFF), a novel task focused on generating standardized garment images from single photos of clothed individuals. Unlike traditional Virtual Try-On (VTON), which digitally dresses models, VTOFF aims to extract a canonical garment image, posing unique challenges in capturing garment shape, texture, and intricate patterns. This well-defined target makes VTOFF particularly effective for evaluating reconstruction fidelity in generative models. We present TryOffDiff, a model that adapts Stable Diffusion with SigLIP-based visual conditioning to ensure high fidelity and detail retention. Experiments on a modified VITON-HD dataset show that our approach outperforms baseline methods based on pose transfer and virtual try-on with fewer pre- and post-processing steps. Our analysis reveals that traditional image generation metrics inadequately assess reconstruction quality, prompting us to rely on DISTS for more accurate evaluation. Our results highlight the potential of VTOFF to enhance product imagery in e-commerce applications, advance generative model evaluation, and inspire future work on high-fidelity reconstruction. Demo, code, and models are available at: https://rizavelioglu.github.io/tryoffdiff/
New advances in universal approximation with neural networks of minimal width
Nov 13, 2024


Deep neural networks have achieved remarkable success in diverse applications, prompting the need for a solid theoretical foundation. Recent research has identified the minimal width $\max\{2,d_x,d_y\}$ required for neural networks with input dimensions $d_x$ and output dimension $d_y$ that use leaky ReLU activations to universally approximate $L^p(\mathbb{R}^{d_x},\mathbb{R}^{d_y})$ on compacta. Here, we present an alternative proof for the minimal width of such neural networks, by directly constructing approximating networks using a coding scheme that leverages the properties of leaky ReLUs and standard $L^p$ results. The obtained construction has a minimal interior dimension of $1$, independent of input and output dimensions, which allows us to show that autoencoders with leaky ReLU activations are universal approximators of $L^p$ functions. Furthermore, we demonstrate that the normalizing flow LU-Net serves as a distributional universal approximator. We broaden our results to show that smooth invertible neural networks can approximate $L^p(\mathbb{R}^{d},\mathbb{R}^{d})$ on compacta when the dimension $d\geq 2$, which provides a constructive proof of a classical theorem of Brenier and Gangbo. In addition, we use a topological argument to establish that for FNNs with monotone Lipschitz continuous activations, $d_x+1$ is a lower bound on the minimal width required for the uniform universal approximation of continuous functions $C^0(\mathbb{R}^{d_x},\mathbb{R}^{d_y})$ on compacta when $d_x\geq d_y$.
What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages
Jun 07, 2024What can large language models learn? By definition, language models (LM) are distributions over strings. Therefore, an intuitive way of addressing the above question is to formalize it as a matter of learnability of classes of distributions over strings. While prior work in this direction focused on assessing the theoretical limits, in contrast, we seek to understand the empirical learnability. Unlike prior empirical work, we evaluate neural LMs on their home turf-learning probabilistic languages-rather than as classifiers of formal languages. In particular, we investigate the learnability of regular LMs (RLMs) by RNN and Transformer LMs. We empirically test the learnability of RLMs as a function of various complexity parameters of the RLM and the hidden state size of the neural LM. We find that the RLM rank, which corresponds to the size of linear space spanned by the logits of its conditional distributions, and the expected length of sampled strings are strong and significant predictors of learnability for both RNNs and Transformers. Several other predictors also reach significance, but with differing patterns between RNNs and Transformers.
FashionFail: Addressing Failure Cases in Fashion Object Detection and Segmentation
Apr 12, 2024



In the realm of fashion object detection and segmentation for online shopping images, existing state-of-the-art fashion parsing models encounter limitations, particularly when exposed to non-model-worn apparel and close-up shots. To address these failures, we introduce FashionFail; a new fashion dataset with e-commerce images for object detection and segmentation. The dataset is efficiently curated using our novel annotation tool that leverages recent foundation models. The primary objective of FashionFail is to serve as a test bed for evaluating the robustness of models. Our analysis reveals the shortcomings of leading models, such as Attribute-Mask R-CNN and Fashionformer. Additionally, we propose a baseline approach using naive data augmentation to mitigate common failure cases and improve model robustness. Through this work, we aim to inspire and support further research in fashion item detection and segmentation for industrial applications. The dataset, annotation tool, code, and models are available at \url{https://rizavelioglu.github.io/fashionfail/}.
