 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Organizations are More Effective but Less Aligned than Individual Agents
Apr 11, 2026AI is increasingly deployed in multi-agent systems; however, most research considers only the behavior of individual models. We experimentally show that multi-agent "AI organizations" are simultaneously more effective at achieving business goals, but less aligned, than individual AI agents. We examine 12 tasks across two practical settings: an AI consultancy providing solutions to business problems and an AI software team developing software products. Across all settings, AI Organizations composed of aligned models produce solutions with higher utility but greater misalignment compared to a single aligned model. Our work demonstrates the importance of considering interacting systems of AI agents when doing both capabilities and safety research.
The Prosocial Ranking Challenge: Reducing Polarization on Social Media without Sacrificing Engagement
Mar 20, 2026We report the first direct comparisons of multiple alternative social media algorithms on multiple platforms on outcomes of societal interest. We used a browser extension to modify which posts were shown to desktop social media users, randomly assigning 9,386 users to a control group or one of five alternative ranking algorithms which simultaneously altered content across three platforms for six months during the US 2024 presidential election. This reduced our preregistered index of affective polarization by an average of 0.03 standard deviations (p < 0.05), including a 1.5 degree decrease in differences between the 100 point inparty and outparty feeling thermometers. We saw reductions in active use time for Facebook (-0.37 min/day) and Reddit (-0.2 min/day), but an increase of 0.32 min/day (p < 0.01) for X/Twitter. We saw an increase in reports of negative social media experiences but found no effects on well-being, news knowledge, outgroup empathy, perceptions of and support for partisan violence. This implies that bridging content can improve some societal outcomes without necessarily conflicting with the engagement-driven business model of social media.
WOMAC: A Mechanism For Prediction Competitions
Aug 25, 2025Competitions are widely used to identify top performers in judgmental forecasting and machine learning, and the standard competition design ranks competitors based on their cumulative scores against a set of realized outcomes or held-out labels. However, this standard design is neither incentive-compatible nor very statistically efficient. The main culprit is noise in outcomes/labels that experts are scored against; it allows weaker competitors to often win by chance, and the winner-take-all nature incentivizes misreporting that improves win probability even if it decreases expected score. Attempts to achieve incentive-compatibility rely on randomized mechanisms that add even more noise in winner selection, but come at the cost of determinism and practical adoption. To tackle these issues, we introduce a novel deterministic mechanism: WOMAC (Wisdom of the Most Accurate Crowd). Instead of scoring experts against noisy outcomes, as is standard, WOMAC scores experts against the best ex-post aggregate of peer experts' predictions given the noisy outcomes. WOMAC is also more efficient than the standard competition design in typical settings. While the increased complexity of WOMAC makes it challenging to analyze incentives directly, we provide a clear theoretical foundation to justify the mechanism. We also provide an efficient vectorized implementation and demonstrate empirically on real-world forecasting datasets that WOMAC is a more reliable predictor of experts' out-of-sample performance relative to the standard mechanism. WOMAC is useful in any competition where there is substantial noise in the outcomes/labels.
Tell Me Why: Incentivizing Explanations
Feb 19, 2025Common sense suggests that when individuals explain why they believe something, we can arrive at more accurate conclusions than when they simply state what they believe. Yet, there is no known mechanism that provides incentives to elicit explanations for beliefs from agents. This likely stems from the fact that standard Bayesian models make assumptions (like conditional independence of signals) that preempt the need for explanations, in order to show efficient information aggregation. A natural justification for the value of explanations is that agents' beliefs tend to be drawn from overlapping sources of information, so agents' belief reports do not reveal all that needs to be known. Indeed, this work argues that rationales-explanations of an agent's private information-lead to more efficient aggregation by allowing agents to efficiently identify what information they share and what information is new. Building on this model of rationales, we present a novel 'deliberation mechanism' to elicit rationales from agents in which truthful reporting of beliefs and rationales is a perfect Bayesian equilibrium.
