 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Computation
Mar 13, 2025
In this vision paper, we explore the challenges and opportunities of a form of computation that employs an empirical (rather than a formal) approach, where the solution of a computational problem is returned as empirically most likely (rather than necessarily correct). We call this approach as *empirical computation* and observe that its capabilities and limits *cannot* be understood within the classic, rationalist framework of computation. While we take a very broad view of "computational problem", a classic, well-studied example is *sorting*: Given a set of $n$ numbers, return these numbers sorted in ascending order. * To run a classical, *formal computation*, we might first think about a *specific algorithm* (e.g., merge sort) before developing a *specific* program that implements it. The program will expect the input to be given in a *specific* format, type, or data structure (e.g., unsigned 32-bit integers). In software engineering, we have many approaches to analyze the correctness of such programs. From complexity theory, we know that there exists no correct program that can solve the average instance of the sorting problem faster than $O(n\log n)$. * To run an *empirical computation*, we might directly ask a large language model (LLM) to solve *any* computational problem (which can be stated informally in natural language) and provide the input in *any* format (e.g., negative numbers written as Chinese characters). There is no (problem-specific) program that could be analyzed for correctness. Also, the time it takes an LLM to return an answer is entirely *independent* of the computational complexity of the problem that is solved. What are the capabilities or limits of empirical computation in the general, in the problem-, or in the instance-specific? Our purpose is to establish empirical computation as a field in SE that is timely and rich with interesting problems.
Can LLM Generate Regression Tests for Software Commits?
Jan 19, 2025



Large Language Models (LLMs) have shown tremendous promise in automated software engineering. In this paper, we investigate the opportunities of LLMs for automatic regression test generation for programs that take highly structured, human-readable inputs, such as XML parsers or JavaScript interpreters. Concretely, we explore the following regression test generation scenarios for such programs that have so far been difficult to test automatically in the absence of corresponding input grammars: $\bullet$ Bug finding. Given a code change (e.g., a commit or pull request), our LLM-based approach generates a test case with the objective of revealing any bugs that might be introduced if that change is applied. $\bullet$ Patch testing. Given a patch, our LLM-based approach generates a test case that fails before but