 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Personalized Semantics for Soft Attributes in Recommender Systems using Concept Activation Vectors
Feb 06, 2022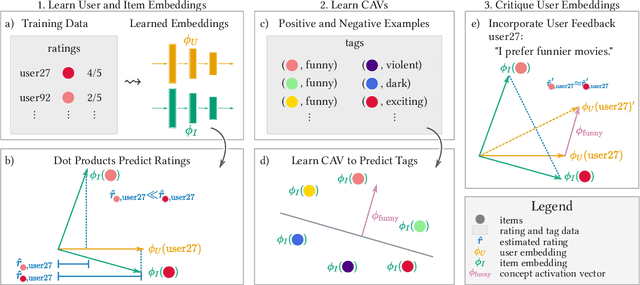


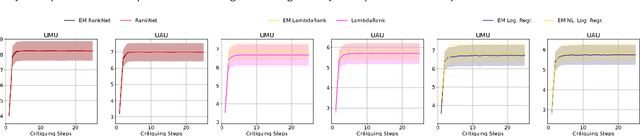
Interactive recommender systems (RSs) allow users to express intent, preferences and contexts in a rich fashion, often using natural language. One challenge in using such feedback is inferring a user's semantic intent from the open-ended terms used to describe an item, and using it to refine recommendation results. Leveraging concept activation vectors (CAVs) [21], we develop a framework to learn a representation that captures the semantics of such attributes and connects them to user preferences and behaviors in RSs. A novel feature of our approach is its ability to distinguish objective and subjective attributes and associate different senses with different users. Using synthetic and real-world datasets, we show that our CAV representation accurately interprets users' subjective semantics, and can improve recommendations via interactive critiquing
Supervised Learning in the Presence of Concept Drift: A modelling framework
May 21, 2020

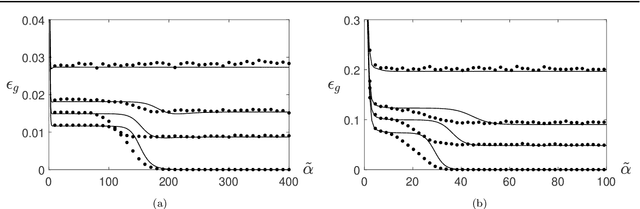
We present a modelling framework for the investigation of supervised learning in non-stationary environments. Specifically, we model two example types of learning systems: prototype-based Learning Vector Quantization (LVQ) for classification and shallow, layered neural networks for regression tasks. We investigate so-called student teacher scenarios in which the systems are trained from a stream of high-dimensional, labeled data. Properties of the target task are considered to be non-stationary due to drift processes while the training is performed. Different types of concept drift are studied, which affect the density of example inputs only, the target rule itself, or both. By applying methods from statistical physics, we develop a modelling framework for the mathematical analysis of the training dynamics in non-stationary environments. Our results show that standard LVQ algorithms are already suitable for the training in non-stationary environments to a certain extent. However, the application of weight decay as an explicit mechanism of forgetting does not improve the performance under the considered drift processes. Furthermore, we investigate gradient-based training of layered neural networks with sigmoidal activation functions and compare with the use of rectified linear units (ReLU). Our findings show that the sensitivity to concept drift and the effectiveness of weight decay differs significantly between the two types of activation function.
