 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop Score on the Wrong Exam: On Benchmarking in Machine Learning for Vulnerability Detection
Aug 23, 2024
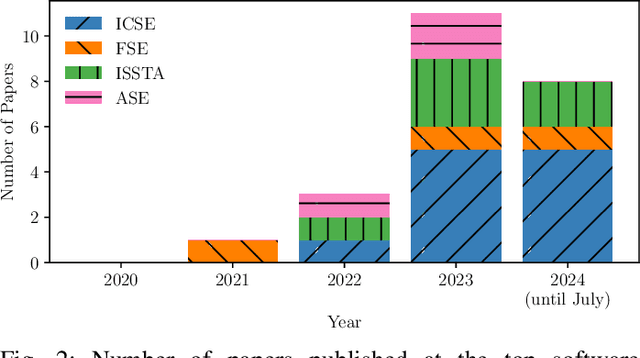
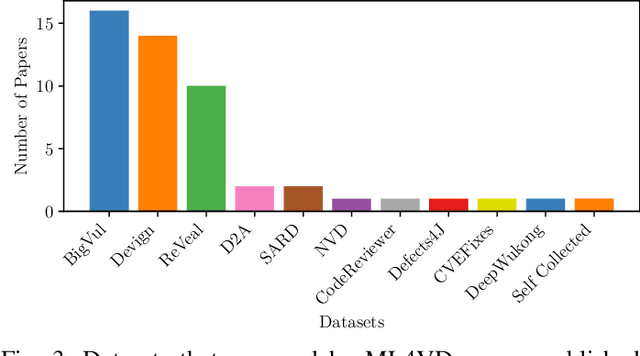
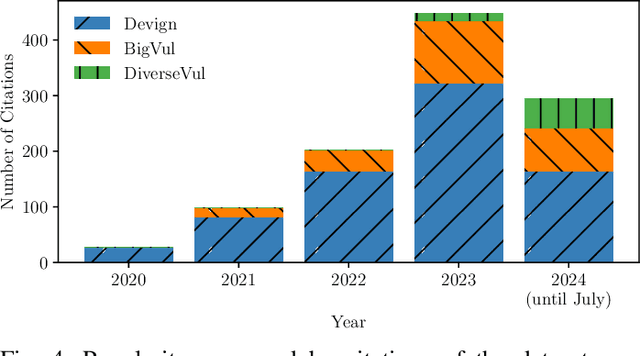
According to our survey of the machine learning for vulnerability detection (ML4VD) literature published in the top Software Engineering conferences, every paper in the past 5 years defines ML4VD as a binary classification problem: Given a function, does it contain a security flaw? In this paper, we ask whether this decision can really be made without further context and study both vulnerable and non-vulnerable functions in the most popular ML4VD datasets. A function is vulnerable if it was involved in a patch of an actual security flaw and confirmed to cause the vulnerability. It is non-vulnerable otherwise. We find that in almost all cases this decision cannot be made without further context. Vulnerable functions are often vulnerable only because a corresponding vulnerability-inducing calling context exists while non-vulnerable functions would often be vulnerable if a corresponding context existed. But why do ML4VD techniques perform so well even though there is demonstrably not enough information in these samples? Spurious correlations: We find that high accuracy can be achieved even when only word counts are available. This shows that these datasets can be exploited to achieve high accuracy without actually detecting any security vulnerabilities. We conclude that the current problem statement of ML4VD is ill-defined and call into question the internal validity of this growing body of work. Constructively, we call for more effective benchmarking methodologies to evaluate the true capabilities of ML4VD, propose alternative problem statements, and examine broader implications for the evaluation of machine learning and programming analysis research.