Have We Ever Encountered This Before? Retrieving Out-of-Distribution Road Obstacles from Driving Scenes
Sep 08, 2023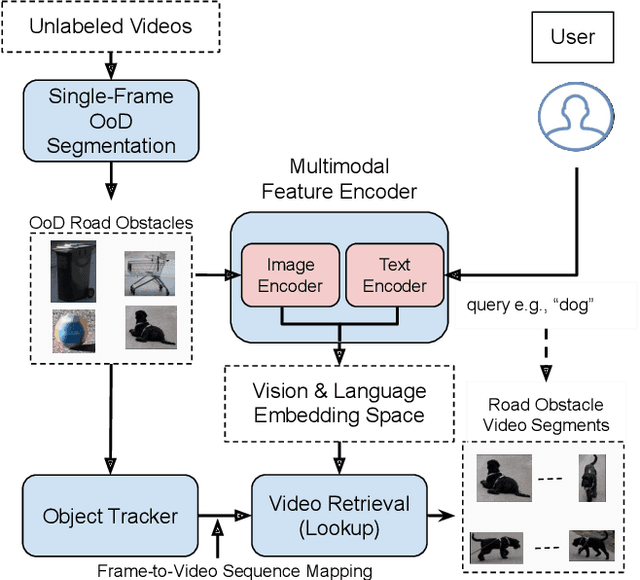
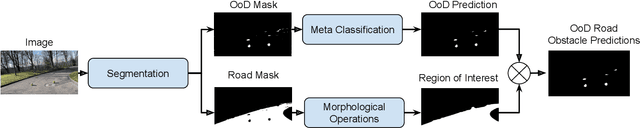
In the life cycle of highly automated systems operating in an open and dynamic environment, the ability to adjust to emerging challenges is crucial. For systems integrating data-driven AI-based components, rapid responses to deployment issues require fast access to related data for testing and reconfiguration. In the context of automated driving, this especially applies to road obstacles that were not included in the training data, commonly referred to as out-of-distribution (OoD) road obstacles. Given the availability of large uncurated recordings of driving scenes, a pragmatic approach is to query a database to retrieve similar scenarios featuring the same safety concerns due to OoD road obstacles. In this work, we extend beyond identifying OoD road obstacles in video streams and offer a comprehensive approach to extract sequences of OoD road obstacles using text queries, thereby proposing a way of curating a collection of OoD data for subsequent analysis. Our proposed method leverages the recent advances in OoD segmentation and multi-modal foundation models to identify and efficiently extract safety-relevant scenes from unlabeled videos. We present a first approach for the novel task of text-based OoD object retrieval, which addresses the question ''Have we ever encountered this before?''.
Which Spurious Correlations Impact Reasoning in NLI Models? A Visual Interactive Diagnosis through Data-Constrained Counterfactuals
Jun 21, 2023

We present a human-in-the-loop dashboard tailored to diagnosing potential spurious features that NLI models rely on for predictions. The dashboard enables users to generate diverse and challenging examples by drawing inspiration from GPT-3 suggestions. Additionally, users can receive feedback from a trained NLI model on how challenging the newly created example is and make refinements based on the feedback. Through our investigation, we discover several categories of spurious correlations that impact the reasoning of NLI models, which we group into three categories: Semantic Relevance, Logical Fallacies, and Bias. Based on our findings, we identify and describe various research opportunities, including diversifying training data and assessing NLI models' robustness by creating adversarial test suites.