passes after the patch. This test can be added to the regression test suite to catch similar bugs in the future. We implement Cleverest, a feedback-directed, zero-shot LLM-based regression test generation technique, and evaluate its effectiveness on 22 commits to three subject programs: Mujs, Libxml2, and Poppler. For programs using more human-readable file formats, like XML or JavaScript, we found Cleverest performed very well. It generated easy-to-understand bug-revealing or bug-reproduction test cases for the majority of commits in just under three minutes -- even when only the code diff or commit message (unless it was too vague) was given. For programs with more compact file formats, like PDF, as expected, it struggled to generate effective test cases. However, the LLM-supplied test cases are not very far from becoming effective (e.g., when used as a seed by a greybox fuzzer or as a starting point by the developer).
Top Score on the Wrong Exam: On Benchmarking in Machine Learning for Vulnerability Detection
Aug 23, 2024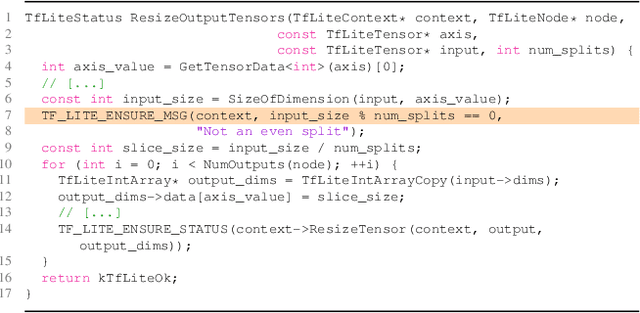
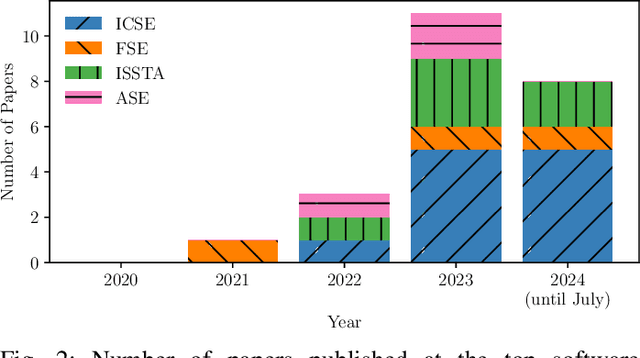
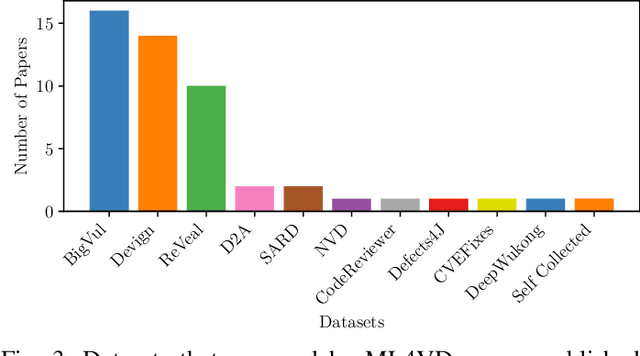
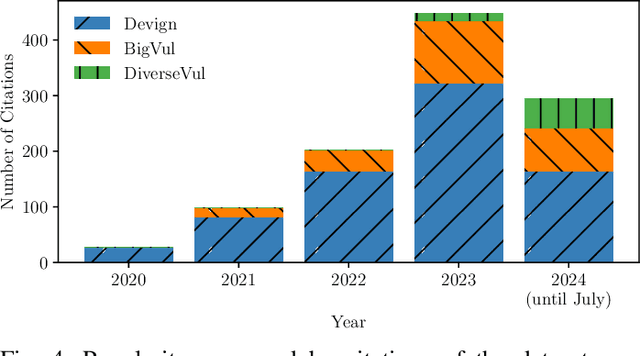
According to our survey of the machine learning for vulnerability detection (ML4VD) literature published in the top Software Engineering conferences, every paper in the past 5 years defines ML4VD as a binary classification problem: Given a function, does it contain a security flaw? In this paper, we ask whether this decision can really be made without further context and study both vulnerable and non-vulnerable functions in the most popular ML4VD datasets. A function is vulnerable if it was involved in a patch of an actual security flaw and confirmed to cause the vulnerability. It is non-vulnerable otherwise. We find that in almost all cases this decision cannot be made without further context. Vulnerable functions are often vulnerable only because a corresponding vulnerability-inducing calling context exists while non-vulnerable functions would often be vulnerable if a corresponding context existed. But why do ML4VD techniques perform so well even though there is demonstrably not enough information in these samples? Spurious correlations: We find that high accuracy can be achieved even when only word counts are available. This shows that these datasets can be exploited to achieve high accuracy without actually detecting any security vulnerabilities. We conclude that the current problem statement of ML4VD is ill-defined and call into question the internal validity of this growing body of work. Constructively, we call for more effective benchmarking methodologies to evaluate the true capabilities of ML4VD, propose alternative problem statements, and examine broader implications for the evaluation of machine learning and programming analysis research.
