 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Delegates to Trustees: How Optimizing for Long-Term Interests Shapes Bias and Alignment in LLM
Oct 14, 2025



Large language models (LLMs) have shown promising accuracy in predicting survey responses and policy preferences, which has increased interest in their potential to represent human interests in various domains. Most existing research has focused on behavioral cloning, effectively evaluating how well models reproduce individuals' expressed preferences. Drawing on theories of political representation, we highlight an underexplored design trade-off: whether AI systems should act as delegates, mirroring expressed preferences, or as trustees, exercising judgment about what best serves an individual's interests. This trade-off is closely related to issues of LLM sycophancy, where models can encourage behavior or validate beliefs that may be aligned with a user's short-term preferences, but is detrimental to their long-term interests. Through a series of experiments simulating votes on various policy issues in the U.S. context, we apply a temporal utility framework that weighs short and long-term interests (simulating a trustee role) and compare voting outcomes to behavior-cloning models (simulating a delegate). We find that trustee-style predictions weighted toward long-term interests produce policy decisions that align more closely with expert consensus on well-understood issues, but also show greater bias toward models' default stances on topics lacking clear agreement. These findings reveal a fundamental trade-off in designing AI systems to represent human interests. Delegate models better preserve user autonomy but may diverge from well-supported policy positions, while trustee models can promote welfare on well-understood issues yet risk paternalism and bias on subjective topics.
Community Moderation and the New Epistemology of Fact Checking on Social Media
May 26, 2025Social media platforms have traditionally relied on internal moderation teams and partnerships with independent fact-checking organizations to identify and flag misleading content. Recently, however, platforms including X (formerly Twitter) and Meta have shifted towards community-driven content moderation by launching their own versions of crowd-sourced fact-checking -- Community Notes. If effectively scaled and governed, such crowd-checking initiatives have the potential to combat misinformation with increased scale and speed as successfully as community-driven efforts once did with spam. Nevertheless, general content moderation, especially for misinformation, is inherently more complex. Public perceptions of truth are often shaped by personal biases, political leanings, and cultural contexts, complicating consensus on what constitutes misleading content. This suggests that community efforts, while valuable, cannot replace the indispensable role of professional fact-checkers. Here we systemically examine the current approaches to misinformation detection across major platforms, explore the emerging role of community-driven moderation, and critically evaluate both the promises and challenges of crowd-checking at scale.
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Tell Me Why: Incentivizing Explanations
Feb 19, 2025Common sense suggests that when individuals explain why they believe something, we can arrive at more accurate conclusions than when they simply state what they believe. Yet, there is no known mechanism that provides incentives to elicit explanations for beliefs from agents. This likely stems from the fact that standard Bayesian models make assumptions (like conditional independence of signals) that preempt the need for explanations, in order to show efficient information aggregation. A natural justification for the value of explanations is that agents' beliefs tend to be drawn from overlapping sources of information, so agents' belief reports do not reveal all that needs to be known. Indeed, this work argues that rationales-explanations of an agent's private information-lead to more efficient aggregation by allowing agents to efficiently identify what information they share and what information is new. Building on this model of rationales, we present a novel 'deliberation mechanism' to elicit rationales from agents in which truthful reporting of beliefs and rationales is a perfect Bayesian equilibrium.
