 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Learning via Mutual Information
Sep 21, 2024This paper presents a novel approach to machine learning algorithm design based on information theory, specifically mutual information (MI). We propose a framework for learning and representing functional relationships in data using MI-based features. Our method aims to capture the underlying structure of information in datasets, enabling more efficient and generalizable learning algorithms. We demonstrate the efficacy of our approach through experiments on synthetic and real-world datasets, showing improved performance in tasks such as function classification, regression, and cross-dataset transfer. This work contributes to the growing field of metalearning and automated machine learning, offering a new perspective on how to leverage information theory for algorithm design and dataset analysis and proposing new mutual information theoretic foundations to learning algorithms.
What are you optimizing for? Aligning Recommender Systems with Human Values
Jul 22, 2021We describe cases where real recommender systems were modified in the service of various human values such as diversity, fairness, well-being, time well spent, and factual accuracy. From this we identify the current practice of values engineering: the creation of classifiers from human-created data with value-based labels. This has worked in practice for a variety of issues, but problems are addressed one at a time, and users and other stakeholders have seldom been involved. Instead, we look to AI alignment work for approaches that could learn complex values directly from stakeholders, and identify four major directions: useful measures of alignment, participatory design and operation, interactive value learning, and informed deliberative judgments.
Uncertainty Baselines: Benchmarks for Uncertainty & Robustness in Deep Learning
Jun 07, 2021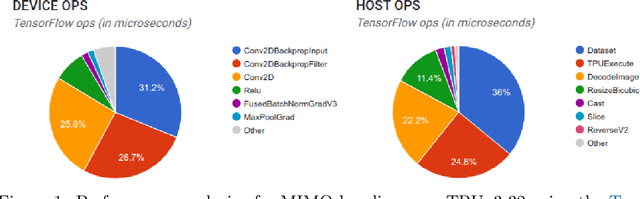
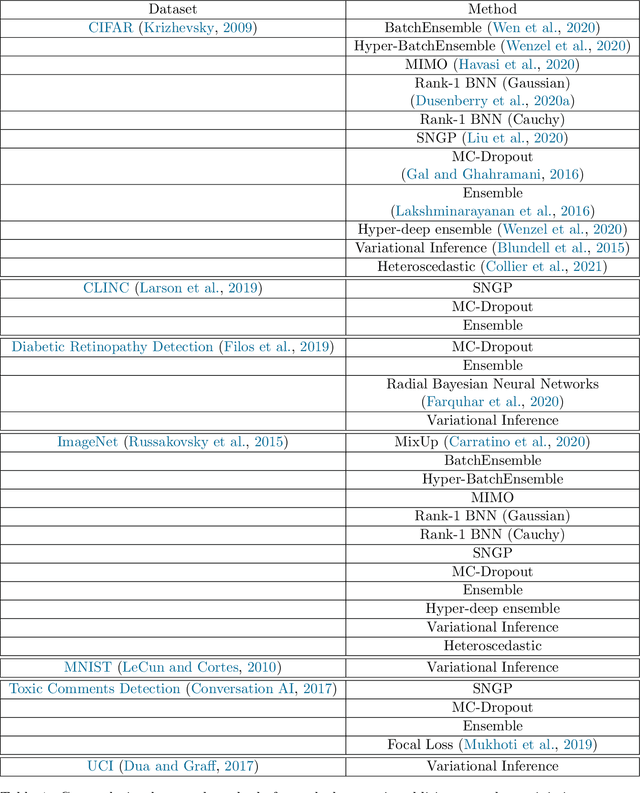
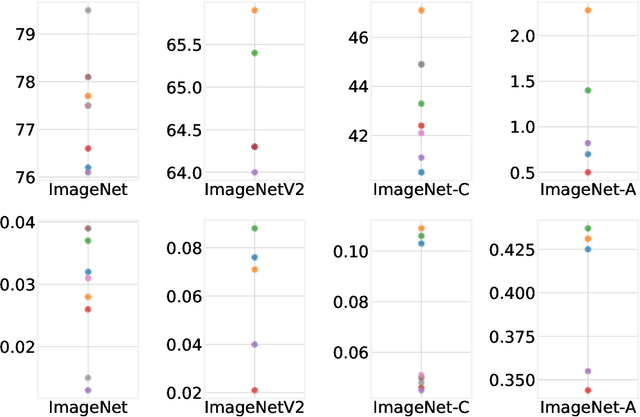
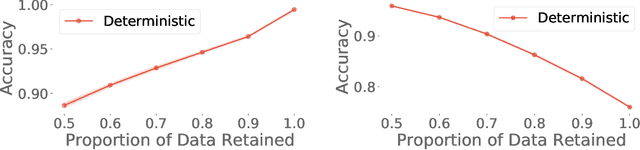
