 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposed Mutual Information Estimation for Contrastive Representation Learning
Jun 25, 2021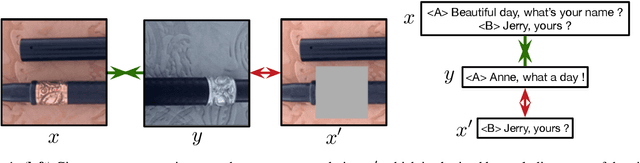

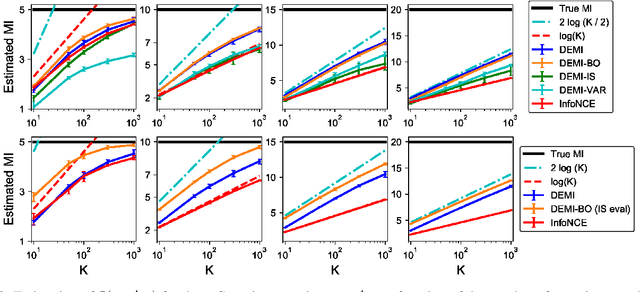
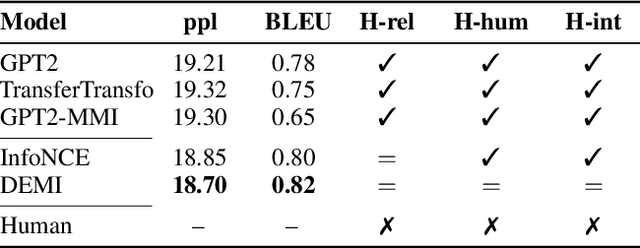
Recent contrastive representation learning methods rely on estimating mutual information (MI) between multiple views of an underlying context. E.g., we can derive multiple views of a given image by applying data augmentation, or we can split a sequence into views comprising the past and future of some step in the sequence. Contrastive lower bounds on MI are easy to optimize, but have a strong underestimation bias when estimating large amounts of MI. We propose decomposing the full MI estimation problem into a sum of smaller estimation problems by splitting one of the views into progressively more informed subviews and by applying the chain rule on MI between the decomposed views. This expression contains a sum of unconditional and conditional MI terms, each measuring modest chunks of the total MI, which facilitates approximation via contrastive bounds. To maximize the sum, we formulate a contrastive lower bound on the conditional MI which can be approximated efficiently. We refer to our general approach as Decomposed Estimation of Mutual Information (DEMI). We show that DEMI can capture a larger amount of MI than standard non-decomposed contrastive bounds in a synthetic setting, and learns better representations in a vision domain and for dialogue generation.
Domain Adaptation with Conditional Distribution Matching and Generalized Label Shift
Mar 10, 2020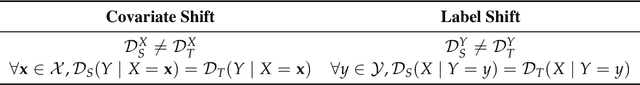
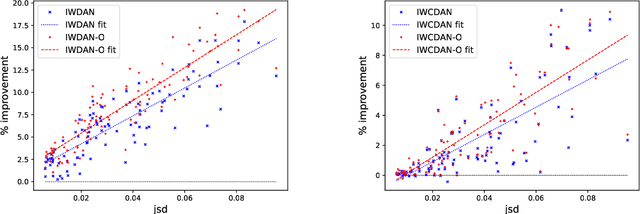

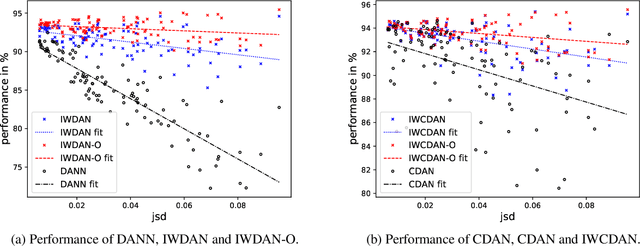
Adversarial learning has demonstrated good performance in the unsupervised domain adaptation setting, by learning domain-invariant representations that perform well on the source domain. However, recent work has underlined limitations of existing methods in the presence of mismatched label distributions between the source and target domains. In this paper, we extend a recent upper-bound on the performance of adversarial domain adaptation to multi-class classification and more general discriminators. We then propose generalized label shift (GLS) as a way to improve robustness against mismatched label distributions. GLS states that, conditioned on the label, there exists a representation of the input that is invariant between the source and target domains. Under GLS, we provide theoretical guarantees on the transfer performance of any classifier. We also devise necessary and sufficient conditions for GLS to hold. The conditions are based on the estimation of the relative class weights between domains and on an appropriate reweighting of samples. Guided by our theoretical insights, we modify three widely used algorithms, JAN, DANN and CDAN and evaluate their performance on standard domain adaptation tasks where our method outperforms the base versions. We also demonstrate significant gains on artificially created tasks with large divergences between their source and target label distributions.