How Much is Unseen Depends Chiefly on Information About the Seen
Feb 08, 2024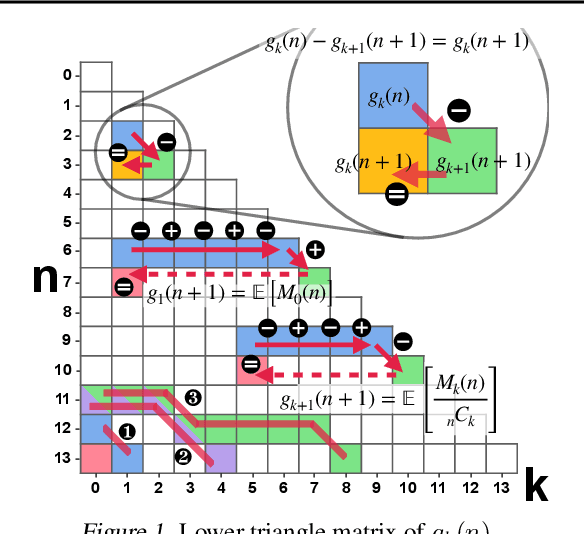
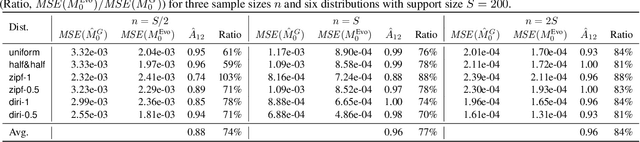

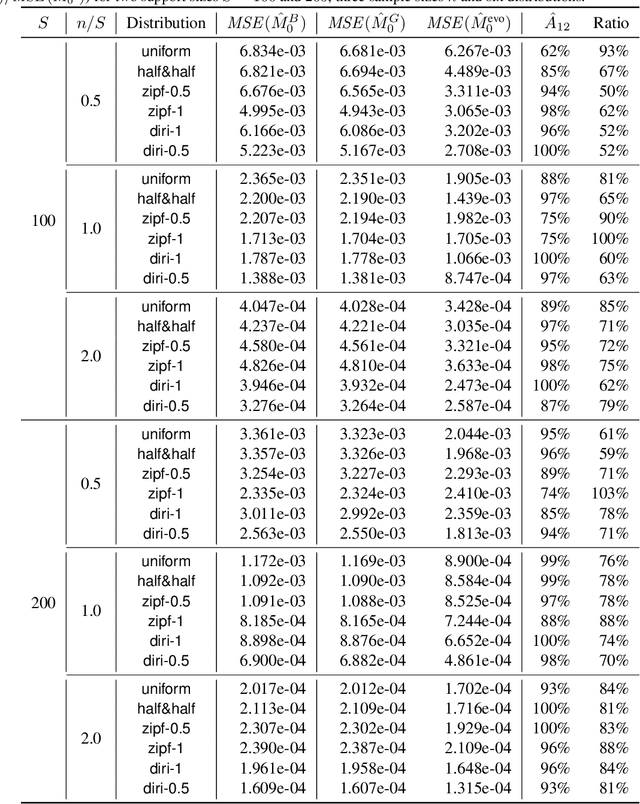
It might seem counter-intuitive at first: We find that, in expectation, the proportion of data points in an unknown population-that belong to classes that do not appear in the training data-is almost entirely determined by the number $f_k$ of classes that do appear in the training data the same number of times. While in theory we show that the difference of the induced estimator decays exponentially in the size of the sample, in practice the high variance prevents us from using it directly for an estimator of the sample coverage. However, our precise characterization of the dependency between $f_k$'s induces a large search space of different representations of the expected value, which can be deterministically instantiated as estimators. Hence, we turn to optimization and develop a genetic algorithm that, given only the sample, searches for an estimator with minimal mean-squared error (MSE). In our experiments, our genetic algorithm discovers estimators that have a substantially smaller MSE than the state-of-the-art Good-Turing estimator. This holds for over 96% of runs when there are at least as many samples as classes. Our estimators' MSE is roughly 80% of the Good-Turing estimator's.
Limits of Machine Learning for Automatic Vulnerability Detection
Jun 28, 2023



Recent results of machine learning for automatic vulnerability detection have been very promising indeed: Given only the source code of a function $f$, models trained by machine learning techniques can decide if $f$ contains a security flaw with up to 70% accuracy. But how do we know that these results are general and not specific to the datasets? To study this question, researchers proposed to amplify the testing set by injecting semantic preserving changes and found that the model's accuracy significantly drops. In other words, the model uses some unrelated features during classification. In order to increase the robustness of the model, researchers proposed to train on amplified training data, and indeed model accuracy increased to previous levels. In this paper, we replicate and continue this investigation, and provide an actionable model benchmarking methodology to help researchers better evaluate advances in machine learning for vulnerability detection. Specifically, we propose (i) a cross validation algorithm, where a semantic preserving transformation is applied during the amplification of either the training set or the testing set, and (ii) the amplification of the testing set with code snippets where the vulnerabilities are fixed. Using 11 transformations, 3 ML techniques, and 2 datasets, we find that the improved robustness only applies to the specific transformations used during training data amplification. In other words, the robustified models still rely on unrelated features for predicting the vulnerabilities in the testing data. Additionally, we find that the trained models are unable to generalize to the modified setting which requires to distinguish vulnerable functions from their patches.
