 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial examples and where to find them
Paper and Code
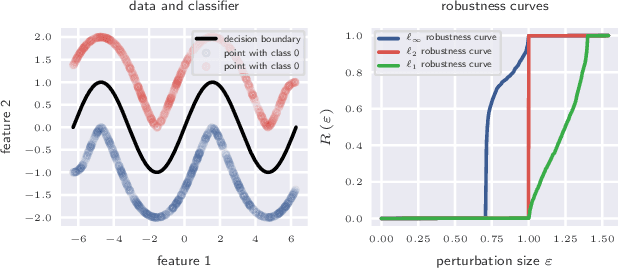
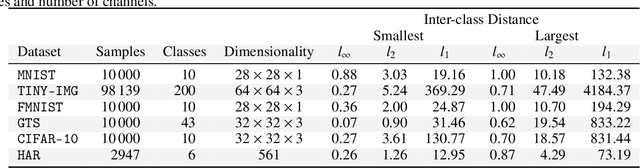
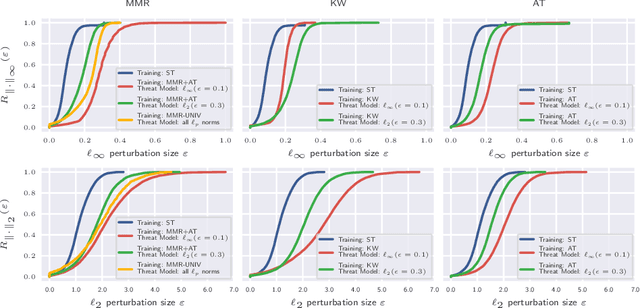
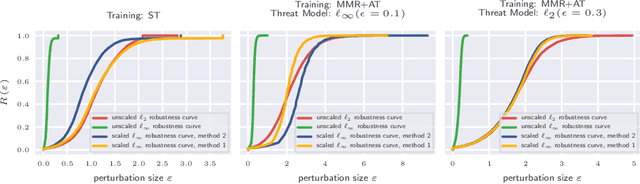
Adversarial robustness of trained models has attracted considerable attention over recent years, within and beyond the scientific community. This is not only because of a straight-forward desire to deploy reliable systems, but also because of how adversarial attacks challenge our beliefs about deep neural networks. Demanding more robust models seems to be the obvious solution -- however, this requires a rigorous understanding of how one should judge adversarial robustness as a property of a given model. In this work, we analyze where adversarial examples occur, in which ways they are peculiar, and how they are processed by robust models. We use robustness curves to show that $\ell_\infty$ threat models are surprisingly effective in improving robustness for other $\ell_p$ norms; we introduce perturbation cost trajectories to provide a broad perspective on how robust and non-robust networks perceive adversarial perturbations as opposed to random perturbations; and we explicitly examine the scale of certain common data sets, showing that robustness thresholds must be adapted to the data set they pertain to. This allows us to provide concrete recommendations for anyone looking to train a robust model or to estimate how much robustness they should require for their operation. The code for all our experiments is available at www.github.com/niklasrisse/adversarial-examples-and-where-to-find-them .