Adversarial examples and where to find them
Apr 22, 2020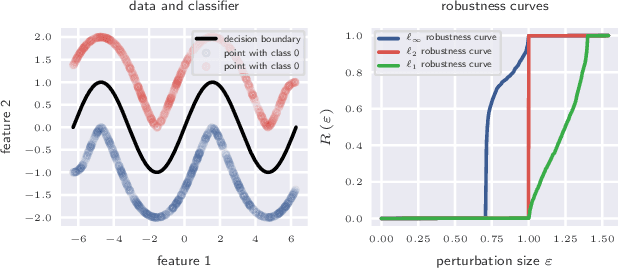
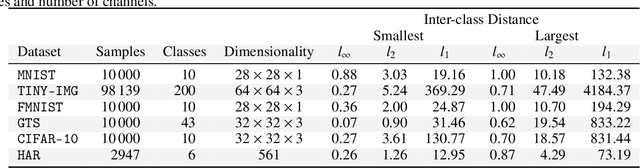
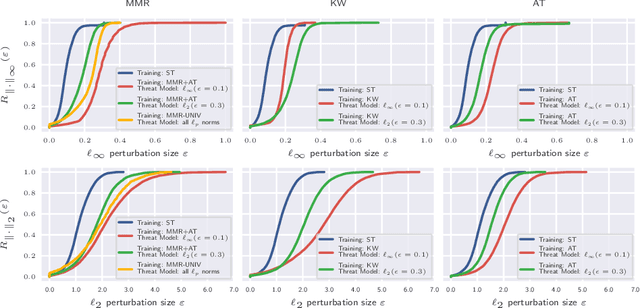
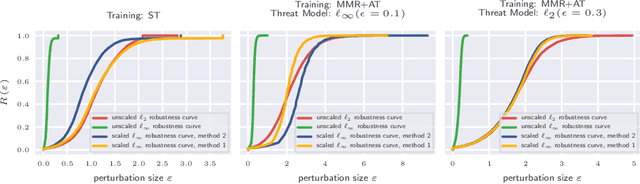
Adversarial robustness of trained models has attracted considerable attention over recent years, within and beyond the scientific community. This is not only because of a straight-forward desire to deploy reliable systems, but also because of how adversarial attacks challenge our beliefs about deep neural networks. Demanding more robust models seems to be the obvious solution -- however, this requires a rigorous understanding of how one should judge adversarial robustness as a property of a given model. In this work, we analyze where adversarial examples occur, in which ways they are peculiar, and how they are processed by robust models. We use robustness curves to show that $\ell_\infty$ threat models are surprisingly effective in improving robustness for other $\ell_p$ norms; we introduce perturbation cost trajectories to provide a broad perspective on how robust and non-robust networks perceive adversarial perturbations as opposed to random perturbations; and we explicitly examine the scale of certain common data sets, showing that robustness thresholds must be adapted to the data set they pertain to. This allows us to provide concrete recommendations for anyone looking to train a robust model or to estimate how much robustness they should require for their operation. The code for all our experiments is available at www.github.com/niklasrisse/adversarial-examples-and-where-to-find-them .
Adversarial Robustness Curves
Jul 31, 2019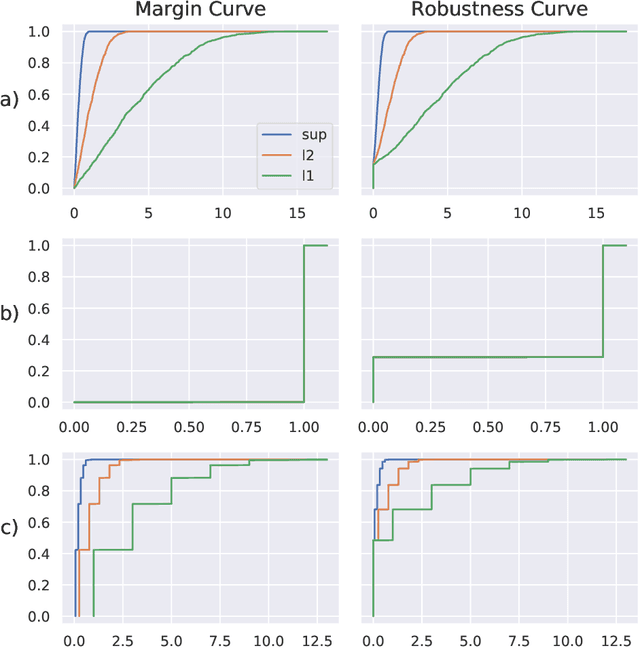
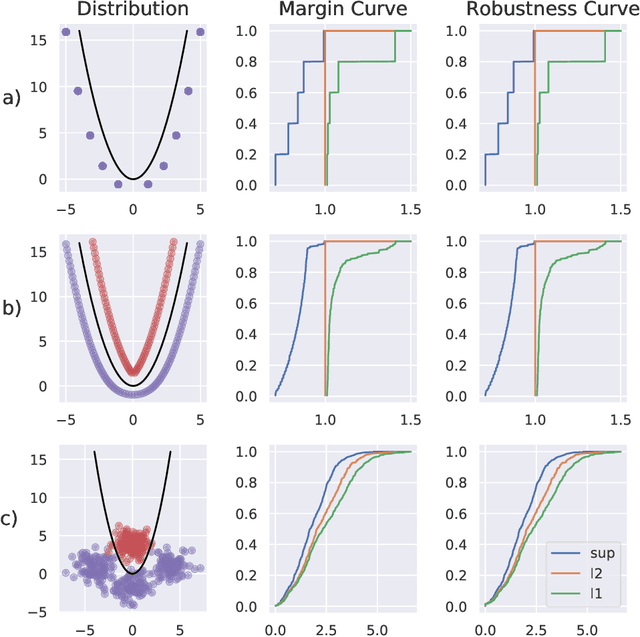
The existence of adversarial examples has led to considerable uncertainty regarding the trust one can justifiably put in predictions produced by automated systems. This uncertainty has, in turn, lead to considerable research effort in understanding adversarial robustness. In this work, we take first steps towards separating robustness analysis from the choice of robustness threshold and norm. We propose robustness curves as a more general view of the robustness behavior of a model and investigate under which circumstances they can qualitatively depend on the chosen norm.