Human-In-The-Loop Automatic Program Repair
Dec 16, 2019
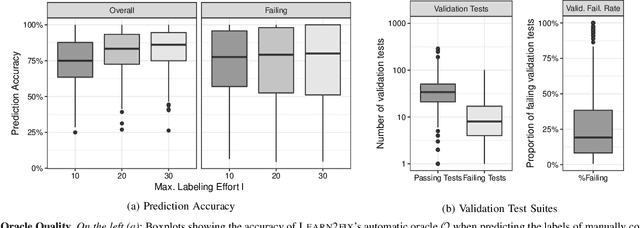
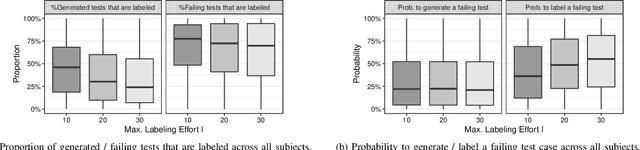
We introduce Learn2fix, the first human-in-the-loop, semi-automatic repair technique when no bug oracle--except for the user who is reporting the bug--is available. Our approach negotiates with the user the condition under which the bug is observed. Only when a budget of queries to the user is exhausted, it attempts to repair the bug. A query can be thought of as the following question: "When executing this alternative test input, the program produces the following output; is the bug observed"? Through systematic queries, Learn2fix trains an automatic bug oracle that becomes increasingly more accurate in predicting the user's response. Our key challenge is to maximize the oracle's accuracy in predicting which tests are bug-exposing given a small budget of queries. From the alternative tests that were labeled by the user, test-driven automatic repair produces the patch. Our experiments demonstrate that Learn2fix learns a sufficiently accurate automatic oracle with a reasonably low labeling effort (lt. 20 queries). Given Learn2fix's test suite, the GenProg test-driven repair tool produces a higher-quality patch (i.e., passing a larger proportion of validation tests) than using manual test suites provided with the repair benchmark.
MCPA: Program Analysis as Machine Learning
Nov 12, 2019

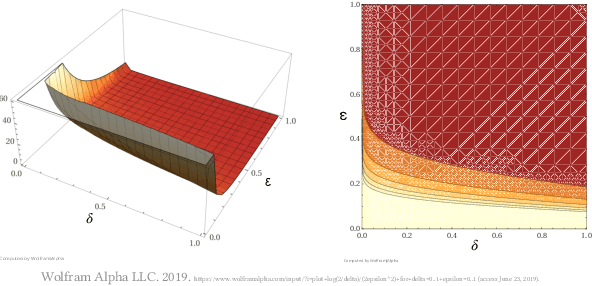

Static program analysis today takes an analytical approach which is quite suitable for a well-scoped system. Data- and control-flow is taken into account. Special cases such as pointers, procedures, and undefined behavior must be handled. A program is analyzed precisely on the statement level. However, the analytical approach is ill-equiped to handle implementations of complex, large-scale, heterogeneous software systems we see in the real world. Existing static analysis techniques that scale, trade correctness (i.e., soundness or completeness) for scalability and build on strong assumptions (e.g., language-specificity). Scalable static analysis are well-known to report errors that do *not* exist (false positives) or fail to report errors that *do* exist (false negatives). Then, how do we know the degree to which the analysis outcome is correct? In this paper, we propose an approach to scale-oblivious greybox program analysis with bounded error which applies efficient approximation schemes (FPRAS) from the foundations of machine learning: PAC learnability. Given two parameters $\delta$ and $\epsilon$, with probability at least $(1-\delta)$, our Monte Carlo Program Analysis (MCPA) approach produces an outcome that has an average error at most $\epsilon$. The parameters $\delta>0$ and $\epsilon>0$ can be chosen arbitrarily close to zero (0) such that the program analysis outcome is said to be probably-approximately correct (PAC). We demonstrate the pertinent concepts of MCPA using three applications: $(\epsilon,\delta)$-approximate quantitative analysis, $(\epsilon,\delta)$-approximate software verification, and $(\epsilon,\delta)$-approximate patch verification.