 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Supervised Speaker Diarization
Oct 27, 2018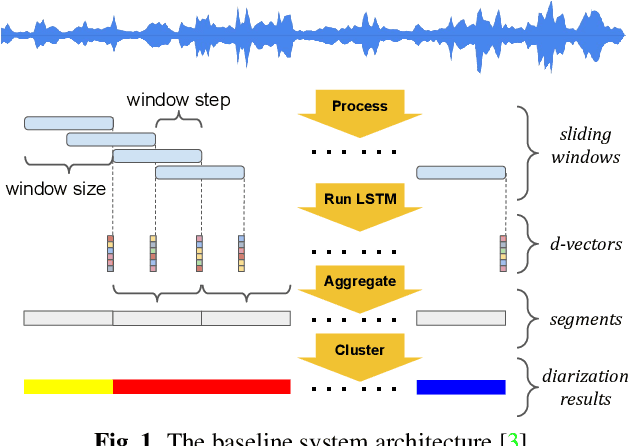
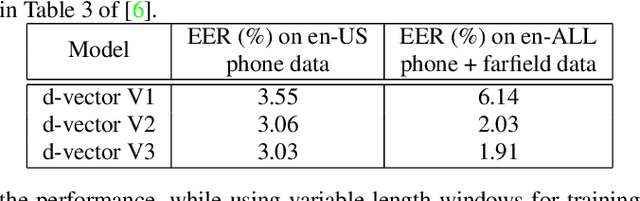
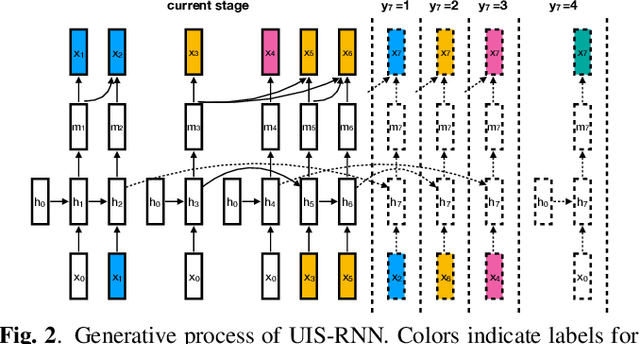

In this paper, we propose a fully supervised speaker diarization approach, named unbounded interleaved-state recurrent neural networks (UIS-RNN). Given extracted speaker-discriminative embeddings (a.k.a. d-vectors) from input utterances, each individual speaker is modeled by a parameter-sharing RNN, while the RNN states for different speakers interleave in the time domain. This RNN is naturally integrated with a distance-dependent Chinese restaurant process (ddCRP) to accommodate an unknown number of speakers. Our system is fully supervised and is able to learn from examples where time-stamped speaker labels are annotated. We achieved a 7.6% diarization error rate on NIST SRE 2000 CALLHOME, which is better than the state-of-the-art method using spectral clustering. Moreover, our method decodes in an online fashion while most state-of-the-art systems rely on offline clustering.
Principled Hybrids of Generative and Discriminative Domain Adaptation
Oct 27, 2017

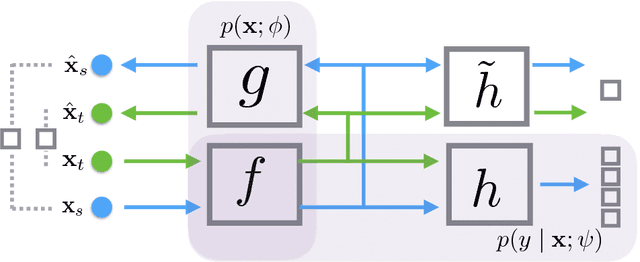

We propose a probabilistic framework for domain adaptation that blends both generative and discriminative modeling in a principled way. Under this framework, generative and discriminative models correspond to specific choices of the prior over parameters. This provides us a very general way to interpolate between generative and discriminative extremes through different choices of priors. By maximizing both the marginal and the conditional log-likelihoods, models derived from this framework can use both labeled instances from the source domain as well as unlabeled instances from both source and target domains. Under this framework, we show that the popular reconstruction loss of autoencoder corresponds to an upper bound of the negative marginal log-likelihoods of unlabeled instances, where marginal distributions are given by proper kernel density estimations. This provides a way to interpret the empirical success of autoencoders in domain adaptation and semi-supervised learning. We instantiate our framework using neural networks, and build a concrete model, DAuto. Empirically, we demonstrate the effectiveness of DAuto on text, image and speech datasets, showing that it outperforms related competitors when domain adaptation is possible.
Gram-CTC: Automatic Unit Selection and Target Decomposition for Sequence Labelling
Aug 12, 2017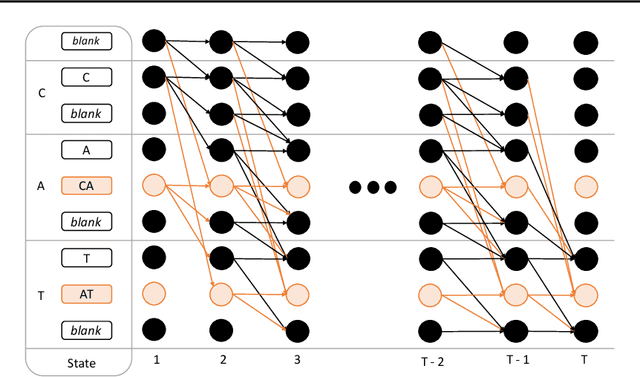

