 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
AI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
Summon a Demon and Bind it: A Grounded Theory of LLM Red Teaming in the Wild
Nov 13, 2023



Engaging in the deliberate generation of abnormal outputs from large language models (LLMs) by attacking them is a novel human activity. This paper presents a thorough exposition of how and why people perform such attacks. Using a formal qualitative methodology, we interviewed dozens of practitioners from a broad range of backgrounds, all contributors to this novel work of attempting to cause LLMs to fail. We relate and connect this activity between its practitioners' motivations and goals; the strategies and techniques they deploy; and the crucial role the community plays. As a result, this paper presents a grounded theory of how and why people attack large language models: LLM red teaming in the wild.
Building Human Values into Recommender Systems: An Interdisciplinary Synthesis
Jul 20, 2022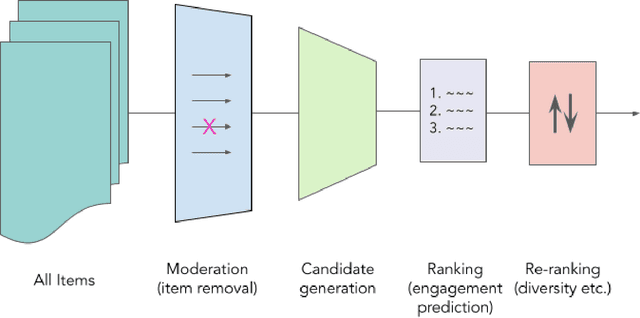
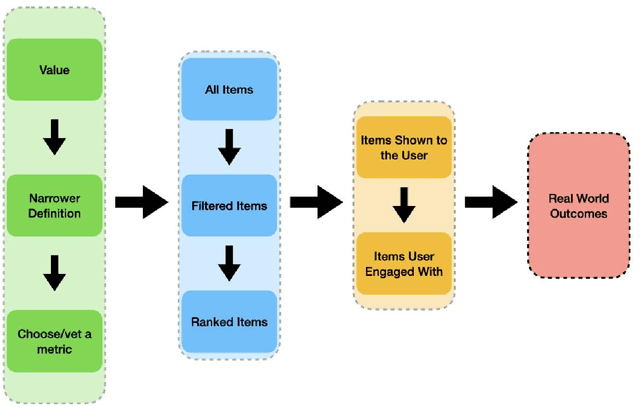

Recommender systems are the algorithms which select, filter, and personalize content across many of the worlds largest platforms and apps. As such, their positive and negative effects on individuals and on societies have been extensively theorized and studied. Our overarching question is how to ensure that recommender systems enact the values of the individuals and societies that they serve. Addressing this question in a principled fashion requires technical knowledge of recommender design and operation, and also critically depends on insights from diverse fields including social science, ethics, economics, psychology, policy and law. This paper is a multidisciplinary effort to synthesize theory and practice from different perspectives, with the goal of providing a shared language, articulating current design approaches, and identifying open problems. It is not a comprehensive survey of this large space, but a set of highlights identified by our diverse author cohort. We collect a set of values that seem most relevant to recommender systems operating across different domains, then examine them from the perspectives of current industry practice, measurement, product design, and policy approaches. Important open problems include multi-stakeholder processes for defining values and resolving trade-offs, better values-driven measurements, recommender controls that people use, non-behavioral algorithmic feedback, optimization for long-term outcomes, causal inference of recommender effects, academic-industry research collaborations, and interdisciplinary policy-making.
What are you optimizing for? Aligning Recommender Systems with Human Values
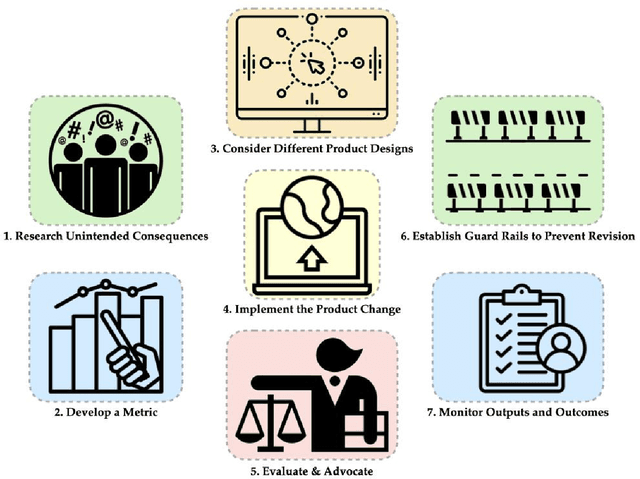
Jul 22, 2021We describe cases where real recommender systems were modified in the service of various human values such as diversity, fairness, well-being, time well spent, and factual accuracy. From this we identify the current practice of values engineering: the creation of classifiers from human-created data with value-based labels. This has worked in practice for a variety of issues, but problems are addressed one at a time, and users and other stakeholders have seldom been involved. Instead, we look to AI alignment work for approaches that could learn complex values directly from stakeholders, and identify four major directions: useful measures of alignment, participatory design and operation, interactive value learning, and informed deliberative judgments.
Designing Recommender Systems to Depolarize
Jul 11, 2021Polarization is implicated in the erosion of democracy and the progression to violence, which makes the polarization properties of large algorithmic content selection systems (recommender systems) a matter of concern for peace and security. While algorithm-driven social media does not seem to be a primary driver of polarization at the country level, it could be a useful intervention point in polarized societies. This paper examines algorithmic depolarization interventions with the goal of conflict transformation: not suppressing or eliminating conflict but moving towards more constructive conflict. Algorithmic intervention is considered at three stages: which content is available (moderation), how content is selected and personalized (ranking), and content presentation and controls (user interface). Empirical studies of online conflict suggest that the exposure diversity intervention proposed as an antidote to "filter bubbles" can be improved and can even worsen polarization under some conditions. Using civility metrics in conjunction with diversity in content selection may be more effective. However, diversity-based interventions have not been tested at scale and may not work in the diverse and dynamic contexts of real platforms. Instead, intervening in platform polarization dynamics will likely require continuous monitoring of polarization metrics, such as the widely used "feeling thermometer." These metrics can be used to evaluate product features, and potentially engineered as algorithmic objectives. It may further prove necessary to include polarization measures in the objective functions of recommender algorithms to prevent optimization processes from creating conflict as a side effect.