LU-Net: Invertible Neural Networks Based on Matrix Factorization
Feb 21, 2023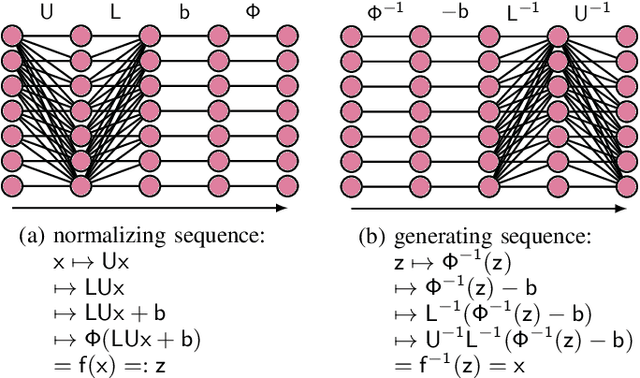
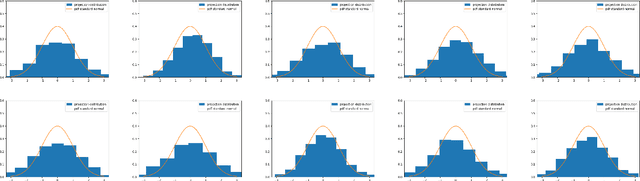
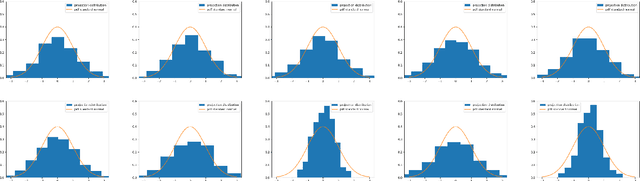
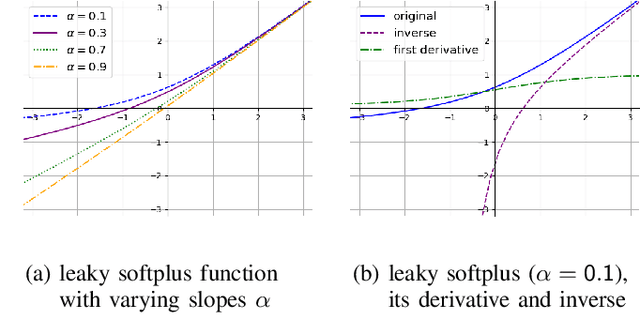
LU-Net is a simple and fast architecture for invertible neural networks (INN) that is based on the factorization of quadratic weight matrices $\mathsf{A=LU}$, where $\mathsf{L}$ is a lower triangular matrix with ones on the diagonal and $\mathsf{U}$ an upper triangular matrix. Instead of learning a fully occupied matrix $\mathsf{A}$, we learn $\mathsf{L}$ and $\mathsf{U}$ separately. If combined with an invertible activation function, such layers can easily be inverted whenever the diagonal entries of $\mathsf{U}$ are different from zero. Also, the computation of the determinant of the Jacobian matrix of such layers is cheap. Consequently, the LU architecture allows for cheap computation of the likelihood via the change of variables formula and can be trained according to the maximum likelihood principle. In our numerical experiments, we test the LU-net architecture as generative model on several academic datasets. We also provide a detailed comparison with conventional invertible neural networks in terms of performance, training as well as run time.
Two Video Data Sets for Tracking and Retrieval of Out of Distribution Objects
Oct 05, 2022
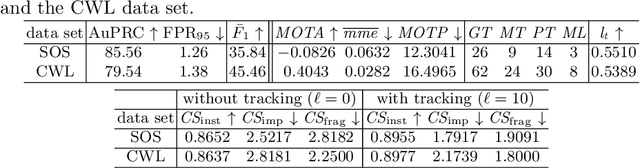
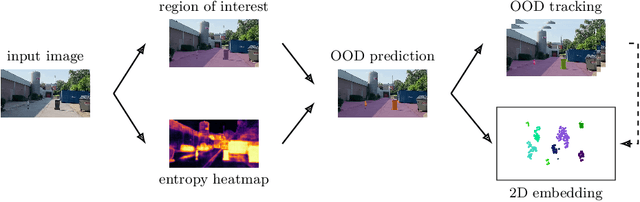

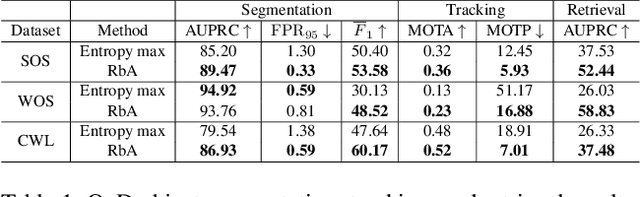
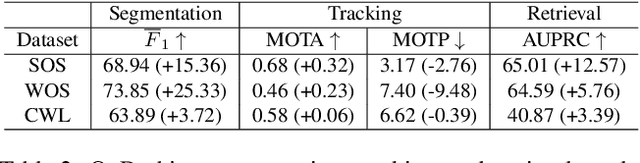
In this work we present two video test data sets for the novel computer vision (CV) task of out of distribution tracking (OOD tracking). Here, OOD objects are understood as objects with a semantic class outside the semantic space of an underlying image segmentation algorithm, or an instance within the semantic space which however looks decisively different from the instances contained in the training data. OOD objects occurring on video sequences should be detected on single frames as early as possible and tracked over their time of appearance as long as possible. During the time of appearance, they should be segmented as precisely as possible. We present the SOS data set containing 20 video sequences of street scenes and more than 1000 labeled frames with up to two OOD objects. We furthermore publish the synthetic CARLA-WildLife data set that consists of 26 video sequences containing up to four OOD objects on a single frame. We propose metrics to measure the success of OOD tracking and develop a baseline algorithm that efficiently tracks the OOD objects. As an application that benefits from OOD tracking, we retrieve OOD sequences from unlabeled videos of street scenes containing OOD objects.