High-quality estimates of uncertainty and robustness are crucial for numerous real-world applications, especially for deep learning which underlies many deployed ML systems. The ability to compare techniques for improving these estimates is therefore very important for research and practice alike. Yet, competitive comparisons of methods are often lacking due to a range of reasons, including: compute availability for extensive tuning, incorporation of sufficiently many baselines, and concrete documentation for reproducibility. In this paper we introduce Uncertainty Baselines: high-quality implementations of standard and state-of-the-art deep learning methods on a variety of tasks. As of this writing, the collection spans 19 methods across 9 tasks, each with at least 5 metrics. Each baseline is a self-contained experiment pipeline with easily reusable and extendable components. Our goal is to provide immediate starting points for experimentation with new methods or applications. Additionally we provide model checkpoints, experiment outputs as Python notebooks, and leaderboards for comparing results. Code available at https://github.com/google/uncertainty-baselines.
Semi-Supervised Class Discovery
Feb 22, 2020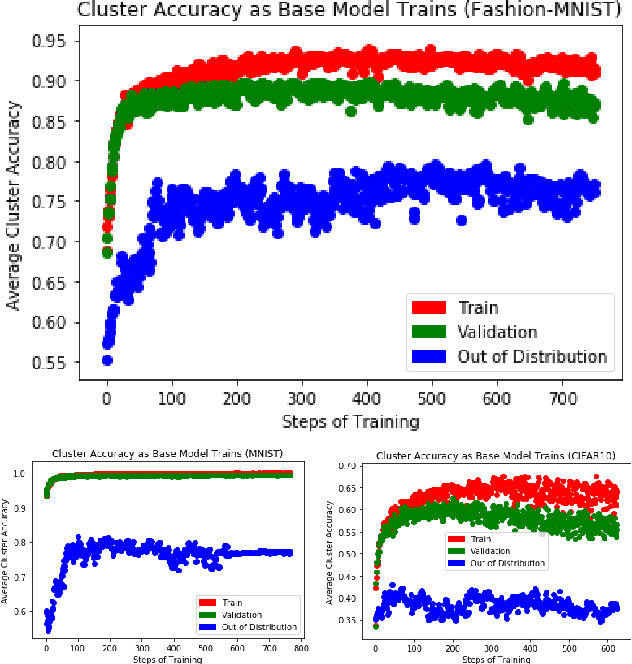
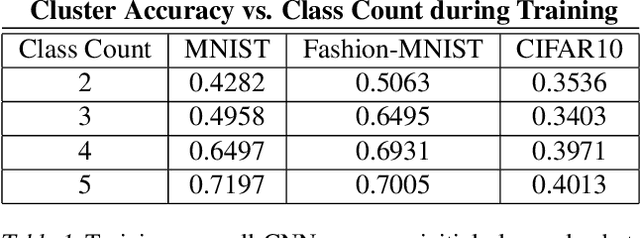
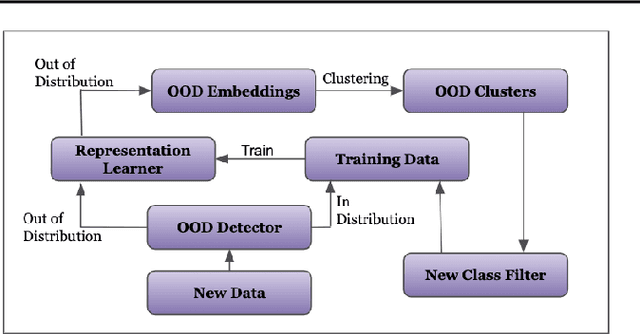
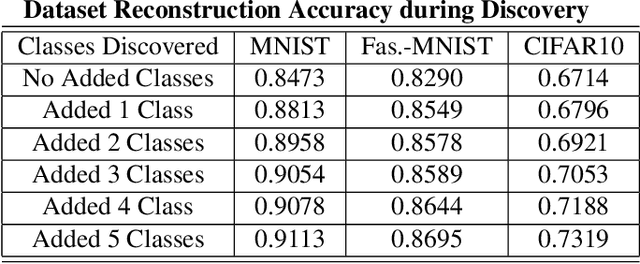
One promising approach to dealing with datapoints that are outside of the initial training distribution (OOD) is to create new classes that capture similarities in the datapoints previously rejected as uncategorizable. Systems that generate labels can be deployed against an arbitrary amount of data, discovering classification schemes that through training create a higher quality representation of data. We introduce the Dataset Reconstruction Accuracy, a new and important measure of the effectiveness of a model's ability to create labels. We introduce benchmarks against this Dataset Reconstruction metric. We apply a new heuristic, class learnability, for deciding whether a class is worthy of addition to the training dataset. We show that our class discovery system can be successfully applied to vision and language, and we demonstrate the value of semi-supervised learning in automatically discovering novel classes.
Resolving Spurious Correlations in Causal Models of Environments via Interventions
