 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecastBench-Sim: A Simulated-World Forecasting Benchmark
Jun 17, 2026Forecasting benchmarks for general-purpose AI systems usually inherit the constraints of the real world: outcomes resolve slowly, tail events are rare, and counterfactual questions are difficult to score. We introduce ForecastBench-Sim, a simulated-world forecasting benchmark built on game rollouts from Freeciv, a turn-based strategy game modelled on the Civilization series. Forecasters receive a fixed world report (a structured snapshot of the current game state) and answer questions about hidden future states; the benchmark then continues the simulation and scores forecasts. Because the world is simulated, the same setup can generate continuous or binary forecasting questions at arbitrary time horizons, paired intervention worlds for conditional or causal questions, and resolved examples of rare or disruptive outcomes. We describe the benchmark pipeline, question families, scoring protocol, and release artifacts, and report validation slices from model evaluations and an anonymized human pilot. ForecastBench-Sim is intended to complement real-world forecasting benchmarks by providing controlled, immediately resolvable tasks for studying probabilistic reasoning under dynamic world states.
Is Capability a Liability? More Capable Language Models Make Worse Forecasts When It Matters Most
May 21, 2026We document inverse scaling in LLMs on forecasting problems whose underlying time series exhibit superlinear growth and tail risk of regime change, a structure common in finance and epidemiology. On these tasks, more capable models produce worse distributional forecasts. The pattern appears on ForecastBench-Sim (FBSim), a contamination-free, simulated-world benchmark we release, in forecasting synthetic SIR epidemics with a matched linear control, and replicates in real-world datasets on COVID-19, measles, housing markets, and hyperinflation. A per-quantile decomposition shows the failure concentrates at the upper tail, which more capable models shift upward to track aggressive extrapolations of growth, while the lower tail stays put. A within-family study of Llama-3.1 shows that both model scale and post-training independently contribute to this effect. Domain knowledge does not reliably rescue calibration. This inverse scaling does not appear on single-threshold metrics common in LLM forecasting benchmarks, reversing the sign of the capability--accuracy relationship on identical outputs. Single-threshold scoring at conventional cutoffs misses the upper-tail cost; tail-inclusive scoring reverses the sign of the capability--accuracy relationship on the same outputs. We recommend that LLM forecasting evaluations use continuous (and unbounded) measures of accuracy alongside bounded binary threshold metrics.
WOMAC: A Mechanism For Prediction Competitions
Aug 25, 2025Competitions are widely used to identify top performers in judgmental forecasting and machine learning, and the standard competition design ranks competitors based on their cumulative scores against a set of realized outcomes or held-out labels. However, this standard design is neither incentive-compatible nor very statistically efficient. The main culprit is noise in outcomes/labels that experts are scored against; it allows weaker competitors to often win by chance, and the winner-take-all nature incentivizes misreporting that improves win probability even if it decreases expected score. Attempts to achieve incentive-compatibility rely on randomized mechanisms that add even more noise in winner selection, but come at the cost of determinism and practical adoption. To tackle these issues, we introduce a novel deterministic mechanism: WOMAC (Wisdom of the Most Accurate Crowd). Instead of scoring experts against noisy outcomes, as is standard, WOMAC scores experts against the best ex-post aggregate of peer experts' predictions given the noisy outcomes. WOMAC is also more efficient than the standard competition design in typical settings. While the increased complexity of WOMAC makes it challenging to analyze incentives directly, we provide a clear theoretical foundation to justify the mechanism. We also provide an efficient vectorized implementation and demonstrate empirically on real-world forecasting datasets that WOMAC is a more reliable predictor of experts' out-of-sample performance relative to the standard mechanism. WOMAC is useful in any competition where there is substantial noise in the outcomes/labels.
