 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Zone-Adaptive Zero-Day Intrusion Detection for IoBT
Feb 18, 2026The Internet of Battlefield Things (IoBT) relies on heterogeneous, bandwidth-constrained, and intermittently connected tactical networks that face rapidly evolving cyber threats. In this setting, intrusion detection cannot depend on continuous central collection of raw traffic due to disrupted links, latency, operational security limits, and non-IID traffic across zones. We present Zone-Adaptive Intrusion Detection (ZAID), a collaborative detection and model-improvement framework for unseen attack types, where "zero-day" refers to previously unobserved attack families and behaviours (not vulnerability disclosure timing). ZAID combines a universal convolutional model for generalisable traffic representations, an autoencoder-based reconstruction signal as an auxiliary anomaly score, and lightweight adapter modules for parameter-efficient zone adaptation. To support cross-zone generalisation under constrained connectivity, ZAID uses federated aggregation and pseudo-labelling to leverage locally observed, weakly labelled behaviours. We evaluate ZAID on ToN_IoT using a zero-day protocol that excludes MITM, DDoS, and DoS from supervised training and introduces them during zone-level deployment and adaptation. ZAID achieves up to 83.16% accuracy on unseen attack traffic and transfers to UNSW-NB15 under the same procedure, with a best accuracy of 71.64%. These results indicate that parameter-efficient, zone-personalised collaboration can improve the detection of previously unseen attacks in contested IoBT environments.
UIXPOSE: Mobile Malware Detection via Intention-Behaviour Discrepancy Analysis
Dec 16, 2025



We introduce UIXPOSE, a source-code-agnostic framework that operates on both compiled and open-source apps. This framework applies Intention Behaviour Alignment (IBA) to mobile malware analysis, aligning UI-inferred intent with runtime semantics. Previous work either infers intent statically, e.g., permission-centric, or widget-level or monitors coarse dynamic signals (endpoints, partial resource usage) that miss content and context. UIXPOSE infers an intent vector from each screen using vision-language models and knowledge structures and combines decoded network payloads, heap/memory signals, and resource utilisation traces into a behaviour vector. Their alignment, calculated at runtime, can both detect misbehaviour and highlight exploration of behaviourally rich paths. In three real-world case studies, UIXPOSE reveals covert exfiltration and hidden background activity that evade metadata-only baselines, demonstrating how IBA improves dynamic detection.
State Selection Algorithms and Their Impact on The Performance of Stateful Network Protocol Fuzzing
Jan 07, 2022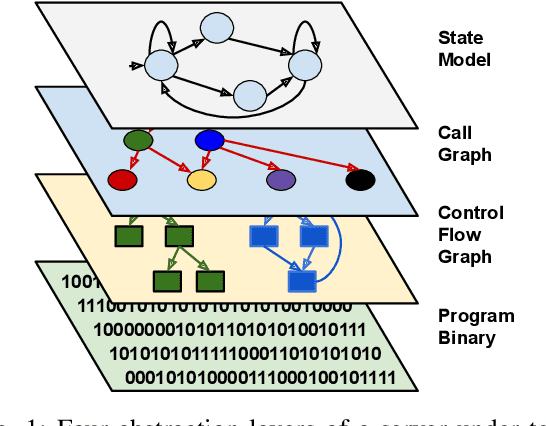