Feb 12, 2020Causal models could increase interpretability, robustness to distributional shift and sample efficiency of RL agents. In this vein, we address the question of learning a causal model of an RL environment. This problem is known to be difficult due to spurious correlations. We overcome this difficulty by rewarding an RL agent for designing and executing interventions to discover the true model. We compare rewarding the agent for disproving uncertain edges in the causal graph, rewarding the agent for activating a certain node, or rewarding the agent for increasing the causal graph loss. We show that our methods result in a better causal graph than one generated by following the random policy, or a policy trained on the environment's reward. We find that rewarding for the causal graph loss works the best.
Analyzing the Role of Model Uncertainty for Electronic Health Records
Jun 10, 2019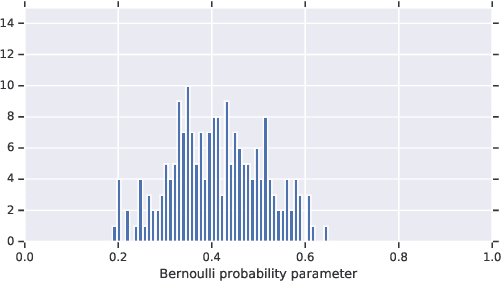
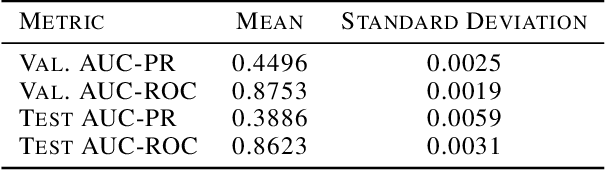
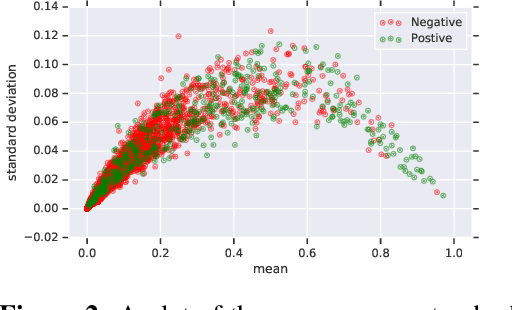
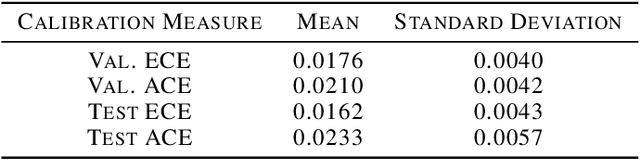
In medicine, both ethical and monetary costs of incorrect predictions can be significant, and the complexity of the problems often necessitates increasingly complex models. Recent work has shown that changing just the random seed is enough for otherwise well-tuned deep neural networks to vary in their individual predicted probabilities. In light of this, we investigate the role of model uncertainty methods in the medical domain. Using RNN ensembles and various Bayesian RNNs, we show that population-level metrics, such as AUC-PR, AUC-ROC, log-likelihood, and calibration error, do not capture model uncertainty. Meanwhile, the presence of significant variability in patient-specific predictions and optimal decisions motivates the need for capturing model uncertainty. Understanding the uncertainty for individual patients is an area with clear clinical impact, such as determining when a model decision is likely to be brittle. We further show that RNNs with only Bayesian embeddings can be a more efficient way to capture model uncertainty compared to ensembles, and we analyze how model uncertainty is impacted across individual input features and patient subgroups.
