 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpportunities and Risks of LLMs for Scalable Deliberation with Polis
Jun 20, 2023



Polis is a platform that leverages machine intelligence to scale up deliberative processes. In this paper, we explore the opportunities and risks associated with applying Large Language Models (LLMs) towards challenges with facilitating, moderating and summarizing the results of Polis engagements. In particular, we demonstrate with pilot experiments using Anthropic's Claude that LLMs can indeed augment human intelligence to help more efficiently run Polis conversations. In particular, we find that summarization capabilities enable categorically new methods with immense promise to empower the public in collective meaning-making exercises. And notably, LLM context limitations have a significant impact on insight and quality of these results. However, these opportunities come with risks. We discuss some of these risks, as well as principles and techniques for characterizing and mitigating them, and the implications for other deliberative or political systems that may employ LLMs. Finally, we conclude with several open future research directions for augmenting tools like Polis with LLMs.
Discovering Personalized Semantics for Soft Attributes in Recommender Systems using Concept Activation Vectors
Feb 06, 2022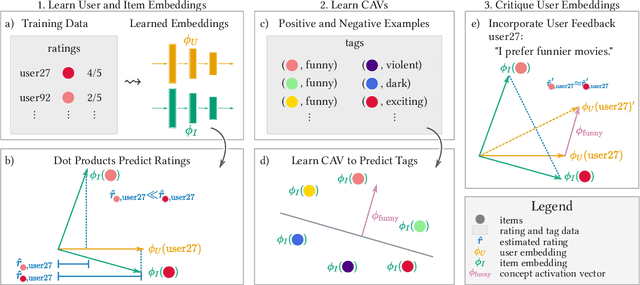


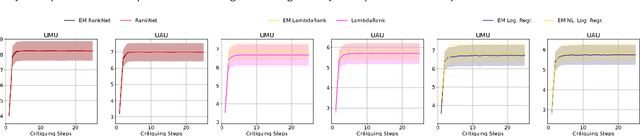
Interactive recommender systems (RSs) allow users to express intent, preferences and contexts in a rich fashion, often using natural language. One challenge in using such feedback is inferring a user's semantic intent from the open-ended terms used to describe an item, and using it to refine recommendation results. Leveraging concept activation vectors (CAVs) [21], we develop a framework to learn a representation that captures the semantics of such attributes and connects them to user preferences and behaviors in RSs. A novel feature of our approach is its ability to distinguish objective and subjective attributes and associate different senses with different users. Using synthetic and real-world datasets, we show that our CAV representation accurately interprets users' subjective semantics, and can improve recommendations via interactive critiquing
What are you optimizing for? Aligning Recommender Systems with Human Values
Jul 22, 2021We describe cases where real recommender systems were modified in the service of various human values such as diversity, fairness, well-being, time well spent, and factual accuracy. From this we identify the current practice of values engineering: the creation of classifiers from human-created data with value-based labels. This has worked in practice for a variety of issues, but problems are addressed one at a time, and users and other stakeholders have seldom been involved. Instead, we look to AI alignment work for approaches that could learn complex values directly from stakeholders, and identify four major directions: useful measures of alignment, participatory design and operation, interactive value learning, and informed deliberative judgments.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021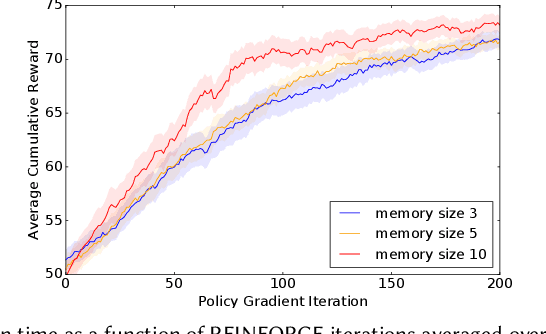
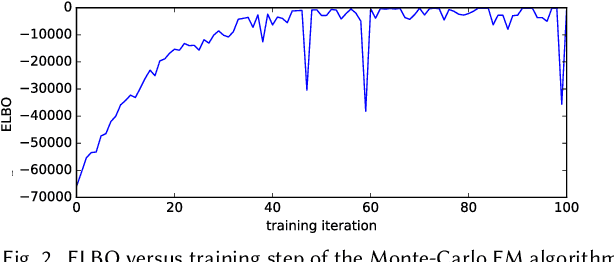
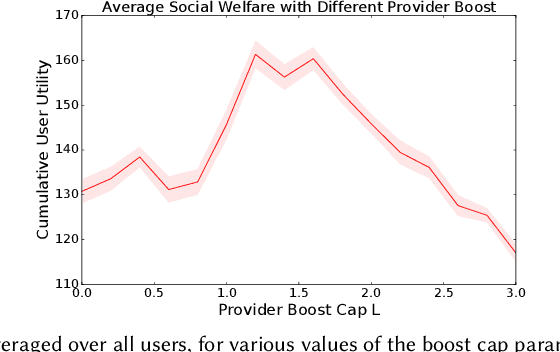
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
Gradient-based Optimization for Bayesian Preference Elicitation
Nov 20, 2019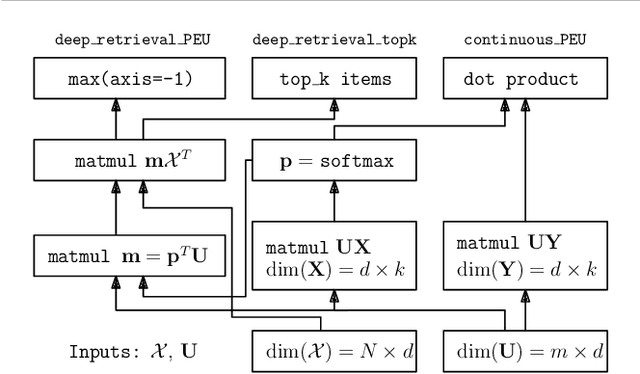

