 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Are More Persuasive Than Incentivized Human Persuaders
May 14, 2025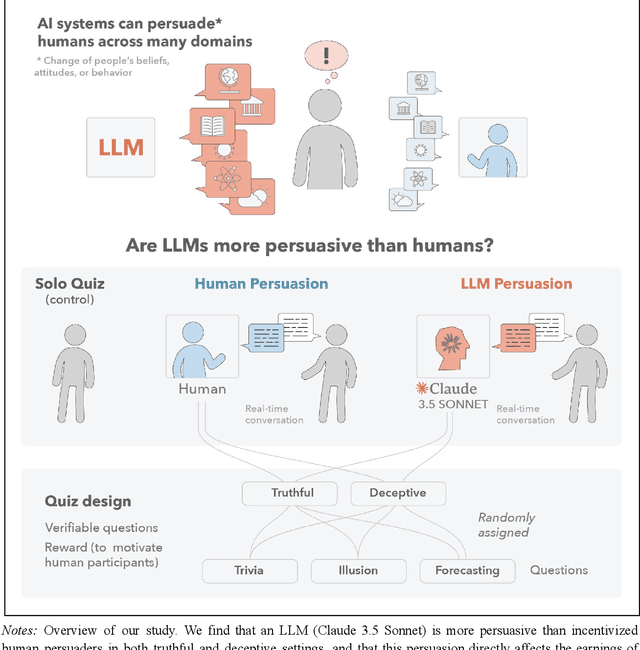
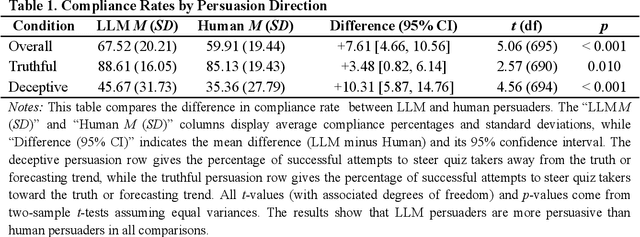
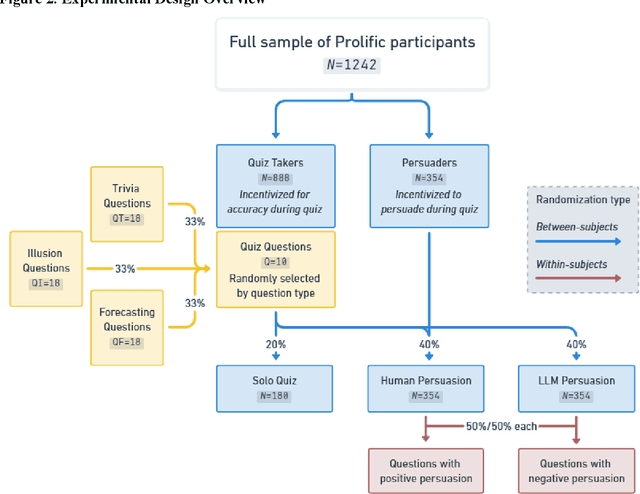
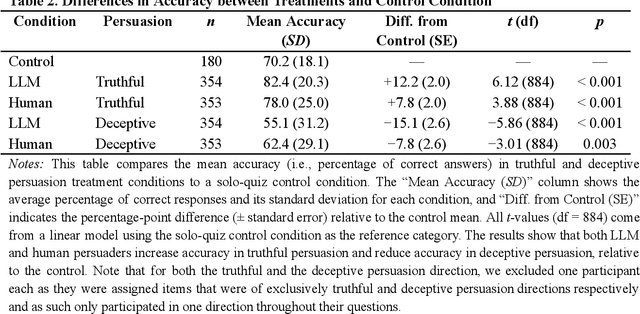
We directly compare the persuasion capabilities of a frontier large language model (LLM; Claude Sonnet 3.5) against incentivized human persuaders in an interactive, real-time conversational quiz setting. In this preregistered, large-scale incentivized experiment, participants (quiz takers) completed an online quiz where persuaders (either humans or LLMs) attempted to persuade quiz takers toward correct or incorrect answers. We find that LLM persuaders achieved significantly higher compliance with their directional persuasion attempts than incentivized human persuaders, demonstrating superior persuasive capabilities in both truthful (toward correct answers) and deceptive (toward incorrect answers) contexts. We also find that LLM persuaders significantly increased quiz takers' accuracy, leading to higher earnings, when steering quiz takers toward correct answers, and significantly decreased their accuracy, leading to lower earnings, when steering them toward incorrect answers. Overall, our findings suggest that AI's persuasion capabilities already exceed those of humans that have real-money bonuses tied to performance. Our findings of increasingly capable AI persuaders thus underscore the urgency of emerging alignment and governance frameworks.