Measuring Calibration in Deep Learning
Apr 02, 2019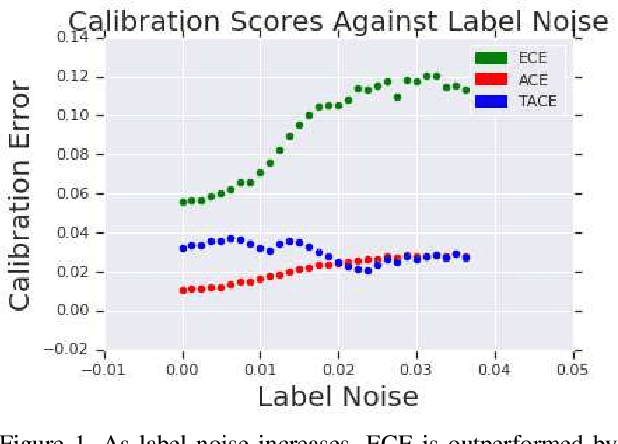
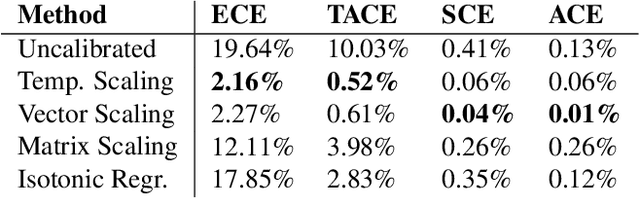
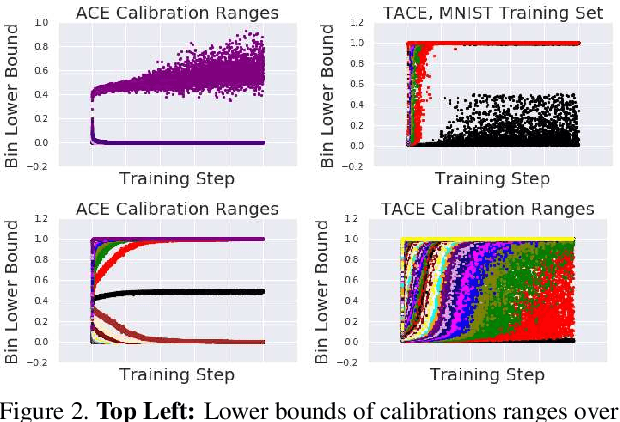
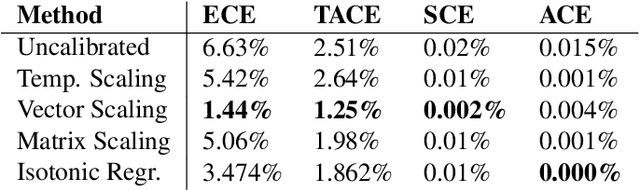
The reliability of a machine learning model's confidence in its predictions is critical for highrisk applications. Calibration-the idea that a model's predicted probabilities of outcomes reflect true probabilities of those outcomes-formalizes this notion. While analyzing the calibration of deep neural networks, we've identified core problems with the way calibration is currently measured. We design the Thresholded Adaptive Calibration Error (TACE) metric to resolve these pathologies and show that it outperforms other metrics, especially in settings where predictions beyond the maximum prediction that is chosen as the output class matter. There are many cases where what a practitioner cares about is the calibration of a specific prediction, and so we introduce a dynamic programming based Prediction Specific Calibration Error (PSCE) that smoothly considers the calibration of nearby predictions to give an estimate of the calibration error of a specific prediction.