A Reduction from Reinforcement Learning to No-Regret Online Learning
Jan 01, 2020We present a reduction from reinforcement learning (RL) to no-regret online learning based on the saddle-point formulation of RL, by which "any" online algorithm with sublinear regret can generate policies with provable performance guarantees. This new perspective decouples the RL problem into two parts: regret minimization and function approximation. The first part admits a standard online-learning analysis, and the second part can be quantified independently of the learning algorithm. Therefore, the proposed reduction can be used as a tool to systematically design new RL algorithms. We demonstrate this idea by devising a simple RL algorithm based on mirror descent and the generative-model oracle. For any $\gamma$-discounted tabular RL problem, with probability at least $1-\delta$, it learns an $\epsilon$-optimal policy using at most $\tilde{O}\left(\frac{|\mathcal{S}||\mathcal{A}|\log(\frac{1}{\delta})}{(1-\gamma)^4\epsilon^2}\right)$ samples. Furthermore, this algorithm admits a direct extension to linearly parameterized function approximators for large-scale applications, with computation and sample complexities independent of $|\mathcal{S}|$,$|\mathcal{A}|$, though at the cost of potential approximation bias.
Expressiveness and Learning of Hidden Quantum Markov Models
Dec 02, 2019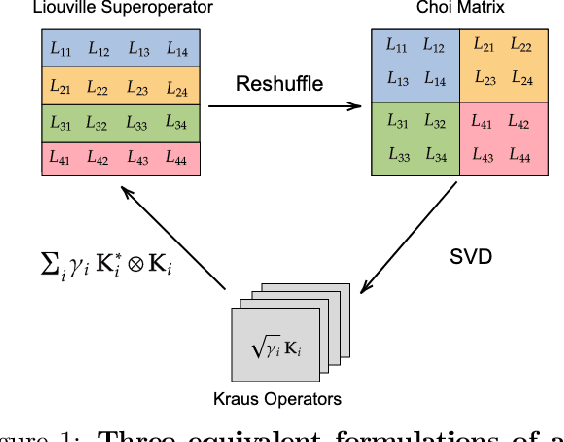
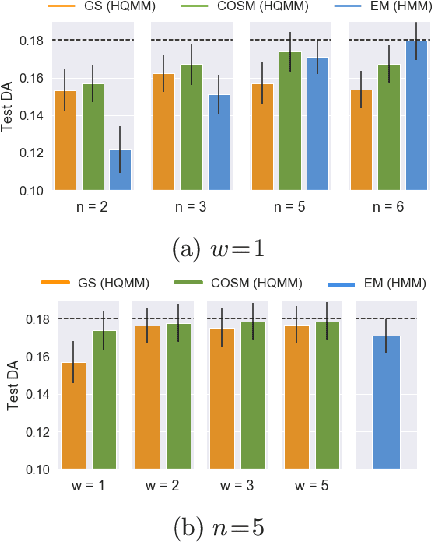
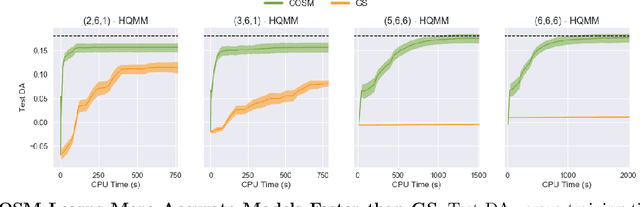
Extending classical probabilistic reasoning using the quantum mechanical view of probability has been of recent interest, particularly in the development of hidden quantum Markov models (HQMMs) to model stochastic processes. However, there has been little progress in characterizing the expressiveness of such models and learning them from data. We tackle these problems by showing that HQMMs are a special subclass of the general class of observable operator models (OOMs) that do not suffer from the \emph{negative probability problem} by design. We also provide a feasible retraction-based learning algorithm for HQMMs using constrained gradient descent on the Stiefel manifold of model parameters. We demonstrate that this approach is faster and scales to larger models than previous learning algorithms.
