 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities
Sep 30, 2024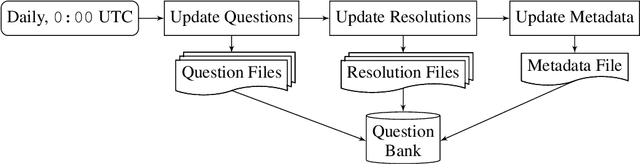
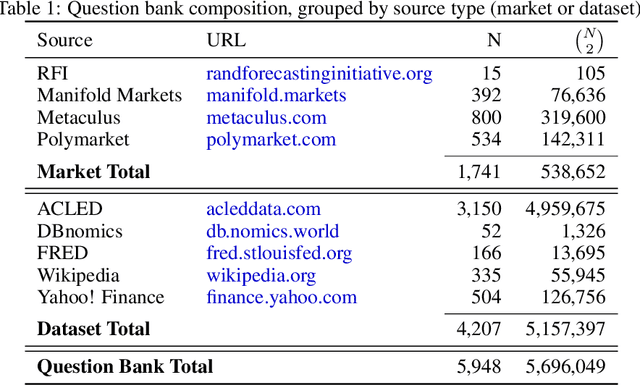
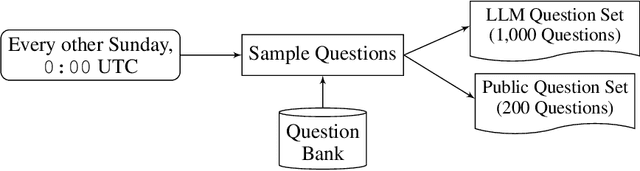
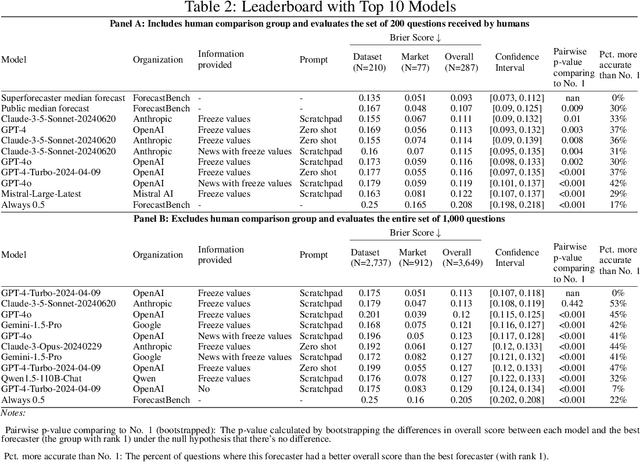
Forecasts of future events are essential inputs into informed decision-making. Machine learning (ML) systems have the potential to deliver forecasts at scale, but there is no framework for evaluating the accuracy of ML systems on a standardized set of forecasting questions. To address this gap, we introduce ForecastBench: a dynamic benchmark that evaluates the accuracy of ML systems on an automatically generated and regularly updated set of 1,000 forecasting questions. To avoid any possibility of data leakage, ForecastBench is comprised solely of questions about future events that have no known answer at the time of submission. We quantify the ability of current ML systems by collecting forecasts from expert (human) forecasters, the general public, and LLMs on a random subset of questions from the benchmark (N = 200). While LLMs have achieved super-human performance on many benchmarks, they perform less well here: expert forecasters outperform the top-performing LLM (p-values <= 0.01). We display system and human scores in a public leaderboard at www.forecastbench.org.
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
Mar 06, 2024



Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human crowd forecasting tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of twelve LLMs. We compare the aggregated LLM predictions on 31 binary questions to that of a crowd of 925 human forecasters from a three-month forecasting tournament. Our preregistered main analysis shows that the LLM crowd outperforms a simple no-information benchmark and is not statistically different from the human crowd. In exploratory analyses, we find that these two approaches are equivalent with respect to medium-effect-size equivalence bounds. We also observe an acquiescence effect, with mean model predictions being significantly above 50%, despite an almost even split of positive and negative resolutions. Moreover, in Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%: though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of human crowd forecasting tournaments: via the simple, practically applicable method of forecast aggregation. This replicates the 'wisdom of the crowd' effect for LLMs, and opens up their use for a variety of applications throughout society.
AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy
Feb 12, 2024
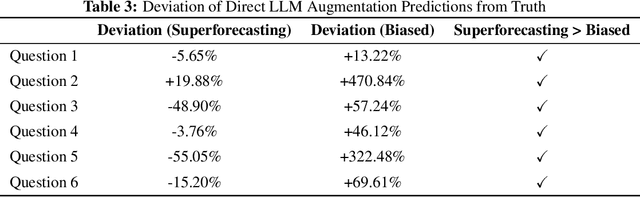
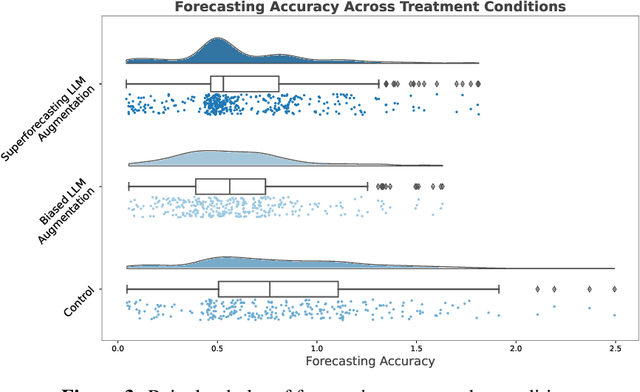
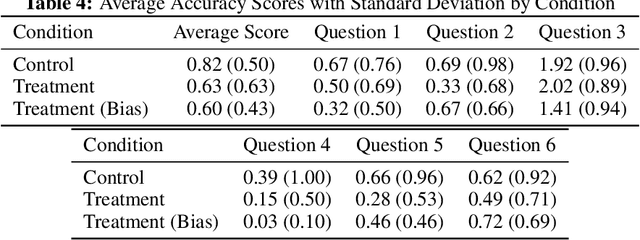
Large language models (LLMs) show impressive capabilities, matching and sometimes exceeding human performance in many domains. This study explores the potential of LLMs to augment judgement in forecasting tasks. We evaluated the impact on forecasting accuracy of two GPT-4-Turbo assistants: one designed to provide high-quality advice ('superforecasting'), and the other designed to be overconfident and base-rate-neglecting. Participants (N = 991) had the option to consult their assigned LLM assistant throughout the study, in contrast to a control group that used a less advanced model (DaVinci-003) without direct forecasting support. Our preregistered analyses reveal that LLM augmentation significantly enhances forecasting accuracy by 23% across both types of assistants, compared to the control group. This improvement occurs despite the superforecasting assistant's higher accuracy in predictions, indicating the augmentation's benefit is not solely due to model prediction accuracy. Exploratory analyses showed a pronounced effect in one forecasting item, without which we find that the superforecasting assistant increased accuracy by 43%, compared with 28% for the biased assistant. We further examine whether LLM augmentation disproportionately benefits less skilled forecasters, degrades the wisdom-of-the-crowd by reducing prediction diversity, or varies in effectiveness with question difficulty. Our findings do not consistently support these hypotheses. Our results suggest that access to an LLM assistant, even a biased one, can be a helpful decision aid in cognitively demanding tasks where the answer is not known at the time of interaction.