 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Person-to-Person Virtual Try-On with Multi-Garment Virtual Try-Off
Apr 17, 2025Computer vision is transforming fashion through Virtual Try-On (VTON) and Virtual Try-Off (VTOFF). VTON generates images of a person in a specified garment using a target photo and a standardized garment image, while a more challenging variant, Person-to-Person Virtual Try-On (p2p-VTON), uses a photo of another person wearing the garment. VTOFF, on the other hand, extracts standardized garment images from clothed individuals. We introduce TryOffDiff, a diffusion-based VTOFF model. Built on a latent diffusion framework with SigLIP image conditioning, it effectively captures garment properties like texture, shape, and patterns. TryOffDiff achieves state-of-the-art results on VITON-HD and strong performance on DressCode dataset, covering upper-body, lower-body, and dresses. Enhanced with class-specific embeddings, it pioneers multi-garment VTOFF, the first of its kind. When paired with VTON models, it improves p2p-VTON by minimizing unwanted attribute transfer, such as skin color. Code is available at: https://rizavelioglu.github.io/tryoffdiff/
TryOffDiff: Virtual-Try-Off via High-Fidelity Garment Reconstruction using Diffusion Models
Nov 27, 2024
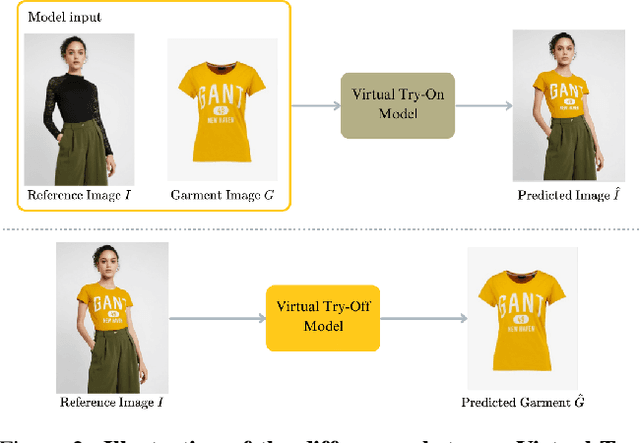


This paper introduces Virtual Try-Off (VTOFF), a novel task focused on generating standardized garment images from single photos of clothed individuals. Unlike traditional Virtual Try-On (VTON), which digitally dresses models, VTOFF aims to extract a canonical garment image, posing unique challenges in capturing garment shape, texture, and intricate patterns. This well-defined target makes VTOFF particularly effective for evaluating reconstruction fidelity in generative models. We present TryOffDiff, a model that adapts Stable Diffusion with SigLIP-based visual conditioning to ensure high fidelity and detail retention. Experiments on a modified VITON-HD dataset show that our approach outperforms baseline methods based on pose transfer and virtual try-on with fewer pre- and post-processing steps. Our analysis reveals that traditional image generation metrics inadequately assess reconstruction quality, prompting us to rely on DISTS for more accurate evaluation. Our results highlight the potential of VTOFF to enhance product imagery in e-commerce applications, advance generative model evaluation, and inspire future work on high-fidelity reconstruction. Demo, code, and models are available at: https://rizavelioglu.github.io/tryoffdiff/
FashionFail: Addressing Failure Cases in Fashion Object Detection and Segmentation
Apr 12, 2024



In the realm of fashion object detection and segmentation for online shopping images, existing state-of-the-art fashion parsing models encounter limitations, particularly when exposed to non-model-worn apparel and close-up shots. To address these failures, we introduce FashionFail; a new fashion dataset with e-commerce images for object detection and segmentation. The dataset is efficiently curated using our novel annotation tool that leverages recent foundation models. The primary objective of FashionFail is to serve as a test bed for evaluating the robustness of models. Our analysis reveals the shortcomings of leading models, such as Attribute-Mask R-CNN and Fashionformer. Additionally, we propose a baseline approach using naive data augmentation to mitigate common failure cases and improve model robustness. Through this work, we aim to inspire and support further research in fashion item detection and segmentation for industrial applications. The dataset, annotation tool, code, and models are available at \url{https://rizavelioglu.github.io/fashionfail/}.
Explainable Artificial Intelligence for Improved Modeling of Processes
Dec 01, 2022In modern business processes, the amount of data collected has increased substantially in recent years. Because this data can potentially yield valuable insights, automated knowledge extraction based on process mining has been proposed, among other techniques, to provide users with intuitive access to the information contained therein. At present, the majority of technologies aim to reconstruct explicit business process models. These are directly interpretable but limited concerning the integration of diverse and real-valued information sources. On the other hand, Machine Learning (ML) benefits from the vast amount of data available and can deal with high-dimensional sources, yet it has rarely been applied to being used in processes. In this contribution, we evaluate the capability of modern Transformer architectures as well as more classical ML technologies of modeling process regularities, as can be quantitatively evaluated by their prediction capability. In addition, we demonstrate the capability of attentional properties and feature relevance determination by highlighting features that are crucial to the processes' predictive abilities. We demonstrate the efficacy of our approach using five benchmark datasets and show that the ML models are capable of predicting critical outcomes and that the attention mechanisms or XAI components offer new insights into the underlying processes.
