 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Artificial Intelligence for Improved Modeling of Processes
Dec 01, 2022In modern business processes, the amount of data collected has increased substantially in recent years. Because this data can potentially yield valuable insights, automated knowledge extraction based on process mining has been proposed, among other techniques, to provide users with intuitive access to the information contained therein. At present, the majority of technologies aim to reconstruct explicit business process models. These are directly interpretable but limited concerning the integration of diverse and real-valued information sources. On the other hand, Machine Learning (ML) benefits from the vast amount of data available and can deal with high-dimensional sources, yet it has rarely been applied to being used in processes. In this contribution, we evaluate the capability of modern Transformer architectures as well as more classical ML technologies of modeling process regularities, as can be quantitatively evaluated by their prediction capability. In addition, we demonstrate the capability of attentional properties and feature relevance determination by highlighting features that are crucial to the processes' predictive abilities. We demonstrate the efficacy of our approach using five benchmark datasets and show that the ML models are capable of predicting critical outcomes and that the attention mechanisms or XAI components offer new insights into the underlying processes.
* 12 pages, 3 tables, 3 figures. Published in IDEAL 2022: https://link.springer.com/chapter/10.1007/978-3-031-21753-1_31
Intuitiveness in Active Teaching
Dec 25, 2020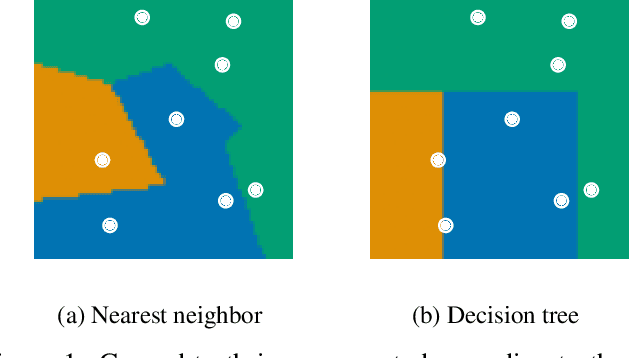
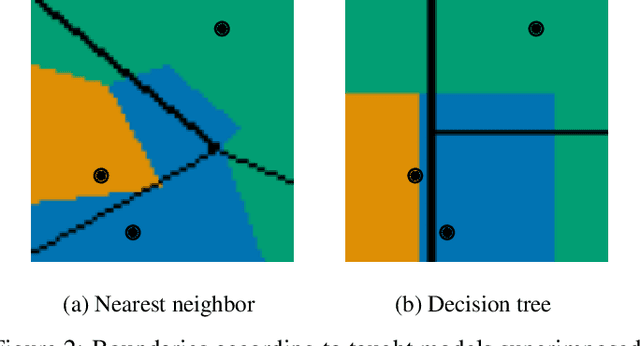
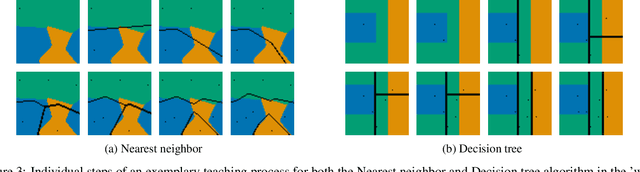
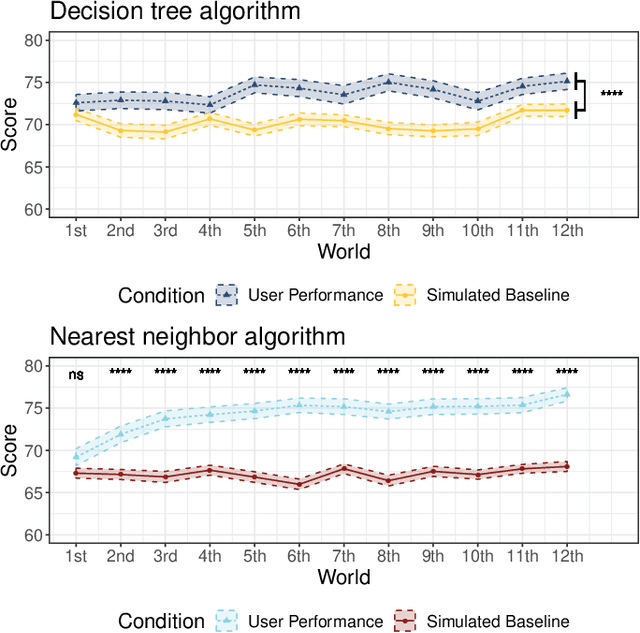
Machine learning is a double-edged sword: it gives rise to astonishing results in automated systems, but at the cost of tremendously large data requirements. This makes many successful algorithms from machine learning unsuitable for human-machine interaction, where the machine must learn from a small number of training samples that can be provided by a user within a reasonable time frame. Fortunately, the user can tailor the training data they create to be as useful as possible, severely limiting its necessary size -- as long as they know about the machine's requirements and limitations. Of course, acquiring this knowledge can in turn be cumbersome and costly. This raises the question how easy machine learning algorithms are to interact with. In this work we address this issue by analyzing the intuitiveness of certain