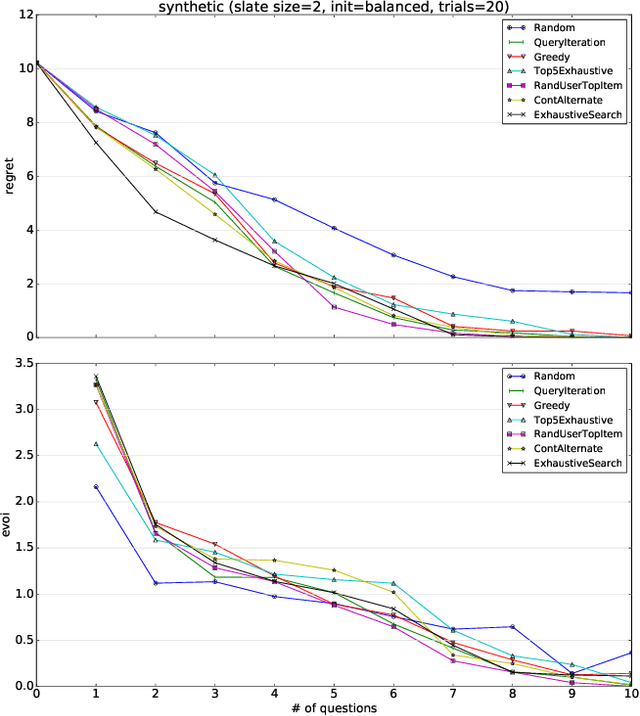

Effective techniques for eliciting user preferences have taken on added importance as recommender systems (RSs) become increasingly interactive and conversational. A common and conceptually appealing Bayesian criterion for selecting queries is expected value of information (EVOI). Unfortunately, it is computationally prohibitive to construct queries with maximum EVOI in RSs with large item spaces. We tackle this issue by introducing a continuous formulation of EVOI as a differentiable network that can be optimized using gradient methods available in modern machine learning (ML) computational frameworks (e.g., TensorFlow, PyTorch). We exploit this to develop a novel, scalable Monte Carlo method for EVOI optimization, which is more scalable for large item spaces than methods requiring explicit enumeration of items. While we emphasize the use of this approach for pairwise (or k-wise) comparisons of items, we also demonstrate how our method can be adapted to queries involving subsets of item attributes or "partial items," which are often more cognitively manageable for users. Experiments show that our gradient-based EVOI technique achieves state-of-the-art performance across several domains while scaling to large item spaces.
Order-Embeddings of Images and Language
Mar 01, 2016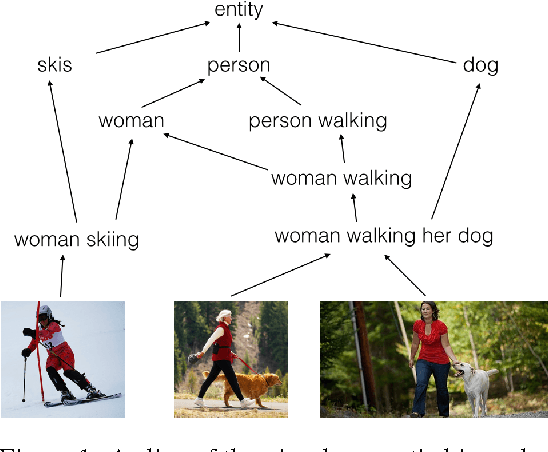

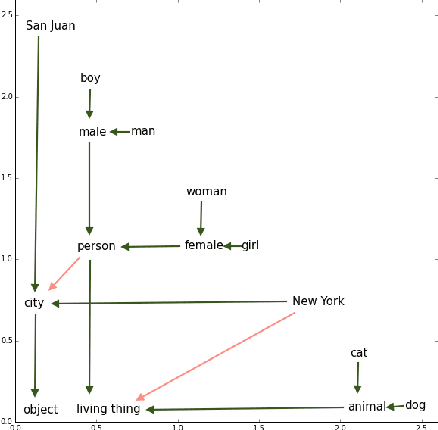
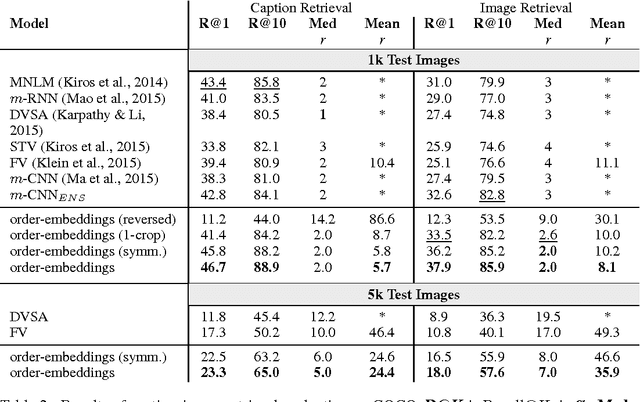
Hypernymy, textual entailment, and image captioning can be seen as special cases of a single visual-semantic hierarchy over words, sentences, and images. In this paper we advocate for explicitly modeling the partial order structure of this hierarchy. Towards this goal, we introduce a general method for learning ordered representations, and show how it can be applied to a variety of tasks involving images and language. We show that the resulting representations improve performance over current approaches for hypernym prediction and image-caption retrieval.