 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Class Discovery
Paper and Code
Feb 22, 2020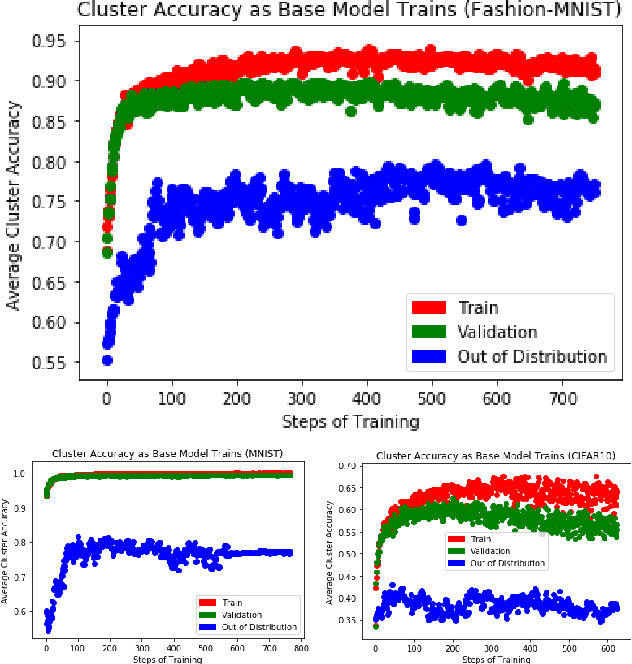
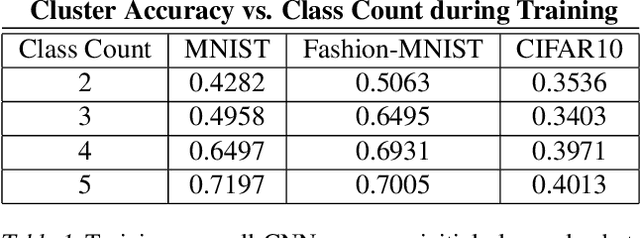
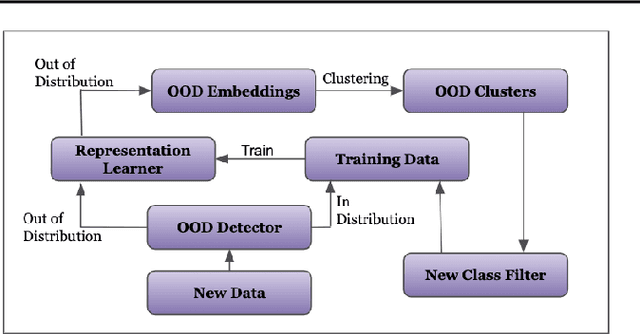
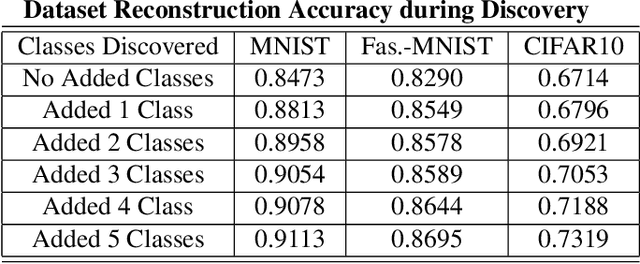
One promising approach to dealing with datapoints that are outside of the initial training distribution (OOD) is to create new classes that capture similarities in the datapoints previously rejected as uncategorizable. Systems that generate labels can be deployed against an arbitrary amount of data, discovering classification schemes that through training create a higher quality representation of data. We introduce the Dataset Reconstruction Accuracy, a new and important measure of the effectiveness of a model's ability to create labels. We introduce benchmarks against this Dataset Reconstruction metric. We apply a new heuristic, class learnability, for deciding whether a class is worthy of addition to the training dataset. We show that our class discovery system can be successfully applied to vision and language, and we demonstrate the value of semi-supervised learning in automatically discovering novel classes.