algorithms when they are actively taught by users. After developing a theoretical framework of intuitiveness as a property of algorithms, we present and discuss the results of a large-scale user study into the performance and teaching strategies of 800 users interacting with prominent machine learning algorithms. Via this extensive examination we offer a systematic method to judge the efficacy of human-machine interactions and thus, to scrutinize how accessible, understandable, and fair, a system is.
Locally Adaptive Nearest Neighbors
Nov 08, 2020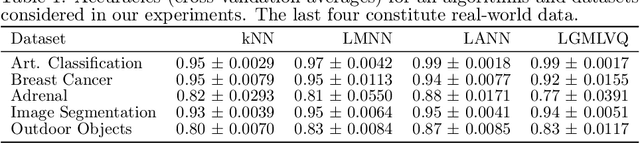

When training automated systems, it has been shown to be beneficial to adapt the representation of data by learning a problem-specific metric. This metric is global. We extend this idea and, for the widely used family of k nearest neighbors algorithms, develop a method that allows learning locally adaptive metrics. To demonstrate important aspects of how our approach works, we conduct a number of experiments on synthetic data sets, and we show its usefulness on real-world benchmark data sets.
Adversarial examples and where to find them
Apr 22, 2020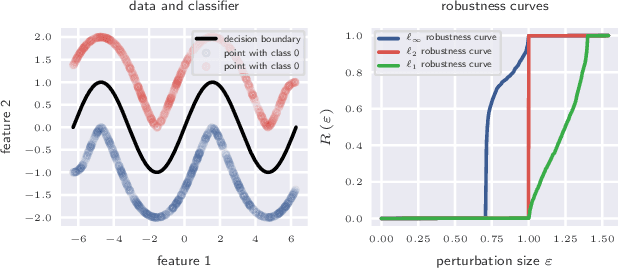
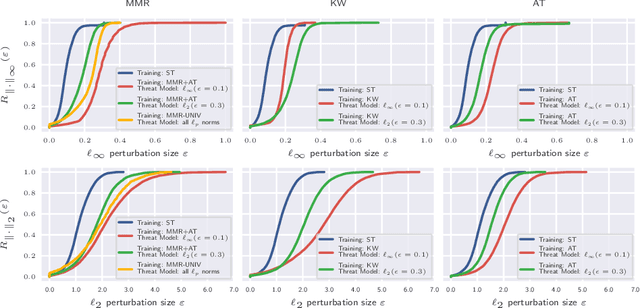
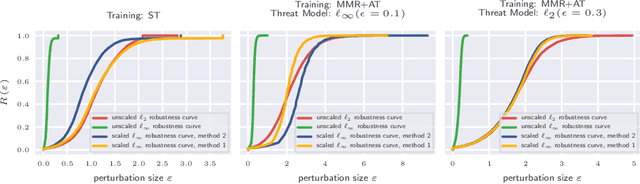
Adversarial robustness of trained models has attracted considerable attention over recent years, within and beyond the scientific community. This is not only because of a straight-forward desire to deploy reliable systems, but also because of how adversarial attacks challenge our beliefs about deep neural networks. Demanding more robust models seems to be the obvious solution -- however, this requires a rigorous understanding of how one should judge adversarial robustness as a property of a given model. In this work, we analyze where adversarial examples occur, in which ways they are peculiar, and how they are processed by robust models. We use robustness curves to show that $\ell_\infty$ threat models are surprisingly effective in improving robustness for other $\ell_p$ norms; we introduce perturbation cost trajectories to provide a broad perspective on how robust and non-robust networks perceive adversarial perturbations as opposed to random perturbations; and we explicitly examine the scale of certain common data sets, showing that robustness thresholds must be adapted to the data set they pertain to. This allows us to provide concrete recommendations for anyone looking to train a robust model or to estimate how much robustness they should require for their operation. The code for all our experiments is available at www.github.com/niklasrisse/adversarial-examples-and-where-to-find-them .