When can unlabeled data improve the learning rate?
May 28, 2019In semi-supervised classification, one is given access both to labeled and unlabeled data. As unlabeled data is typically cheaper to acquire than labeled data, this setup becomes advantageous as soon as one can exploit the unlabeled data in order to produce a better classifier than with labeled data alone. However, the conditions under which such an improvement is possible are not fully understood yet. Our analysis focuses on improvements in the minimax learning rate in terms of the number of labeled examples (with the number of unlabeled examples being allowed to depend on the number of labeled ones). We argue that for such improvements to be realistic and indisputable, certain specific conditions should be satisfied and previous analyses have failed to meet those conditions. We then demonstrate examples where these conditions can be met, in particular showing rate changes from $1/\sqrt{\ell}$ to $e^{-c\ell}$ and from $1/\sqrt{\ell}$ to $1/\ell$. These results improve our understanding of what is and isn't possible in semi-supervised learning.
FRI - Feature Relevance Intervals for Interpretable and Interactive Data Exploration
Mar 02, 2019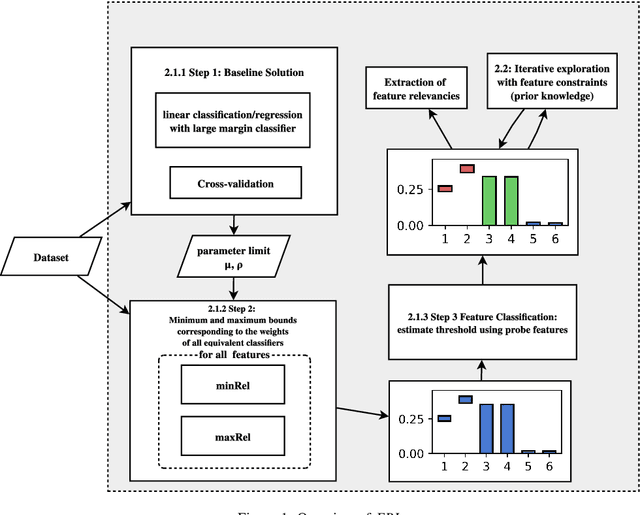

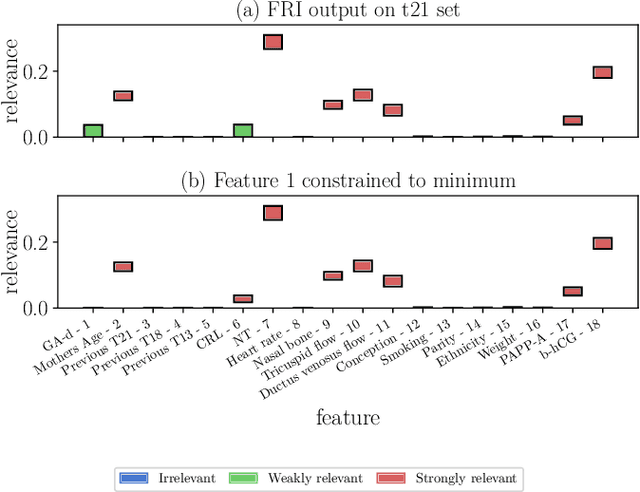

Most existing feature selection methods are insufficient for analytic purposes as soon as high dimensional data or redundant sensor signals are dealt with since features can be selected due to spurious effects or correlations rather than causal effects. To support the finding of causal features in biomedical experiments, we hereby present FRI, an open source Python library that can be used to identify all-relevant variables in linear classification and (ordinal) regression problems. Using the recently proposed feature relevance method, FRI is able to provide the base for further general experimentation or in specific can facilitate the search for alternative biomarkers. It can be used in an interactive context, by providing model manipulation and visualization methods, or in a batch process as a filter method.