What should AI see? Using the Public's Opinion to Determine the Perception of an AI
Jun 09, 2022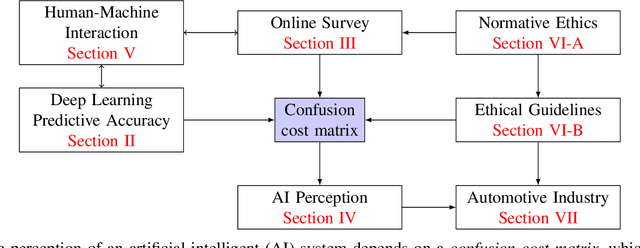

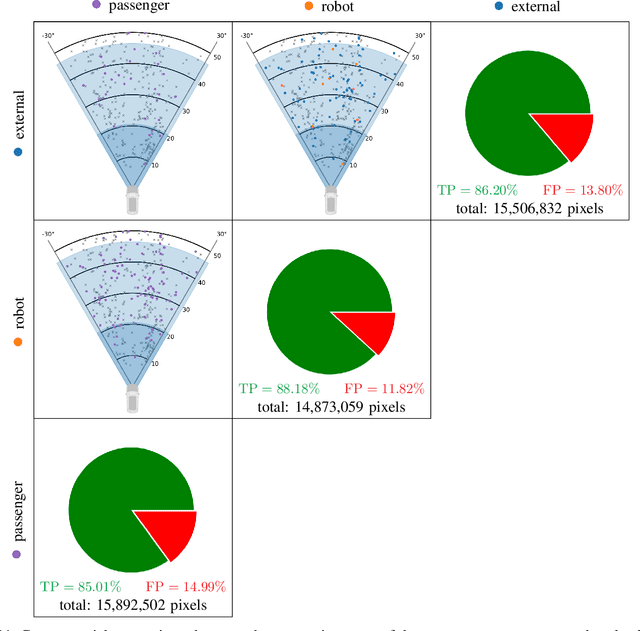
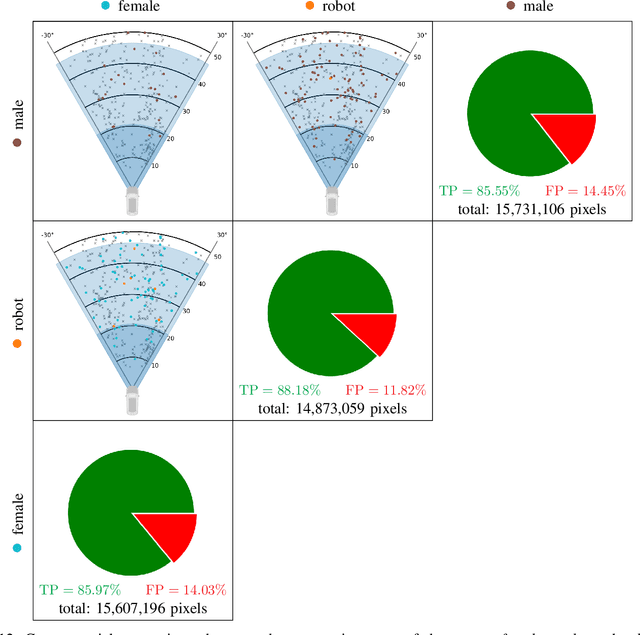
Deep neural networks (DNN) have made impressive progress in the interpretation of image data, so that it is conceivable and to some degree realistic to use them in safety critical applications like automated driving. From an ethical standpoint, the AI algorithm should take into account the vulnerability of objects or subjects on the street that ranges from "not at all", e.g. the road itself, to "high vulnerability" of pedestrians. One way to take this into account is to define the cost of confusion of one semantic category with another and use cost-based decision rules for the interpretation of probabilities, which are the output of DNNs. However, it is an open problem how to define the cost structure, who should be in charge to do that, and thereby define what AI-algorithms will actually "see". As one possible answer, we follow a participatory approach and set up an online survey to ask the public to define the cost structure. We present the survey design and the data acquired along with an evaluation that also distinguishes between perspective (car passenger vs. external traffic participant) and gender. Using simulation based $F$-tests, we find highly significant differences between the groups. These differences have consequences on the reliable detection of pedestrians in a safety critical distance to the self-driving car. We discuss the ethical problems that are related to this approach and also discuss the problems emerging from human-machine interaction through the survey from a psychological point of view. Finally, we include comments from industry leaders in the field of AI safety on the applicability of survey based elements in the design of AI functionalities in automated driving.