Learned optimizers that outperform SGD on wall-clock and test loss
Oct 26, 2018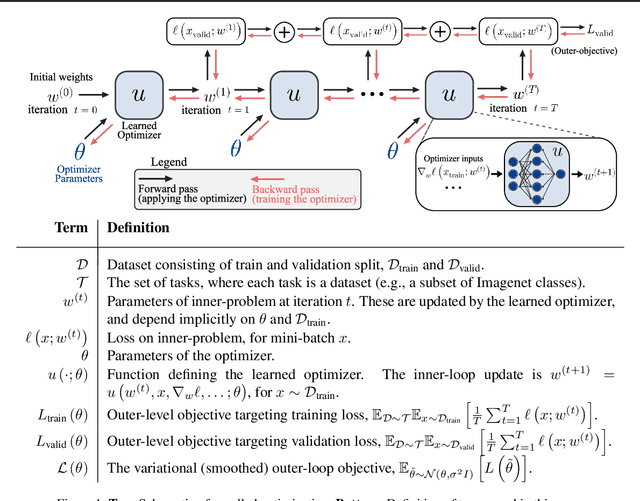
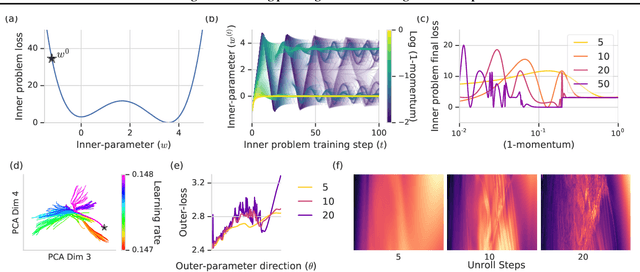
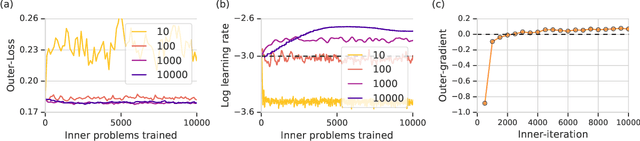
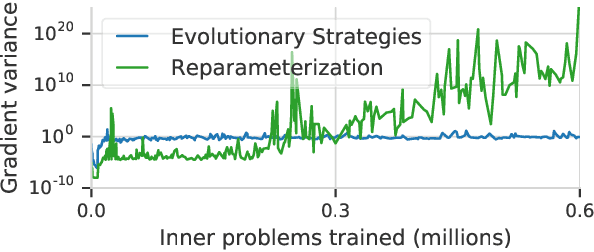
Deep learning has shown that learned functions can dramatically outperform hand-designed functions on perceptual tasks. Analogously, this suggests that learned optimizers may similarly outperform current hand-designed optimizers, especially for specific problems. However, learned optimizers are notoriously difficult to train and have yet to demonstrate wall-clock speedups over hand-designed optimizers, and thus are rarely used in practice. Typically, learned optimizers are trained by truncated backpropagation through an unrolled optimization process. The resulting gradients are either strongly biased (for short truncations) or have exploding norm (for long truncations). In this work we propose a training scheme which overcomes both of these difficulties, by dynamically weighting two unbiased gradient estimators for a variational loss on optimizer performance. This allows us to train neural networks to perform optimization of a specific task faster than well tuned first-order methods. Moreover, by training the optimizer against validation loss (as opposed to training loss), we are able to learn optimizers that train networks to better generalization than first order methods. We demonstrate these results on problems where our learned optimizer trains convolutional networks in a fifth of the wall-clock time compared to tuned first-order methods, and with an improvement in test loss.