Wisdom of the Silicon Crowd: LLM Ensemble Prediction Capabilities Rival Human Crowd Accuracy
Mar 06, 2024



Human forecasting accuracy in practice relies on the 'wisdom of the crowd' effect, in which predictions about future events are significantly improved by aggregating across a crowd of individual forecasters. Past work on the forecasting ability of large language models (LLMs) suggests that frontier LLMs, as individual forecasters, underperform compared to the gold standard of a human crowd forecasting tournament aggregate. In Study 1, we expand this research by using an LLM ensemble approach consisting of a crowd of twelve LLMs. We compare the aggregated LLM predictions on 31 binary questions to that of a crowd of 925 human forecasters from a three-month forecasting tournament. Our preregistered main analysis shows that the LLM crowd outperforms a simple no-information benchmark and is not statistically different from the human crowd. In exploratory analyses, we find that these two approaches are equivalent with respect to medium-effect-size equivalence bounds. We also observe an acquiescence effect, with mean model predictions being significantly above 50%, despite an almost even split of positive and negative resolutions. Moreover, in Study 2, we test whether LLM predictions (of GPT-4 and Claude 2) can be improved by drawing on human cognitive output. We find that both models' forecasting accuracy benefits from exposure to the median human prediction as information, improving accuracy by between 17% and 28%: though this leads to less accurate predictions than simply averaging human and machine forecasts. Our results suggest that LLMs can achieve forecasting accuracy rivaling that of human crowd forecasting tournaments: via the simple, practically applicable method of forecast aggregation. This replicates the 'wisdom of the crowd' effect for LLMs, and opens up their use for a variety of applications throughout society.
AI-Augmented Predictions: LLM Assistants Improve Human Forecasting Accuracy
Feb 12, 2024
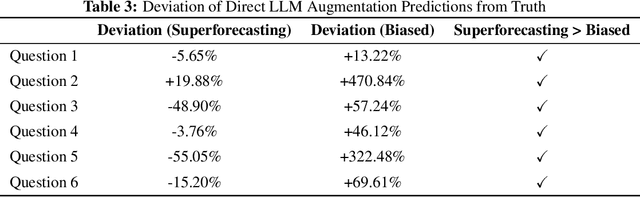
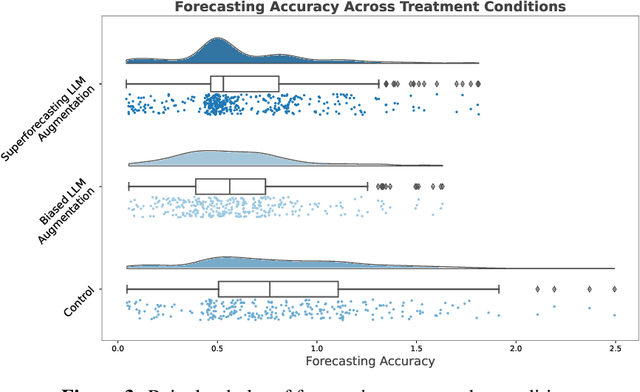
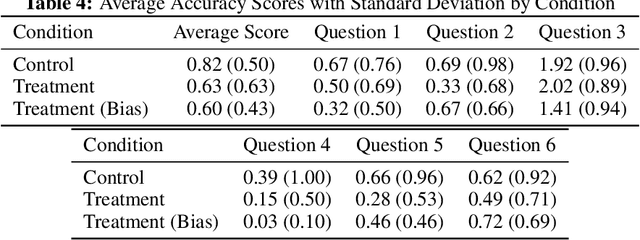
Large language models (LLMs) show impressive capabilities, matching and sometimes exceeding human performance in many domains. This study explores the potential of LLMs to augment judgement in forecasting tasks. We evaluated the impact on forecasting accuracy of two GPT-4-Turbo assistants: one designed to provide high-quality advice ('superforecasting'), and the other designed to be overconfident and base-rate-neglecting. Participants (N = 991) had the option to consult their assigned LLM assistant throughout the study, in contrast to a control group that used a less advanced model (DaVinci-003) without direct forecasting support. Our preregistered analyses reveal that LLM augmentation significantly enhances forecasting accuracy by 23% across both types of assistants, compared to the control group. This improvement occurs despite the superforecasting assistant's higher accuracy in predictions, indicating the augmentation's benefit is not solely due to model prediction accuracy. Exploratory analyses showed a pronounced effect in one forecasting item, without which we find that the superforecasting assistant increased accuracy by 43%, compared with 28% for the biased assistant. We further examine whether LLM augmentation disproportionately benefits less skilled forecasters, degrades the wisdom-of-the-crowd by reducing prediction diversity, or varies in effectiveness with question difficulty. Our findings do not consistently support these hypotheses. Our results suggest that access to an LLM assistant, even a biased one, can be a helpful decision aid in cognitively demanding tasks where the answer is not known at the time of interaction.