* 12 pages, 3 tables, 3 figures. Published in IDEAL 2022: https://link.springer.com/chapter/10.1007/978-3-031-21753-1_31
Traffic4cast at NeurIPS 2021 -- Temporal and Spatial Few-Shot Transfer Learning in Gridded Geo-Spatial Processes
Apr 01, 2022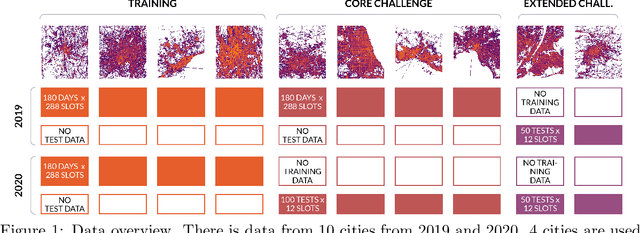
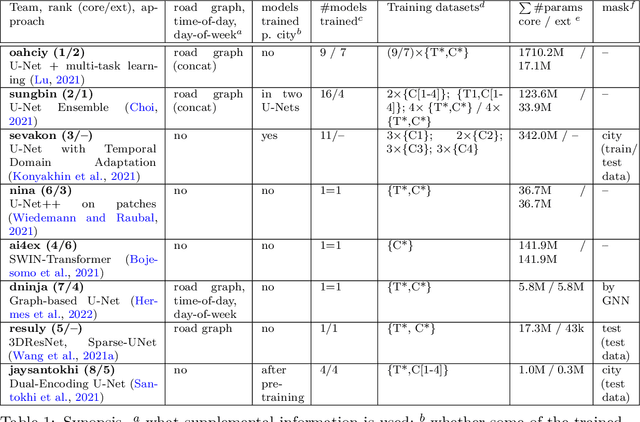
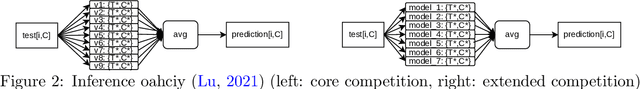
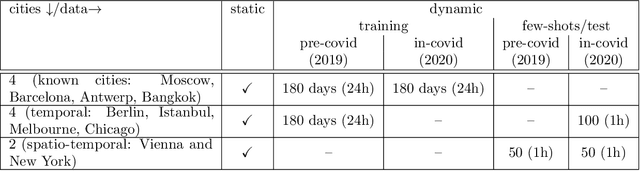
The IARAI Traffic4cast competitions at NeurIPS 2019 and 2020 showed that neural networks can successfully predict future traffic conditions 1 hour into the future on simply aggregated GPS probe data in time and space bins. We thus reinterpreted the challenge of forecasting traffic conditions as a movie completion task. U-Nets proved to be the winning architecture, demonstrating an ability to extract relevant features in this complex real-world geo-spatial process. Building on the previous competitions, Traffic4cast 2021 now focuses on the question of model robustness and generalizability across time and space. Moving from one city to an entirely different city, or moving from pre-COVID times to times after COVID hit the world thus introduces a clear domain shift. We thus, for the first time, release data featuring such domain shifts. The competition now covers ten cities over 2 years, providing data compiled from over 10^12 GPS probe data. Winning solutions captured traffic dynamics sufficiently well to even cope with these complex domain shifts. Surprisingly, this seemed to require only the previous 1h traffic dynamic history and static road graph as input.