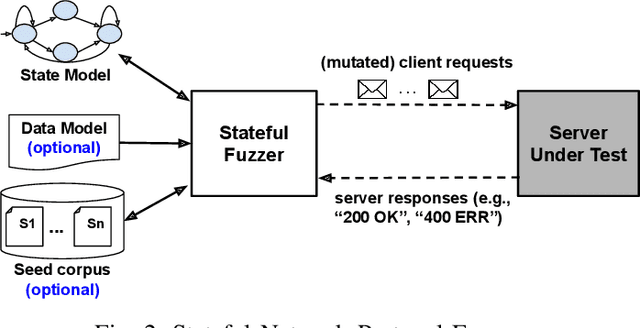
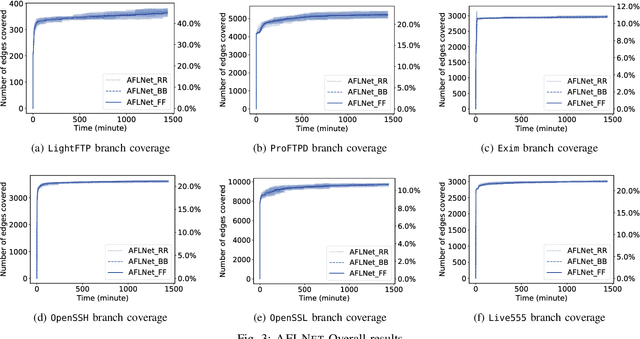

The statefulness property of network protocol implementations poses a unique challenge for testing and verification techniques, including Fuzzing. Stateful fuzzers tackle this challenge by leveraging state models to partition the state space and assist the test generation process. Since not all states are equally important and fuzzing campaigns have time limits, fuzzers need effective state selection algorithms to prioritize progressive states over others. Several state selection algorithms have been proposed but they were implemented and evaluated separately on different platforms, making it hard to achieve conclusive findings. In this work, we evaluate an extensive set of state selection algorithms on the same fuzzing platform that is AFLNet, a state-of-the-art fuzzer for network servers. The algorithm set includes existing ones supported by AFLNet and our novel and principled algorithm called AFLNetLegion. The experimental results on the ProFuzzBench benchmark show that (i) the existing state selection algorithms of AFLNet achieve very similar code coverage, (ii) AFLNetLegion clearly outperforms these algorithms in selected case studies, but (iii) the overall improvement appears insignificant. These are unexpected yet interesting findings. We identify problems and share insights that could open opportunities for future research on this topic.
Human-In-The-Loop Automatic Program Repair
Dec 16, 2019
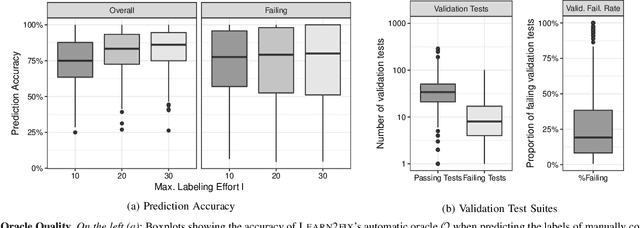
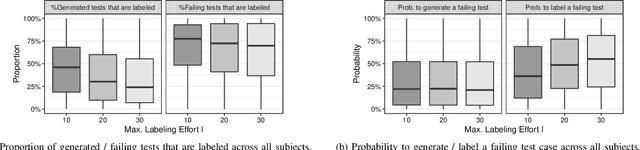
We introduce Learn2fix, the first human-in-the-loop, semi-automatic repair technique when no bug oracle--except for the user who is reporting the bug--is available. Our approach negotiates with the user the condition under which the bug is observed. Only when a budget of queries to the user is exhausted, it attempts to repair the bug. A query can be thought of as the following question: "When executing this alternative test input, the program produces the following output; is the bug observed"? Through systematic queries, Learn2fix trains an automatic bug oracle that becomes increasingly more accurate in predicting the user's response. Our key challenge is to maximize the oracle's accuracy in predicting which tests are bug-exposing given a small budget of queries. From the alternative tests that were labeled by the user, test-driven automatic repair produces the patch. Our experiments demonstrate that Learn2fix learns a sufficiently accurate automatic oracle with a reasonably low labeling effort (lt. 20 queries). Given Learn2fix's test suite, the GenProg test-driven repair tool produces a higher-quality patch (i.e., passing a larger proportion of validation tests) than using manual test suites provided with the repair benchmark.