Efficient Multitask Feature and Relationship Learning
Sep 16, 2018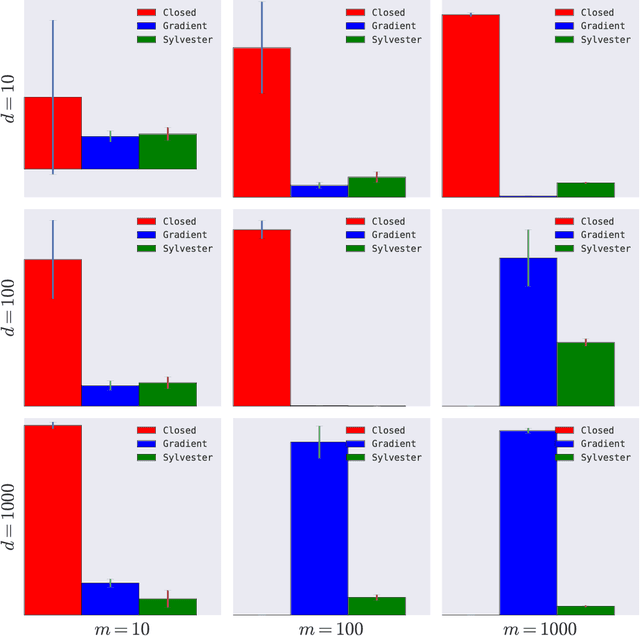

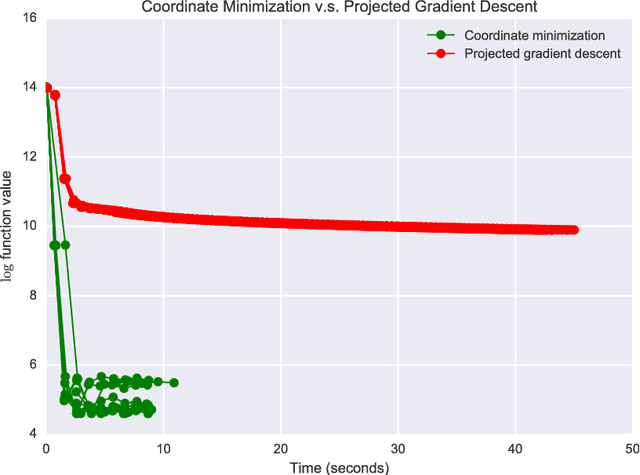

We consider a multitask learning problem, in which several predictors are learned jointly. Prior research has shown that learning the relations between tasks, and between the input features, together with the predictor, can lead to better generalization and interpretability, which proved to be useful for applications in many domains. In this paper, we consider a formulation of multitask learning that learns the relationships both between tasks and between features, represented through a task covariance and a feature covariance matrix, respectively. First, we demonstrate that existing methods proposed for this problem present an issue that may lead to ill-posed optimization. We then propose an alternative formulation, as well as an efficient algorithm to optimize it. Using ideas from optimization and graph theory, we propose an efficient coordinate-wise minimization algorithm that has a closed form solution for each block subproblem. Our experiments show that the proposed optimization method is orders of magnitude faster than its competitors. We also provide a nonlinear extension that is able to achieve better generalization than existing methods.