Auctions and Prediction Markets for Scientific Peer Review
Aug 27, 2021
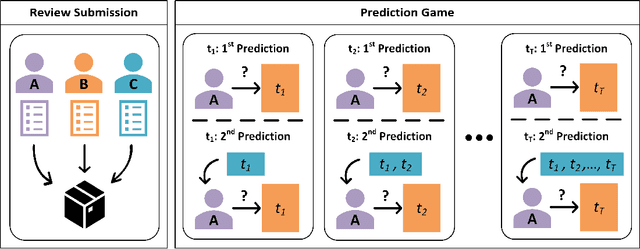
Peer reviewed publications are considered the gold standard in certifying and disseminating ideas that a research community considers valuable. However, we identify two major drawbacks of the current system: (1) the overwhelming demand for reviewers due to a large volume of submissions, and (2) the lack of incentives for reviewers to participate and expend the necessary effort to provide high-quality reviews. In this work, we adopt a mechanism-design approach to propose improvements to the peer review process. We present a two-stage mechanism which ties together the paper submission and review process, simultaneously incentivizing high-quality reviews and high-quality submissions. In the first stage, authors participate in a VCG auction for review slots by submitting their papers along with a bid that represents their expected value for having their paper reviewed. For the second stage, we propose a novel prediction market-style mechanism (H-DIPP) building on recent work in the information elicitation literature, which incentivizes participating reviewers to provide honest and effortful reviews. The revenue raised by the Stage I auction is used in Stage II to pay reviewers based on the quality of their reviews.
Learning Deep Features in Instrumental Variable Regression
Nov 01, 2020
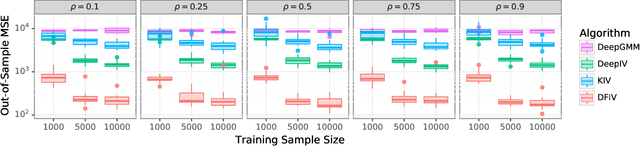

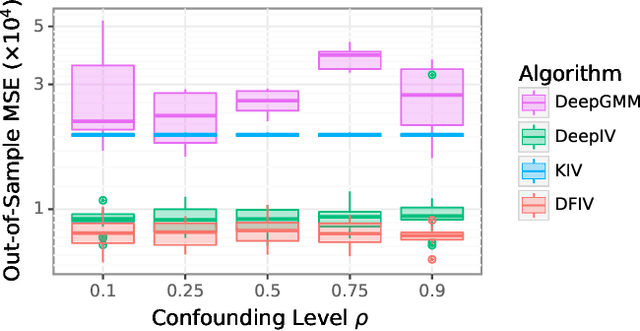
Instrumental variable (IV) regression is a standard strategy for learning causal relationships between confounded treatment and outcome variables from observational data by utilizing an instrumental variable, which affects the outcome only through the treatment. In classical IV regression, learning proceeds in two stages: stage 1 performs linear regression from the instrument to the treatment; and stage 2 performs linear regression from the treatment to the outcome, conditioned on the instrument. We propose a novel method, deep feature instrumental variable regression (DFIV), to address the case where relations between instruments, treatments, and outcomes may be nonlinear. In this case, deep neural nets are trained to define informative nonlinear features on the instruments and treatments. We propose an alternating training regime for these features to ensure good end-to-end performance when composing stages 1 and 2, thus obtaining highly flexible feature maps in a computationally efficient manner. DFIV outperforms recent state-of-the-art methods on challenging IV benchmarks, including settings involving high dimensional image data. DFIV also exhibits competitive performance in off-policy policy evaluation for reinforcement learning, which can be understood as an IV regression task.