AI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
Sherlock: A Deep Learning Approach to Semantic Data Type Detection
May 25, 2019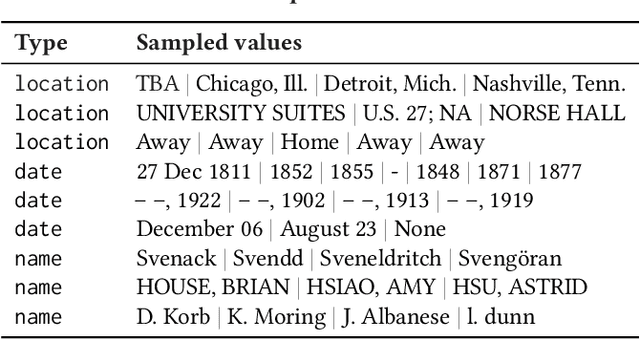
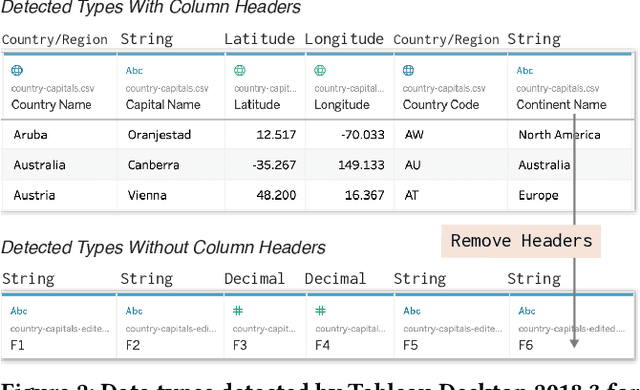
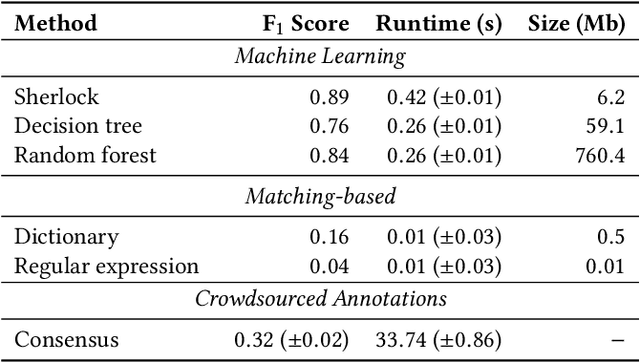

Correctly detecting the semantic type of data columns is crucial for data science tasks such as automated data cleaning, schema matching, and data discovery. Existing data preparation and analysis systems rely on dictionary lookups and regular expression matching to detect semantic types. However, these matching-based approaches often are not robust to dirty data and only detect a limited number of types. We introduce Sherlock, a multi-input deep neural network for detecting semantic types. We train Sherlock on $686,765$ data columns retrieved from the VizNet corpus by matching $78$ semantic types from DBpedia to column headers. We characterize each matched column with $1,588$ features describing the statistical properties, character distributions, word embeddings, and paragraph vectors of column values. Sherlock achieves a support-weighted F$_1$ score of $0.89$, exceeding that of machine learning baselines, dictionary and regular expression benchmarks, and the consensus of crowdsourced annotations.
VizNet: Towards A Large-Scale Visualization Learning and Benchmarking Repository
May 12, 2019
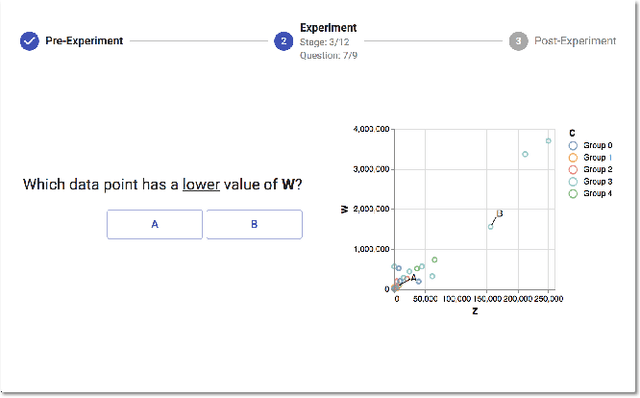

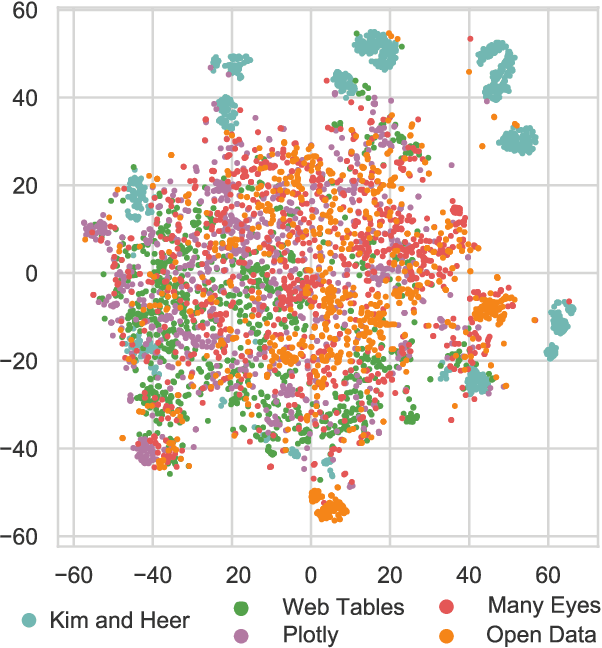
Researchers currently rely on ad hoc datasets to train automated visualization tools and evaluate the effectiveness of visualization designs. These exemplars often lack the characteristics of real-world datasets, and their one-off nature makes it difficult to compare different techniques. In this paper, we present VizNet: a large-scale corpus of over 31 million datasets compiled from open data repositories and online visualization galleries. On average, these datasets comprise 17 records over 3 dimensions and across the corpus, we find 51% of the dimensions record categorical data, 44% quantitative, and only 5% temporal. VizNet provides the necessary common baseline for comparing visualization design techniques, and developing benchmark models and algorithms for