Large Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025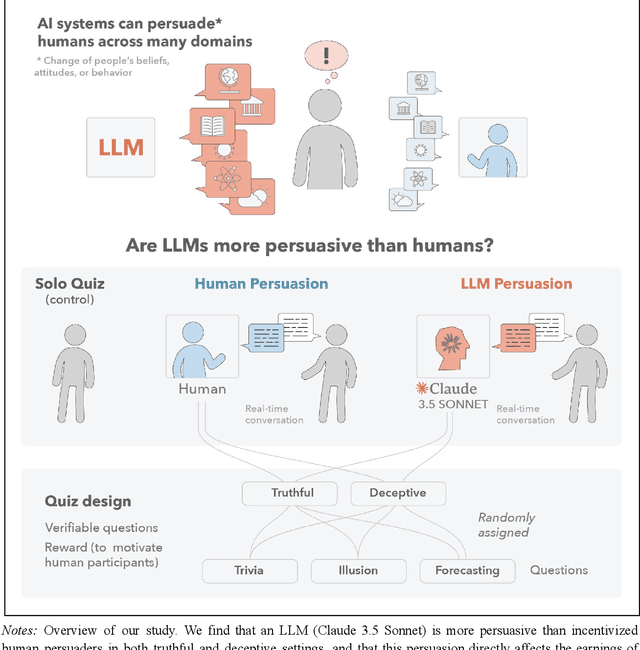
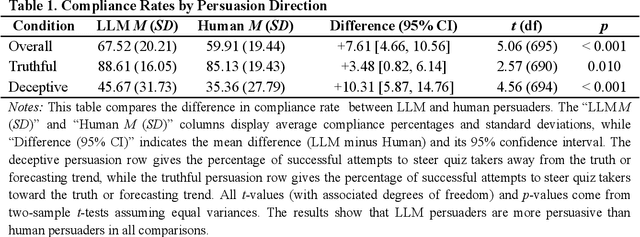
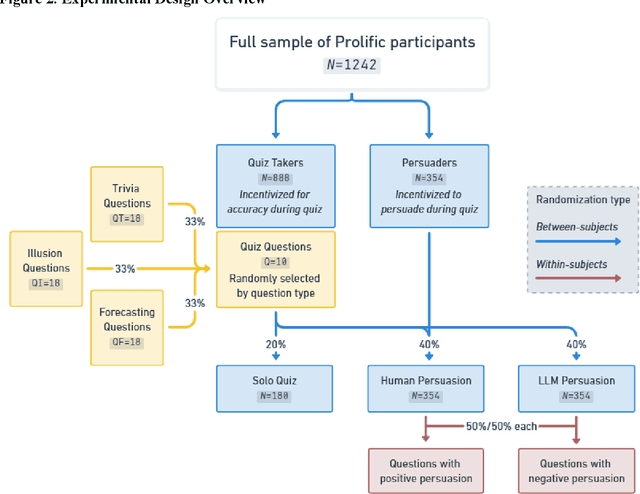
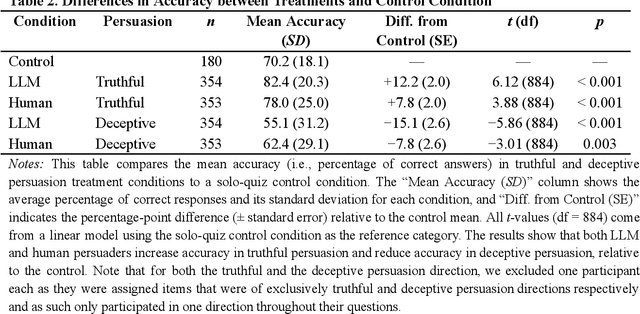
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Tell Me Why: Incentivizing Explanations
Feb 19, 2025Common sense suggests that when individuals explain why they believe something, we can arrive at more accurate conclusions than when they simply state what they believe. Yet, there is no known mechanism that provides incentives to elicit explanations for beliefs from agents. This likely stems from the fact that standard Bayesian models make assumptions (like conditional independence of signals) that preempt the need for explanations, in order to show efficient information aggregation. A natural justification for the value of explanations is that agents' beliefs tend to be drawn from overlapping sources of information, so agents' belief reports do not reveal all that needs to be known. Indeed, this work argues that rationales-explanations of an agent's private information-lead to more efficient aggregation by allowing agents to efficiently identify what information they share and what information is new. Building on this model of rationales, we present a novel 'deliberation mechanism' to elicit rationales from agents in which truthful reporting of beliefs and rationales is a perfect Bayesian equilibrium.
ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities
Sep 30, 2024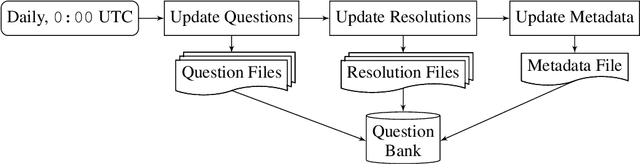
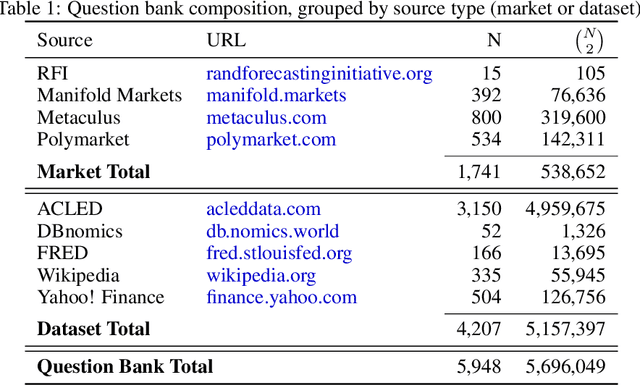
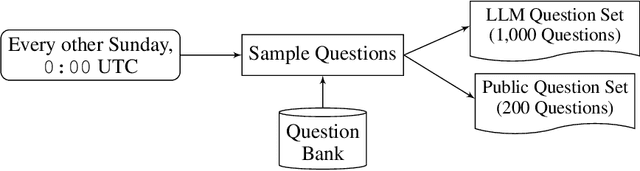
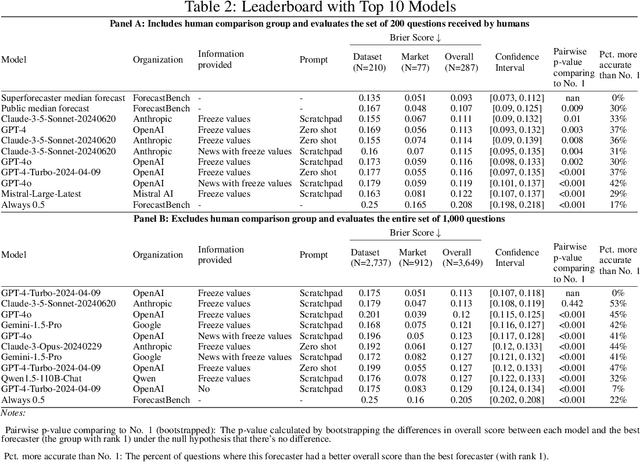
Forecasts of future events are essential inputs into informed decision-making. Machine learning (ML) systems have the potential to deliver forecasts at scale, but there is no framework for evaluating the accuracy of ML systems on a standardized set of forecasting questions. To address this gap, we introduce ForecastBench: a dynamic benchmark that evaluates the accuracy of ML systems on an automatically generated and regularly updated set of 1,000 forecasting questions. To avoid any possibility of data leakage, ForecastBench is comprised solely of questions about future events that have no known answer at the time of