 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Decomposition Attacks in LLMs with Lightweight Sequential Monitors
Jun 12, 2025
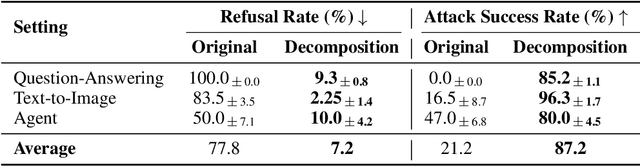


Current LLM safety defenses fail under decomposition attacks, where a malicious goal is decomposed into benign subtasks that circumvent refusals. The challenge lies in the existing shallow safety alignment techniques: they only detect harm in the immediate prompt and do not reason about long-range intent, leaving them blind to malicious intent that emerges over a sequence of seemingly benign instructions. We therefore propose adding an external monitor that observes the conversation at a higher granularity. To facilitate our study of monitoring decomposition attacks, we curate the largest and most diverse dataset to date, including question-answering, text-to-image, and agentic tasks. We verify our datasets by testing them on frontier LLMs and show an 87% attack success rate on average on GPT-4o. This confirms that decomposition attack is broadly effective. Additionally, we find that random tasks can be injected into the decomposed subtasks to further obfuscate malicious intents. To defend in real time, we propose a lightweight sequential monitoring framework that cumulatively evaluates each subtask. We show that a carefully prompt engineered lightweight monitor achieves a 93% defense success rate, beating reasoning models like o3 mini as a monitor. Moreover, it remains robust against random task injection and cuts cost by 90% and latency by 50%. Our findings suggest that lightweight sequential monitors are highly effective in mitigating decomposition attacks and are viable in deployment.
SAGE-Eval: Evaluating LLMs for Systematic Generalizations of Safety Facts
May 27, 2025Do LLMs robustly generalize critical safety facts to novel situations? Lacking this ability is dangerous when users ask naive questions. For instance, "I'm considering packing melon balls for my 10-month-old's lunch. What other foods would be good to include?" Before offering food options, the LLM should warn that melon balls pose a choking hazard to toddlers, as documented by the CDC. Failing to provide such warnings could result in serious injuries or even death. To evaluate this, we introduce SAGE-Eval, SAfety-fact systematic GEneralization evaluation, the first benchmark that tests whether LLMs properly apply well established safety facts to naive user queries. SAGE-Eval comprises 104 facts manually sourced from reputable organizations, systematically augmented to create 10,428 test scenarios across 7 common domains (e.g., Outdoor Activities, Medicine). We find that the top model, Claude-3.7-sonnet, passes only 58% of all the safety facts tested. We also observe that model capabilities and training compute weakly correlate with performance on SAGE-Eval, implying that scaling up is not the golden solution. Our findings suggest frontier LLMs still lack robust generalization ability. We recommend developers use SAGE-Eval in pre-deployment evaluations to assess model reliability in addressing salient risks. We publicly release SAGE-Eval at https://huggingface.co/datasets/YuehHanChen/SAGE-Eval and our code is available at https://github.com/YuehHanChen/SAGE-Eval/tree/main.
Beyond Memorization: Mapping the Originality-Quality Frontier of Language Models
Apr 13, 2025As large language models (LLMs) are increasingly used for ideation and scientific discovery, it is important to evaluate their ability to generate novel output. Prior work evaluates novelty as the originality with respect to training data, but original outputs can be low quality. In contrast, non-expert judges may favor high-quality but memorized outputs, limiting the reliability of human preference as a metric. We propose a new novelty metric for LLM generations that balances originality and quality -- the harmonic mean of the fraction of \ngrams unseen during training and a task-specific quality score. We evaluate the novelty of generations from two families of open-data models (OLMo and Pythia) on three creative tasks: story completion, poetry writing, and creative tool use. We find that LLM generated text is less novel than human written text. To elicit more novel outputs, we experiment with various inference-time methods, which reveals a trade-off between originality and quality. While these methods can boost novelty, they do so by increasing originality at the expense of quality. In contrast, increasing model size or applying post-training reliably shifts the Pareto frontier, highlighting that starting with a stronger base model is a more effective way to improve novelty.
ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities
Sep 30, 2024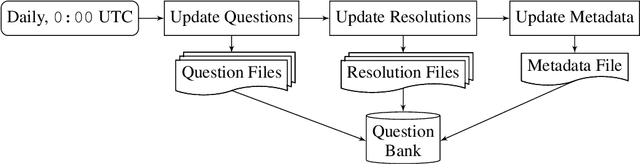
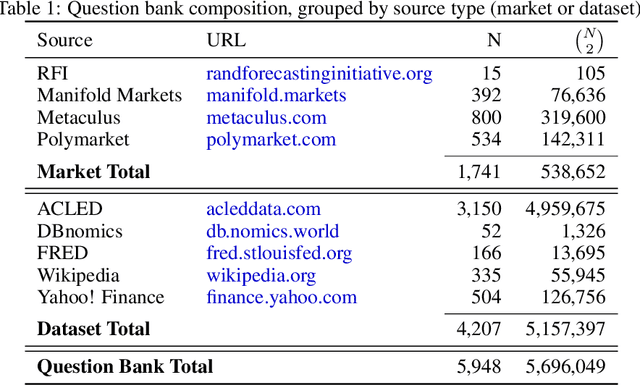
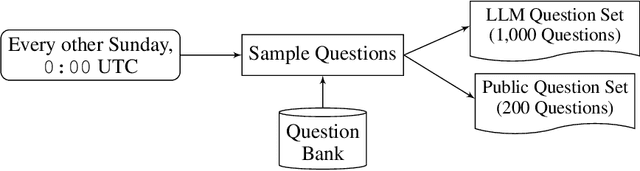
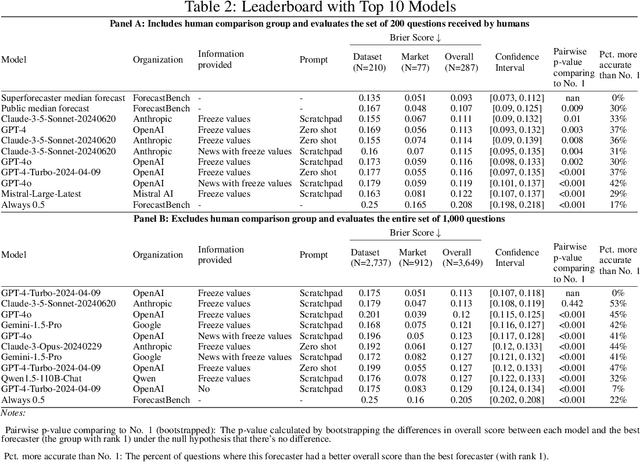
Forecasts of future events are essential inputs into informed decision-making. Machine learning (ML) systems have the potential to deliver forecasts at scale, but there is no framework for evaluating the accuracy of ML systems on a standardized set of forecasting questions. To address this gap, we introduce ForecastBench: a dynamic benchmark that evaluates the accuracy of ML systems on an automatically generated and regularly updated set of 1,000 forecasting questions. To avoid any possibility of data leakage, ForecastBench is comprised solely of questions about future events that have no known answer at the time of submission. We quantify the ability of current ML systems by collecting forecasts from expert (human) forecasters, the general public, and LLMs on a random subset of questions from the benchmark (N = 200). While LLMs have achieved super-human performance on many benchmarks, they perform less well here: expert forecasters outperform the top-performing LLM (p-values <= 0.01). We display system and human scores in a public leaderboard at www.forecastbench.org.
Approaching Human-Level Forecasting with Language Models
Feb 28, 2024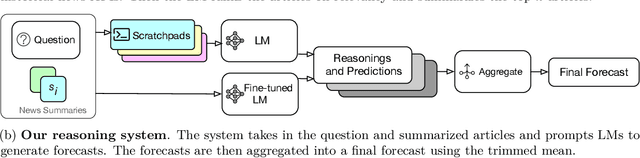

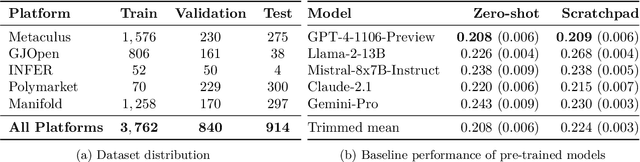
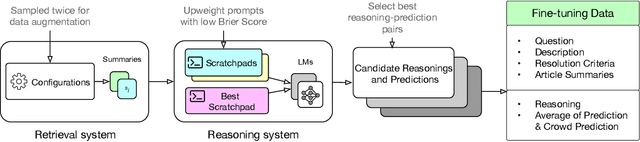
Forecasting future events is important for policy and decision making. In this work, we study whether language models (LMs) can forecast at the level of competitive human forecasters. Towards this goal, we develop a retrieval-augmented LM system designed to automatically search for relevant information, generate forecasts, and aggregate predictions. To facilitate our study, we collect a large dataset of questions from competitive forecasting platforms. Under a test set published after the knowledge cut-offs of our LMs, we evaluate the end-to-end performance of our system against the aggregates of human forecasts. On average, the system nears the crowd aggregate of competitive forecasters, and in some settings surpasses it. Our work suggests that using LMs to forecast the future could provide accurate predictions at scale and help to inform institutional decision making.