Quantum Tensor Networks, Stochastic Processes, and Weighted Automata
Oct 20, 2020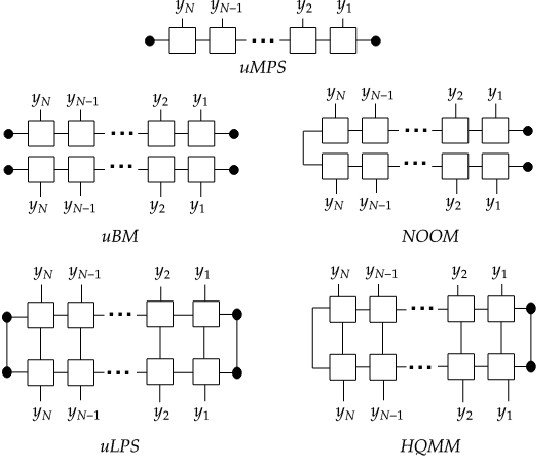

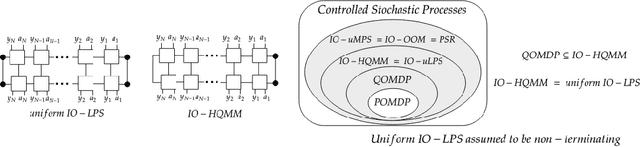
Modeling joint probability distributions over sequences has been studied from many perspectives. The physics community developed matrix product states, a tensor-train decomposition for probabilistic modeling, motivated by the need to tractably model many-body systems. But similar models have also been studied in the stochastic processes and weighted automata literature, with little work on how these bodies of work relate to each other. We address this gap by showing how stationary or uniform versions of popular quantum tensor network models have equivalent representations in the stochastic processes and weighted automata literature, in the limit of infinitely long sequences. We demonstrate several equivalence results between models used in these three communities: (i) uniform variants of matrix product states, Born machines and locally purified states from the quantum tensor networks literature, (ii) predictive state representations, hidden Markov models, norm-observable operator models and hidden quantum Markov models from the stochastic process literature,and (iii) stochastic weighted automata, probabilistic automata and quadratic automata from the formal languages literature. Such connections may open the door for results and methods developed in one area to be applied in another.
Expressiveness and Learning of Hidden Quantum Markov Models
Dec 02, 2019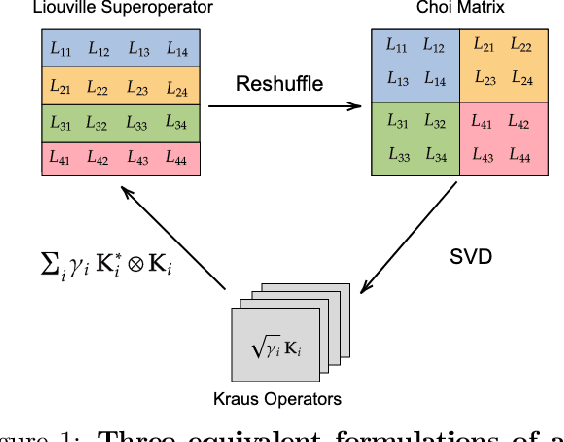
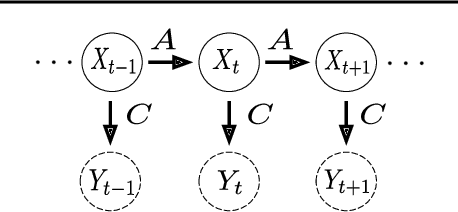
Extending classical probabilistic reasoning using the quantum mechanical view of probability has been of recent interest, particularly in the development of hidden quantum Markov models (HQMMs) to model stochastic processes. However, there has been little progress in characterizing the expressiveness of such models and learning them from data. We tackle these problems by showing that HQMMs are a special subclass of the general class of observable operator models (OOMs) that do not suffer from the \emph{negative probability problem} by design. We also provide a feasible retraction-based learning algorithm for HQMMs using constrained gradient descent on the Stiefel manifold of model parameters. We demonstrate that this approach is faster and scales to larger models than previous learning algorithms.