submission. We quantify the ability of current ML systems by collecting forecasts from expert (human) forecasters, the general public, and LLMs on a random subset of questions from the benchmark (N = 200). While LLMs have achieved super-human performance on many benchmarks, they perform less well here: expert forecasters outperform the top-performing LLM (p-values <= 0.01). We display system and human scores in a public leaderboard at www.forecastbench.org.
AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy
Feb 12, 2024
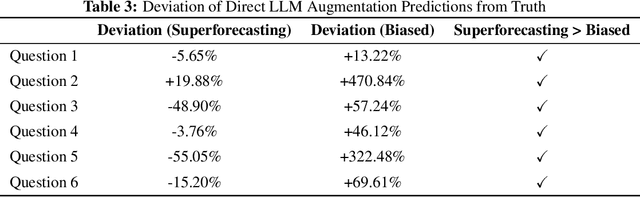
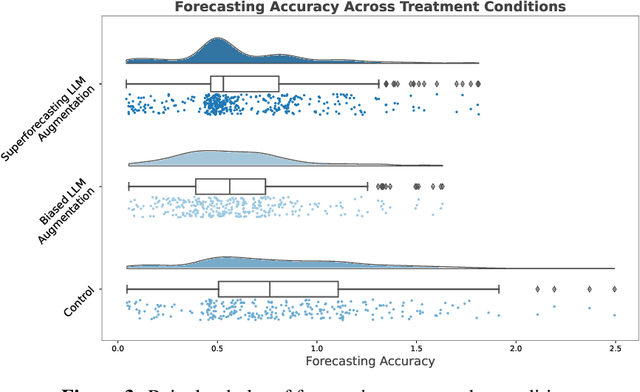
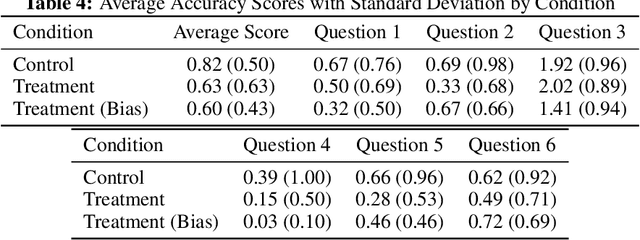
Large language models (LLMs) show impressive capabilities, matching and sometimes exceeding human performance in many domains. This study explores the potential of LLMs to augment judgement in forecasting tasks. We evaluated the impact on forecasting accuracy of two GPT-4-Turbo assistants: one designed to provide high-quality advice ('superforecasting'), and the other designed to be overconfident and base-rate-neglecting. Participants (N = 991) had the option to consult their assigned LLM assistant throughout the study, in contrast to a control group that used a less advanced model (DaVinci-003) without direct forecasting support. Our preregistered analyses reveal that LLM augmentation significantly enhances forecasting accuracy by 23% across both types of assistants, compared to the control group. This improvement occurs despite the superforecasting assistant's higher accuracy in predictions, indicating the augmentation's benefit is not solely due to model prediction accuracy. Exploratory analyses showed a pronounced effect in one forecasting item, without which we find that the superforecasting assistant increased accuracy by 43%, compared with 28% for the biased assistant. We further examine whether LLM augmentation disproportionately benefits less skilled forecasters, degrades the wisdom-of-the-crowd by reducing prediction diversity, or varies in effectiveness with question difficulty. Our findings do not consistently support these hypotheses. Our results suggest that access to an LLM assistant, even a biased one, can be a helpful decision aid in cognitively demanding tasks where the answer is not known at the time of interaction.