 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Fairness in Algorithmic Decision Making
Paper and Code
Sep 28, 2018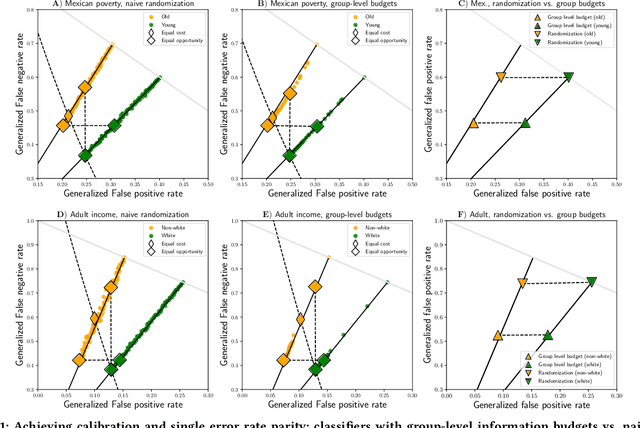
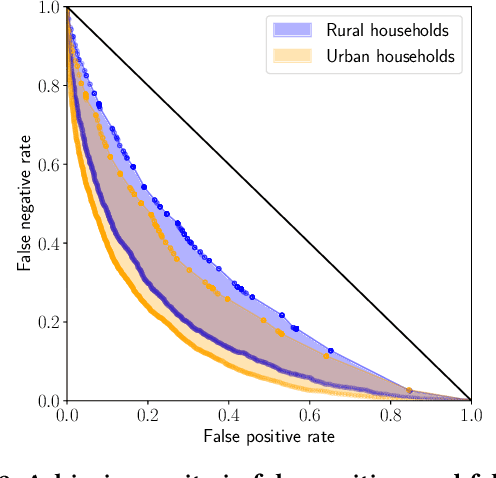

Society increasingly relies on machine learning models for automated decision making. Yet, efficiency gains from automation have come paired with concern for algorithmic discrimination that can systematize inequality. Substantial work in algorithmic fairness has surged, focusing on either post-processing trained models, constraining learning processes, or pre-processing training data. Recent work has proposed optimal post-processing methods that randomize classification decisions on a fraction of individuals in order to achieve fairness measures related to parity in errors and calibration. These methods, however, have raised concern due to the information inefficiency, intra-group unfairness, and Pareto sub-optimality they entail. The present work proposes an alternative active framework for fair classification, where, in deployment, a decision-maker adaptively acquires information according to the needs of different groups or individuals, towards balancing disparities in classification performance. We propose two such methods, where information collection is adapted to group- and individual-level needs respectively. We show on real-world datasets that these can achieve: 1) calibration and single error parity (e.g., equal opportunity); and 2) parity in both false positive and false negative rates (i.e., equal odds). Moreover, we show that, by leveraging their additional degree of freedom, active approaches can outperform randomization-based classifiers previously considered optimal, while also avoiding limitations such as intra-group unfairness.