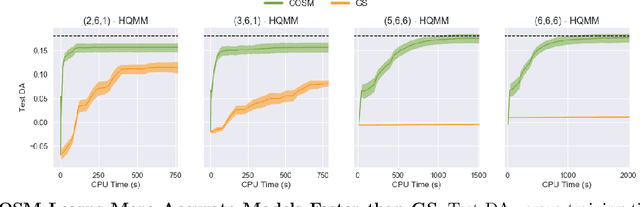
Learning Quantum Graphical Models using Constrained Gradient Descent on the Stiefel Manifold
Mar 09, 2019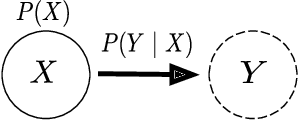

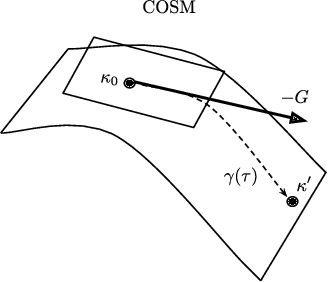
Quantum graphical models (QGMs) extend the classical framework for reasoning about uncertainty by incorporating the quantum mechanical view of probability. Prior work on QGMs has focused on hidden quantum Markov models (HQMMs), which can be formulated using quantum analogues of the sum rule and Bayes rule used in classical graphical models. Despite the focus on developing the QGM framework, there has been little progress in learning these models from data. The existing state-of-the-art approach randomly initializes parameters and iteratively finds unitary transformations that increase the likelihood of the data. While this algorithm demonstrated theoretical strengths of HQMMs over HMMs, it is slow and can only handle a small number of hidden states. In this paper, we tackle the learning problem by solving a constrained optimization problem on the Stiefel manifold using a well-known retraction-based algorithm. We demonstrate that this approach is not only faster and yields better solutions on several datasets, but also scales to larger models that were prohibitively slow to train via the earlier method.
Learning and Inference in Hilbert Space with Quantum Graphical Models
Oct 29, 2018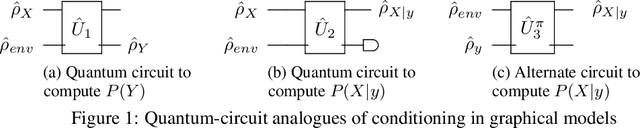
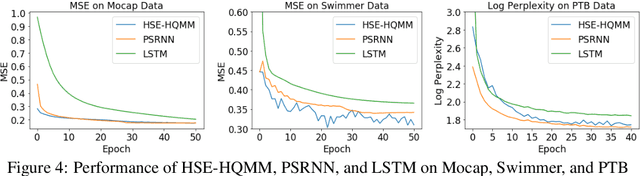
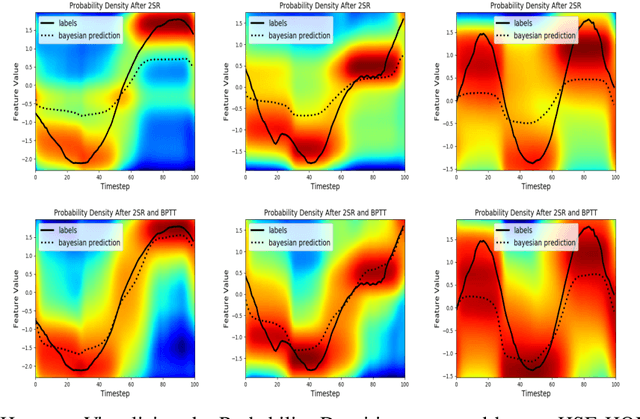
Quantum Graphical Models (QGMs) generalize classical graphical models by adopting the formalism for reasoning about uncertainty from quantum mechanics. Unlike classical graphical models, QGMs represent uncertainty with density matrices in complex Hilbert spaces. Hilbert space embeddings (HSEs) also generalize Bayesian inference in Hilbert spaces. We investigate the link between QGMs and HSEs and show that the sum rule and Bayes rule for QGMs are equivalent to the kernel sum rule in HSEs and a special case of Nadaraya-Watson kernel regression, respectively. We show that these operations can be kernelized, and use these insights to propose a Hilbert Space Embedding of Hidden Quantum Markov Models (HSE-HQMM) to model dynamics. We present experimental results showing that HSE-HQMMs are competitive with state-of-the-art models like LSTMs and PSRNNs on several datasets, while also providing a nonparametric method for maintaining a probability distribution over continuous-valued features.