Frank-Wolfe Optimization for Symmetric-NMF under Simplicial Constraint
Jun 26, 2018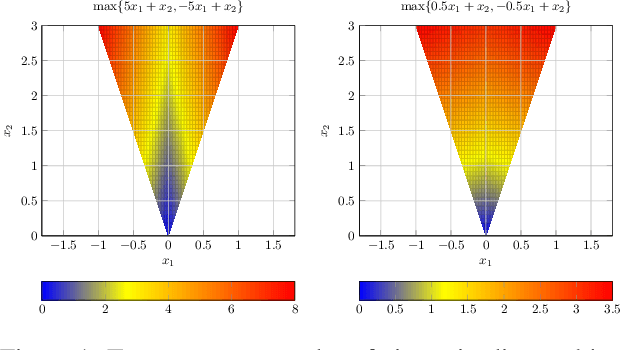
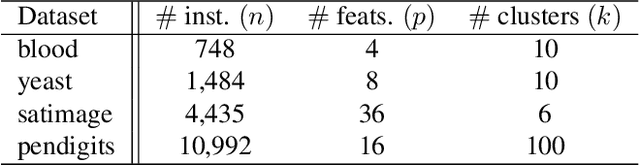
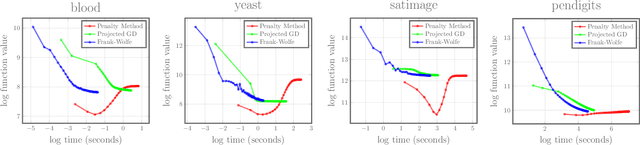
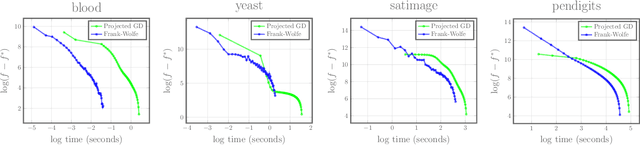
Symmetric nonnegative matrix factorization has found abundant applications in various domains by providing a symmetric low-rank decomposition of nonnegative matrices. In this paper we propose a Frank-Wolfe (FW) solver to optimize the symmetric nonnegative matrix factorization problem under a simplicial constraint, which has recently been proposed for probabilistic clustering. Compared with existing solutions, this algorithm is simple to implement, and has no hyperparameters to be tuned. Building on the recent advances of FW algorithms in nonconvex optimization, we prove an $O(1/\varepsilon^2)$ convergence rate to $\varepsilon$-approximate KKT points, via a tight bound $\Theta(n^2)$ on the curvature constant, which matches the best known result in unconstrained nonconvex setting using gradient methods. Numerical results demonstrate the effectiveness of our algorithm. As a side contribution, we construct a simple nonsmooth convex problem where the FW algorithm fails to converge to the optimum. This result raises an interesting question about necessary conditions of the success of the FW algorithm on convex problems.