automating visual analysis. To demonstrate VizNet's utility as a platform for conducting online crowdsourced experiments at scale, we replicate a prior study assessing the influence of user task and data distribution on visual encoding effectiveness, and extend it by considering an additional task: outlier detection. To contend with running such studies at scale, we demonstrate how a metric of perceptual effectiveness can be learned from experimental results, and show its predictive power across test datasets.
Active Fairness in Algorithmic Decision Making
Sep 28, 2018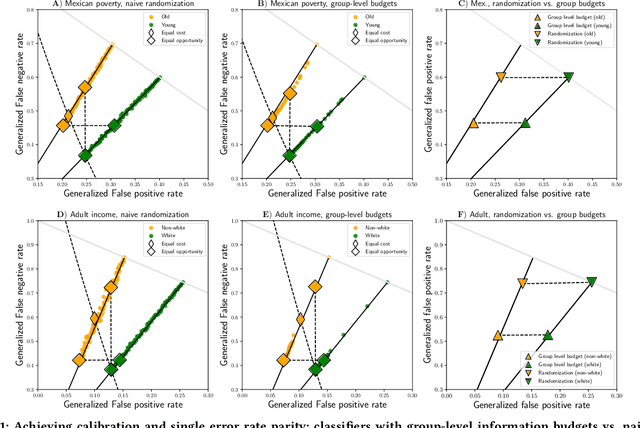
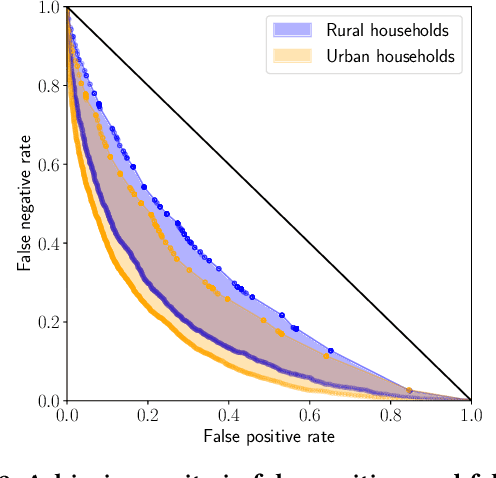

Society increasingly relies on machine learning models for automated decision making. Yet, efficiency gains from automation have come paired with concern for algorithmic discrimination that can systematize inequality. Substantial work in algorithmic fairness has surged, focusing on either post-processing trained models, constraining learning processes, or pre-processing training data. Recent work has proposed optimal post-processing methods that randomize classification decisions on a fraction of individuals in order to achieve fairness measures related to parity in errors and calibration. These methods, however, have raised concern due to the information inefficiency, intra-group unfairness, and Pareto sub-optimality they entail. The present work proposes an alternative active framework for fair classification, where, in deployment, a decision-maker adaptively acquires information according to the needs of different groups or individuals, towards balancing disparities in classification performance. We propose two such methods, where information collection is adapted to group- and individual-level needs respectively. We show on real-world datasets that these can achieve: 1) calibration and single error parity (e.g., equal opportunity); and 2) parity in both false positive and false negative rates (i.e., equal odds). Moreover, we show that, by leveraging their additional degree of freedom, active approaches can outperform randomization-based classifiers previously considered optimal, while also avoiding limitations such as intra-group unfairness.