Recovering Localized Adversarial Attacks
Oct 21, 2019
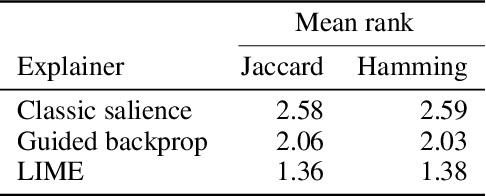

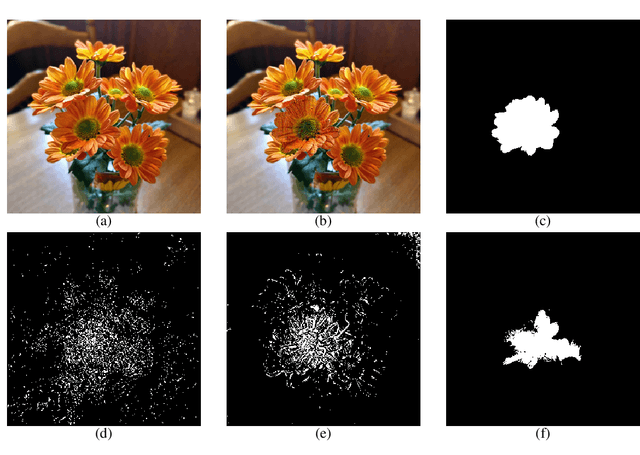
Deep convolutional neural networks have achieved great successes over recent years, particularly in the domain of computer vision. They are fast, convenient, and -- thanks to mature frameworks -- relatively easy to implement and deploy. However, their reasoning is hidden inside a black box, in spite of a number of proposed approaches that try to provide human-understandable explanations for the predictions of neural networks. It is still a matter of debate which of these explainers are best suited for which situations, and how to quantitatively evaluate and compare them. In this contribution, we focus on the capabilities of explainers for convolutional deep neural networks in an extreme situation: a setting in which humans and networks fundamentally disagree. Deep neural networks are susceptible to adversarial attacks that deliberately modify input samples to mislead a neural network's classification, without affecting how a human observer interprets the input. Our goal with this contribution is to evaluate explainers by investigating whether they can identify adversarially attacked regions of an image. In particular, we quantitatively and qualitatively investigate the capability of three popular explainers of classifications -- classic salience, guided backpropagation, and LIME -- with respect to their ability to identify regions of attack as the explanatory regions for the (incorrect) prediction in representative examples from image classification. We find that LIME outperforms the other explainers.