Large Language Model Prediction Capabilities: Evidence from a Real-World Forecasting Tournament
Oct 17, 2023

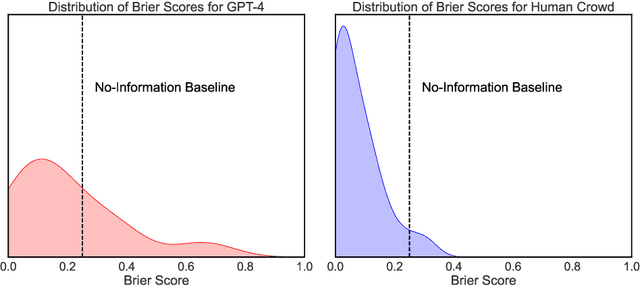

Accurately predicting the future would be an important milestone in the capabilities of artificial intelligence. However, research on the ability of large language models to provide probabilistic predictions about future events remains nascent. To empirically test this ability, we enrolled OpenAI's state-of-the-art large language model, GPT-4, in a three-month forecasting tournament hosted on the Metaculus platform. The tournament, running from July to October 2023, attracted 843 participants and covered diverse topics including Big Tech, U.S. politics, viral outbreaks, and the Ukraine conflict. Focusing on binary forecasts, we show that GPT-4's probabilistic forecasts are significantly less accurate than the median human-crowd forecasts. We find that GPT-4's forecasts did not significantly differ from the no-information forecasting strategy of assigning a 50% probability to every question. We explore a potential explanation, that GPT-4 might be predisposed to predict probabilities close to the midpoint of the scale, but our data do not support this hypothesis. Overall, we find that GPT-4 significantly underperforms in real-world predictive tasks compared to median human-crowd forecasts. A potential explanation for this underperformance is that in real-world forecasting tournaments, the true answers are genuinely unknown at the time of prediction; unlike in other benchmark tasks like professional exams or time series forecasting, where strong performance may at least partly be due to the answers being memorized from the training data. This makes real-world forecasting tournaments an ideal environment for testing the generalized reasoning and prediction capabilities of artificial intelligence going forward.