Linear Time Computation of Moments in Sum-Product Networks
Nov 05, 2017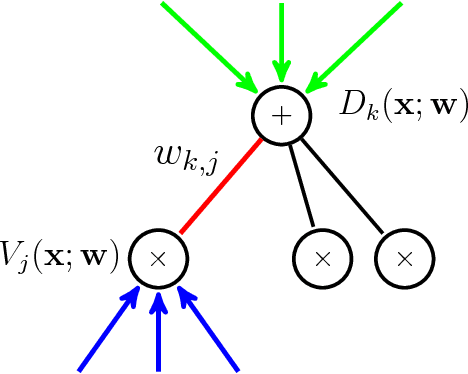
Bayesian online algorithms for Sum-Product Networks (SPNs) need to update their posterior distribution after seeing one single additional instance. To do so, they must compute moments of the model parameters under this distribution. The best existing method for computing such moments scales quadratically in the size of the SPN, although it scales linearly for trees. This unfortunate scaling makes Bayesian online algorithms prohibitively expensive, except for small or tree-structured SPNs. We propose an optimal linear-time algorithm that works even when the SPN is a general directed acyclic graph (DAG), which significantly broadens the applicability of Bayesian online algorithms for SPNs. There are three key ingredients in the design and analysis of our algorithm: 1). For each edge in the graph, we construct a linear time reduction from the moment computation problem to a joint inference problem in SPNs. 2). Using the property that each SPN computes a multilinear polynomial, we give an efficient procedure for polynomial evaluation by differentiation without expanding the network that may contain exponentially many monomials. 3). We propose a dynamic programming method to further reduce the computation of the moments of all the edges in the graph from quadratic to linear. We demonstrate the usefulness of our linear time algorithm by applying it to develop a linear time assume density filter (ADF) for SPNs.
Principled Hybrids of Generative and Discriminative Domain Adaptation
Oct 27, 2017

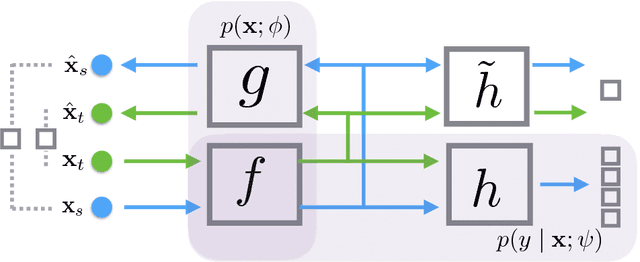

We propose a probabilistic framework for domain adaptation that blends both generative and discriminative modeling in a principled way. Under this framework, generative and discriminative models correspond to specific choices of the prior over parameters. This provides us a very general way to interpolate between generative and discriminative extremes through different choices of priors. By maximizing both the marginal and the conditional log-likelihoods, models derived from this framework can use both labeled instances from the source domain as well as unlabeled instances from both source and target domains. Under this framework, we show that the popular reconstruction loss of autoencoder corresponds to an upper bound of the negative marginal log-likelihoods of unlabeled instances, where marginal distributions are given by proper kernel density estimations. This provides a way to interpret the empirical success of autoencoders in domain adaptation and semi-supervised learning. We instantiate our framework using neural networks, and build a concrete model, DAuto. Empirically, we demonstrate the effectiveness of DAuto on text, image and speech datasets, showing that it outperforms related competitors when domain adaptation is possible.