Adversarial Robustness Curves
Jul 31, 2019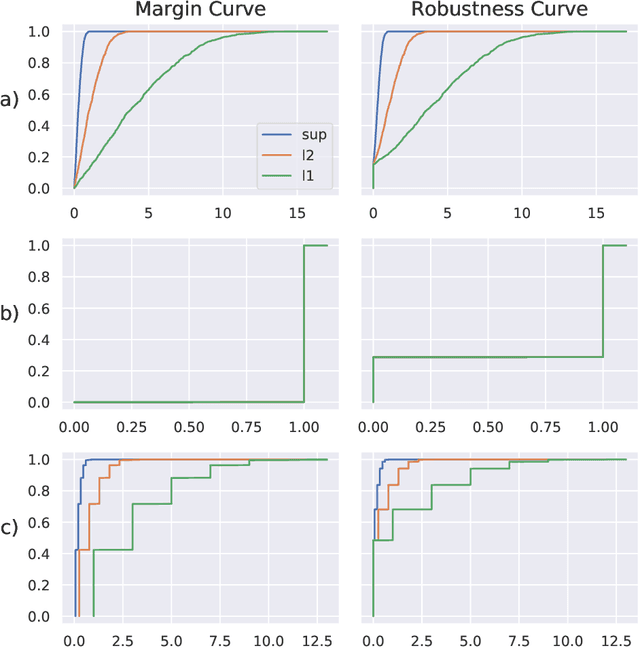
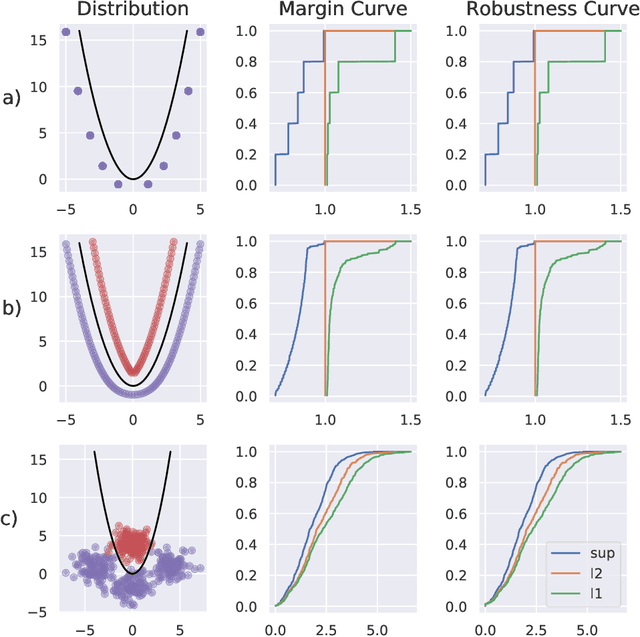
The existence of adversarial examples has led to considerable uncertainty regarding the trust one can justifiably put in predictions produced by automated systems. This uncertainty has, in turn, lead to considerable research effort in understanding adversarial robustness. In this work, we take first steps towards separating robustness analysis from the choice of robustness threshold and norm. We propose robustness curves as a more general view of the robustness behavior of a model and investigate under which circumstances they can qualitatively depend on the chosen norm.
Adversarial attacks hidden in plain sight
Feb 25, 2019


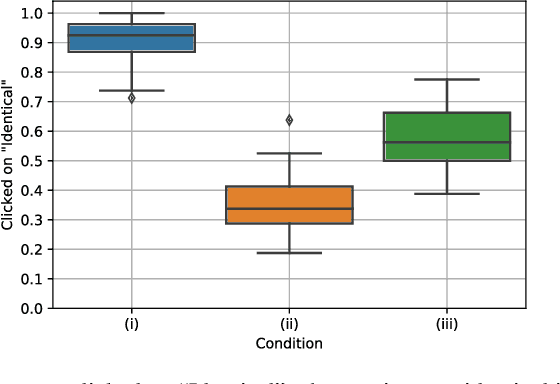
Convolutional neural networks have been used to achieve a string of successes during recent years, but their lack of interpretability remains a serious issue. Adversarial examples are designed to deliberately fool neural networks into making any desired incorrect classification, potentially with very high certainty. We underline the severity of the issue by presenting a technique that allows to hide such adversarial attacks in regions of high complexity, such that they are imperceptible even to an astute observer.