Limits of Machine Learning for Automatic Vulnerability Detection
Jun 28, 2023



Recent results of machine learning for automatic vulnerability detection have been very promising indeed: Given only the source code of a function $f$, models trained by machine learning techniques can decide if $f$ contains a security flaw with up to 70% accuracy. But how do we know that these results are general and not specific to the datasets? To study this question, researchers proposed to amplify the testing set by injecting semantic preserving changes and found that the model's accuracy significantly drops. In other words, the model uses some unrelated features during classification. In order to increase the robustness of the model, researchers proposed to train on amplified training data, and indeed model accuracy increased to previous levels. In this paper, we replicate and continue this investigation, and provide an actionable model benchmarking methodology to help researchers better evaluate advances in machine learning for vulnerability detection. Specifically, we propose (i) a cross validation algorithm, where a semantic preserving transformation is applied during the amplification of either the training set or the testing set, and (ii) the amplification of the testing set with code snippets where the vulnerabilities are fixed. Using 11 transformations, 3 ML techniques, and 2 datasets, we find that the improved robustness only applies to the specific transformations used during training data amplification. In other words, the robustified models still rely on unrelated features for predicting the vulnerabilities in the testing data. Additionally, we find that the trained models are unable to generalize to the modified setting which requires to distinguish vulnerable functions from their patches.
Adversarial examples and where to find them
Apr 22, 2020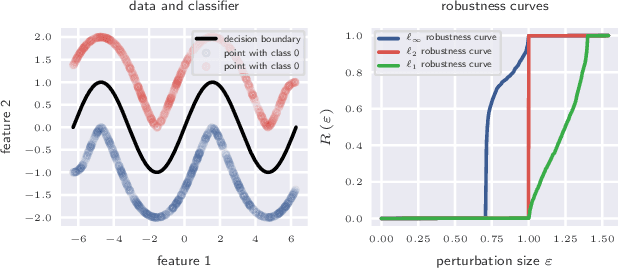
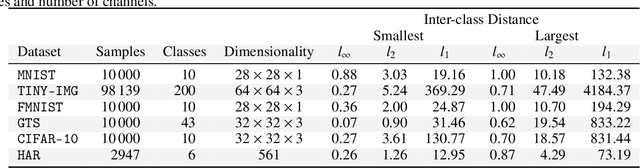
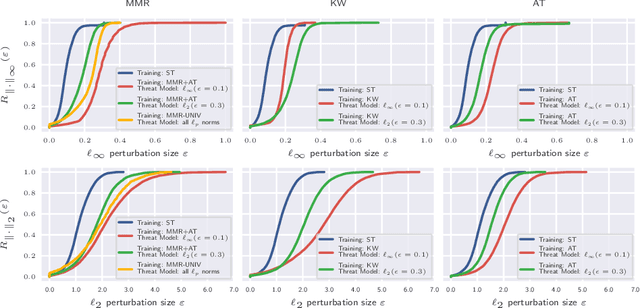
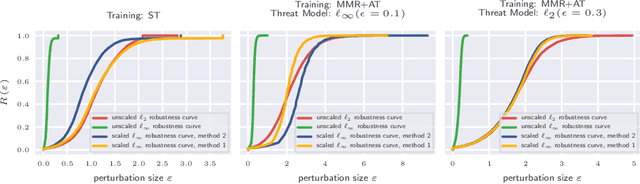
Adversarial robustness of trained models has attracted considerable attention over recent years, within and beyond the scientific community. This is not only because of a straight-forward desire to deploy reliable systems, but also because of how adversarial attacks challenge our beliefs about deep neural networks. Demanding more robust models seems to be the obvious solution -- however, this requires a rigorous understanding of how one should judge adversarial robustness as a property of a given model. In this work, we analyze where adversarial examples occur, in which ways they are peculiar, and how they are processed by robust models. We use robustness curves to show that $\ell_\infty$ threat models are surprisingly effective in improving robustness for other $\ell_p$ norms; we introduce perturbation cost trajectories to provide a broad perspective on how robust and non-robust networks perceive adversarial perturbations as opposed to random perturbations; and we explicitly examine the scale of certain common data sets, showing that robustness thresholds must be adapted to the data set they pertain to. This allows us to provide concrete recommendations for anyone looking to train a robust model or to estimate how much robustness they should require for their operation. The code for all our experiments is available at www.github.com/niklasrisse/adversarial-examples-and-where-to-find-them .