Learning Hidden Quantum Markov Models
Oct 24, 2017
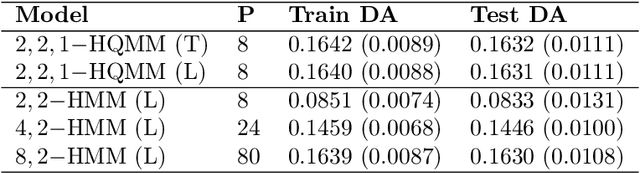
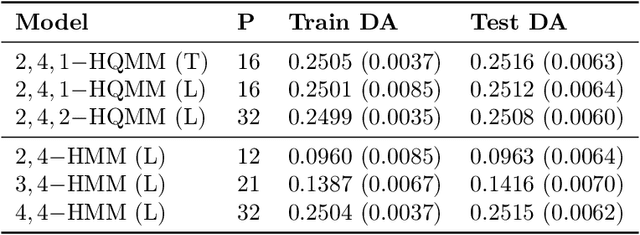
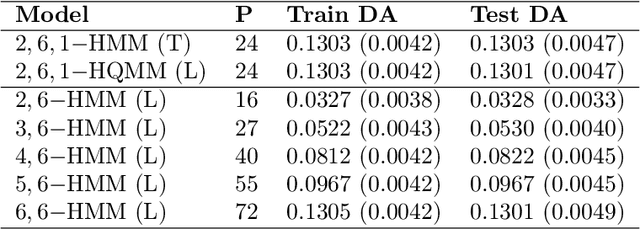
Hidden Quantum Markov Models (HQMMs) can be thought of as quantum probabilistic graphical models that can model sequential data. We extend previous work on HQMMs with three contributions: (1) we show how classical hidden Markov models (HMMs) can be simulated on a quantum circuit, (2) we reformulate HQMMs by relaxing the constraints for modeling HMMs on quantum circuits, and (3) we present a learning algorithm to estimate the parameters of an HQMM from data. While our algorithm requires further optimization to handle larger datasets, we are able to evaluate our algorithm using several synthetic datasets. We show that on HQMM generated data, our algorithm learns HQMMs with the same number of hidden states and predictive accuracy as the true HQMMs, while HMMs learned with the Baum-Welch algorithm require more states to match the predictive accuracy.
DeepArchitect: Automatically Designing and Training Deep Architectures
Apr 28, 2017
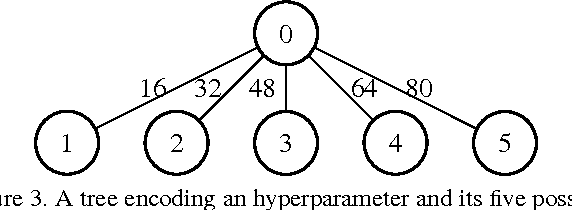
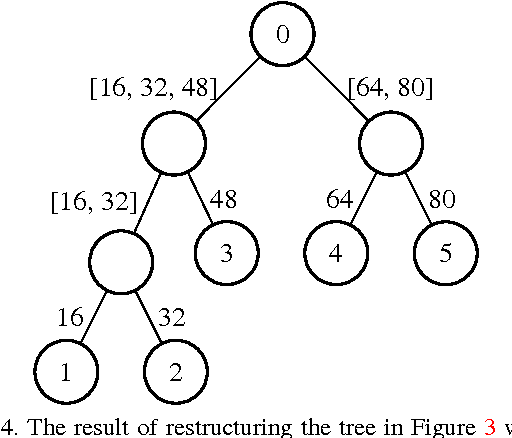
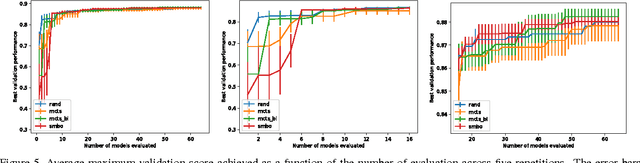
In deep learning, performance is strongly affected by the choice of architecture and hyperparameters. While there has been extensive work on automatic hyperparameter optimization for simple spaces, complex spaces such as the space of deep architectures remain largely unexplored. As a result, the choice of architecture is done manually by the human expert through a slow trial and error process guided mainly by intuition. In this paper we describe a framework for automatically designing and training deep models. We propose an extensible and modular language that allows the human expert to compactly represent complex search spaces over architectures and their hyperparameters. The resulting search spaces are tree-structured and therefore easy to traverse. Models can be automatically compiled to computational graphs once values for all hyperparameters have been chosen. We can leverage the structure of the search space to introduce different model search algorithms, such as random search, Monte Carlo tree search (MCTS), and sequential model-based optimization (SMBO). We present experiments comparing the different algorithms on CIFAR-10 and show that MCTS and SMBO outperform random search. In addition, these experiments show that our framework can be used effectively for model discovery, as it is possible to describe expressive search spaces and discover competitive models without much effort from the human expert. Code for our framework and experiments has been made publicly available.