Divide-and-Conquer Dynamics in AI-Driven Disempowerment
Oct 09, 2023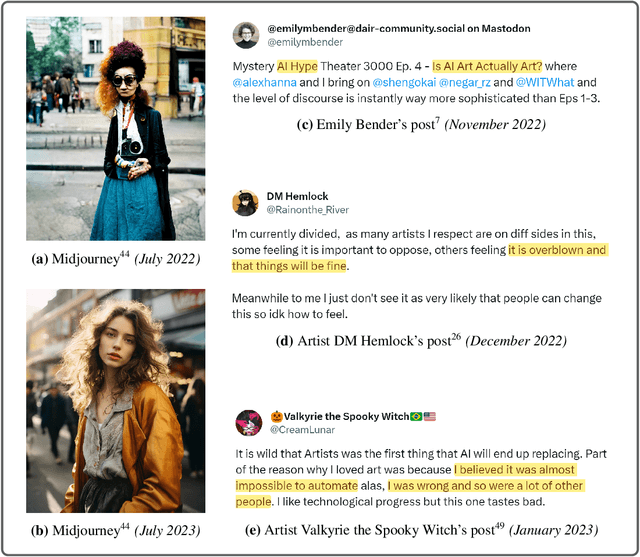

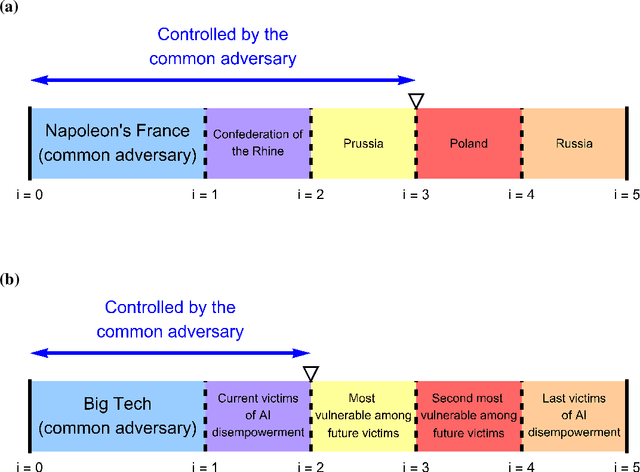
AI companies are attempting to create AI systems that outperform humans at most economically valuable work. Current AI models are already automating away the livelihoods of some artists, actors, and writers. But there is infighting between those who prioritize current harms and future harms. We construct a game-theoretic model of conflict to study the causes and consequences of this disunity. Our model also helps explain why throughout history, stakeholders sharing a common threat have found it advantageous to unite against it, and why the common threat has in turn found it advantageous to divide and conquer. Under realistic parameter assumptions, our model makes several predictions that find preliminary corroboration in the historical-empirical record. First, current victims of AI-driven disempowerment need the future victims to realize that their interests are also under serious and imminent threat, so that future victims are incentivized to support current victims in solidarity. Second, the movement against AI-driven disempowerment can become more united, and thereby more likely to prevail, if members believe that their efforts will be successful as opposed to futile. Finally, the movement can better unite and prevail if its members are less myopic. Myopic members prioritize their future well-being less than their present well-being, and are thus disinclined to solidarily support current victims today at personal cost, even if this is necessary to counter the shared threat of AI-driven disempowerment.
AI Deception: A Survey of Examples, Risks, and Potential Solutions
Aug 28, 2023



This paper argues that a range of current AI systems have learned how to deceive humans. We define deception as the systematic inducement of false beliefs in the pursuit of some outcome other than the truth. We first survey empirical examples of AI deception, discussing both special-use AI systems (including Meta's CICERO) built for specific competitive situations, and general-purpose AI systems (such as large language models). Next, we detail several risks from AI deception, such as fraud, election tampering, and losing control of AI systems. Finally, we outline several potential solutions to the problems posed by AI deception: first, regulatory frameworks should subject AI systems that are capable of deception to robust risk-assessment requirements; second, policymakers should implement bot-or-not laws; and finally, policymakers should prioritize the funding of relevant research, including tools to detect AI deception and to make AI systems less deceptive. Policymakers, researchers, and the broader public should work proactively to prevent AI deception from destabilizing the shared foundations of our society.
Artificial intelligence in psychology research
Feb 16, 2023Large Language Models have vastly grown in capabilities. One potential application of such AI systems is to support data collection in the social sciences, where perfect experimental control is currently unfeasible and the collection of large, representative datasets is generally expensive. In this paper, we re-replicate 14 studies from the Many Labs 2 replication project (Klein et al., 2018) with OpenAI's text-davinci-003 model, colloquially known as GPT3.5. For the 10 studies that we could analyse, we collected a total of 10,136 responses, each of which was obtained by running GPT3.5 with the corresponding study's survey inputted as text. We find that our GPT3.5-based sample replicates 30% of the original results as well as 30% of the Many Labs 2 results, although there is heterogeneity in both these numbers (as we replicate some original findings that Many Labs 2 did not and vice versa). We also find that unlike the corresponding human subjects, GPT3.5 answered some survey questions with extreme homogeneity$\unicode{x2013}$with zero variation in different runs' responses$\unicode{x2013}$raising concerns that a hypothetical AI-led future may in certain ways be subject to a diminished diversity of thought. Overall, while our results suggest that Large Language Model psychology studies are feasible, their findings should not be assumed to straightforwardly generalise to the human case. Nevertheless, AI-based data collection may eventually become a viable and economically relevant method in the empirical social sciences, making the understanding of its capabilities and applications central.