Time Series Prediction for Graphs in Kernel and Dissimilarity Spaces
Aug 11, 2017
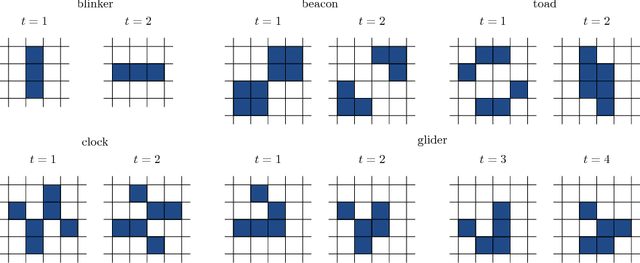
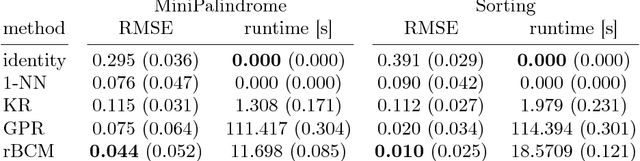

Graph models are relevant in many fields, such as distributed computing, intelligent tutoring systems or social network analysis. In many cases, such models need to take changes in the graph structure into account, i.e. a varying number of nodes or edges. Predicting such changes within graphs can be expected to yield important insight with respect to the underlying dynamics, e.g. with respect to user behaviour. However, predictive techniques in the past have almost exclusively focused on single edges or nodes. In this contribution, we attempt to predict the future state of a graph as a whole. We propose to phrase time series prediction as a regression problem and apply dissimilarity- or kernel-based regression techniques, such as 1-nearest neighbor, kernel regression and Gaussian process regression, which can be applied to graphs via graph kernels. The output of the regression is a point embedded in a pseudo-Euclidean space, which can be analyzed using subsequent dissimilarity- or kernel-based processing methods. We discuss strategies to speed up Gaussian Processes regression from cubic to linear time and evaluate our approach on two well-established theoretical models of graph evolution as well as two real data sets from the domain of intelligent tutoring systems. We find that simple regression methods, such as kernel regression, are sufficient to capture the dynamics in the theoretical models, but that Gaussian process regression significantly improves the prediction error for real-world data.
* preprint of a submission to 'Neural Processing Letters' (Special issue 'Off the mainstream')