A Graph-based U-Net Model for Predicting Traffic in unseen Cities
Mar 01, 2022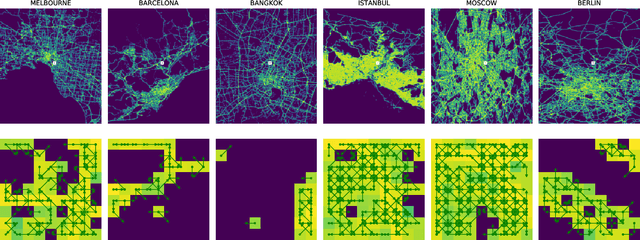
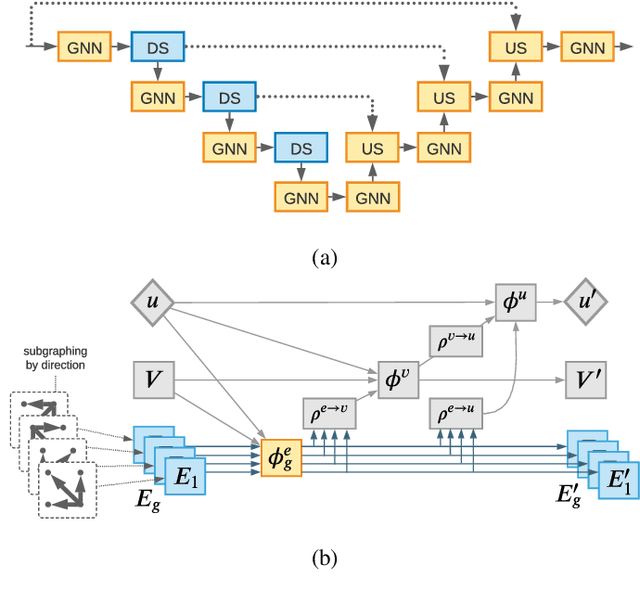
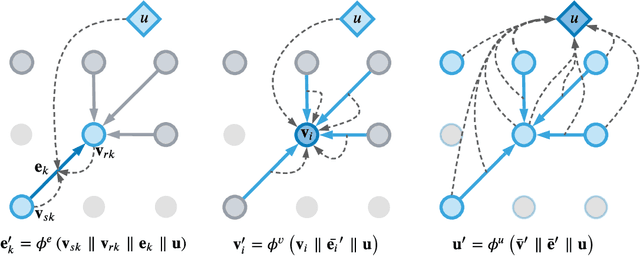
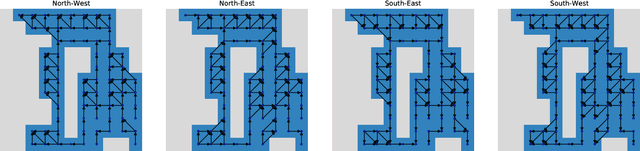
Accurate traffic prediction is a key ingredient to enable traffic management like rerouting cars to reduce road congestion or regulating traffic via dynamic speed limits to maintain a steady flow. A way to represent traffic data is in the form of temporally changing heatmaps visualizing attributes of traffic, such as speed and volume. In recent works, U-Net models have shown SOTA performance on traffic forecasting from heatmaps. We propose to combine the U-Net architecture with graph layers which improves spatial generalization to unseen road networks compared to a Vanilla U-Net. In particular, we specialize existing graph operations to be sensitive to geographical topology and generalize pooling and upsampling operations to be applicable to graphs.
Detecting Hate Speech in Memes Using Multimodal Deep Learning Approaches: Prize-winning solution to Hateful Memes Challenge
Dec 23, 2020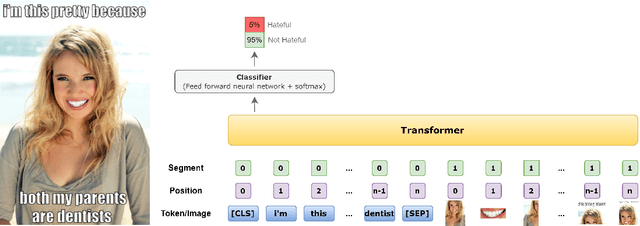
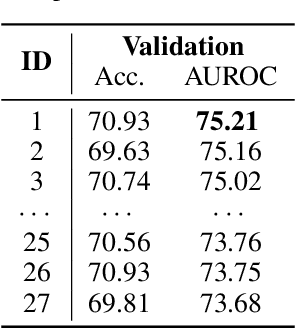

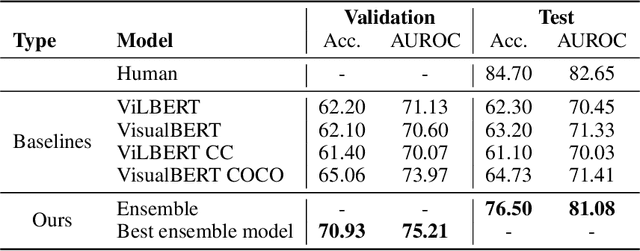
Memes on the Internet are often harmless and sometimes amusing. However, by using certain types of images, text, or combinations of both, the seemingly harmless meme becomes a multimodal type of hate speech -- a hateful meme. The Hateful Memes Challenge is a first-of-its-kind competition which focuses on detecting hate speech in multimodal memes and it proposes a new data set containing 10,000+ new examples of multimodal content. We utilize VisualBERT -- which meant to be the BERT of vision and language -- that was trained multimodally on images and captions and apply Ensemble Learning. Our approach achieves 0.811 AUROC with an accuracy of 0.765 on the challenge test set and placed third out of 3,173 participants in the Hateful Memes Challenge.