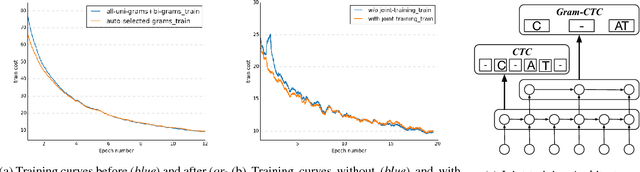

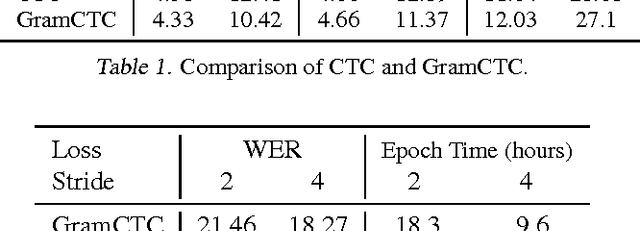
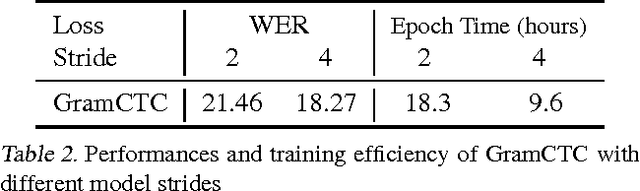
Most existing sequence labelling models rely on a fixed decomposition of a target sequence into a sequence of basic units. These methods suffer from two major drawbacks: 1) the set of basic units is fixed, such as the set of words, characters or phonemes in speech recognition, and 2) the decomposition of target sequences is fixed. These drawbacks usually result in sub-optimal performance of modeling sequences. In this pa- per, we extend the popular CTC loss criterion to alleviate these limitations, and propose a new loss function called Gram-CTC. While preserving the advantages of CTC, Gram-CTC automatically learns the best set of basic units (grams), as well as the most suitable decomposition of tar- get sequences. Unlike CTC, Gram-CTC allows the model to output variable number of characters at each time step, which enables the model to capture longer term dependency and improves the computational efficiency. We demonstrate that the proposed Gram-CTC improves CTC in terms of both performance and efficiency on the large vocabulary speech recognition task at multiple scales of data, and that with Gram-CTC we can outperform the state-of-the-art on a standard speech benchmark.
Exploring Neural Transducers for End-to-End Speech Recognition
Jul 24, 2017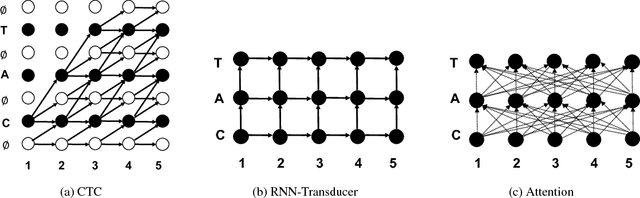
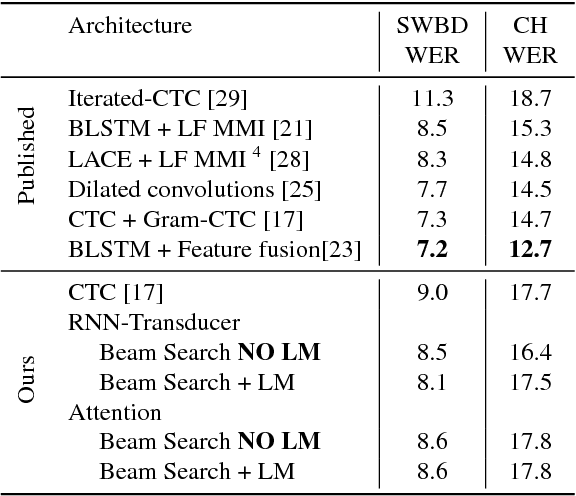
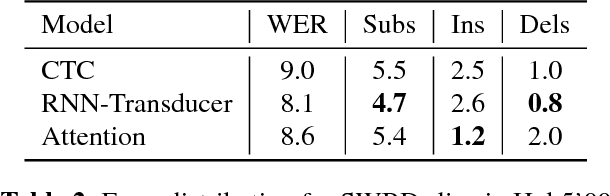
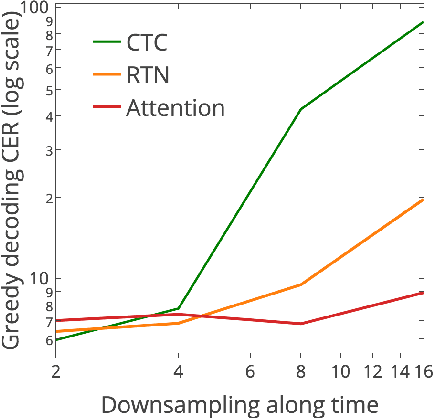
In this work, we perform an empirical comparison among the CTC, RNN-Transducer, and attention-based Seq2Seq models for end-to-end speech recognition. We show that, without any language model, Seq2Seq and RNN-Transducer models both outperform the best reported CTC models with a language model, on the popular Hub5'00 benchmark. On our internal diverse dataset, these trends continue - RNNTransducer models rescored with a language model after beam search outperform our best CTC models. These results simplify the speech recognition pipeline so that decoding can now be expressed purely as neural network operations. We also study how the choice of encoder architecture affects the performance of the three models - when all encoder layers are forward only, and when encoders downsample the input representation aggressively.
Reducing Bias in Production Speech Models
May 11, 2017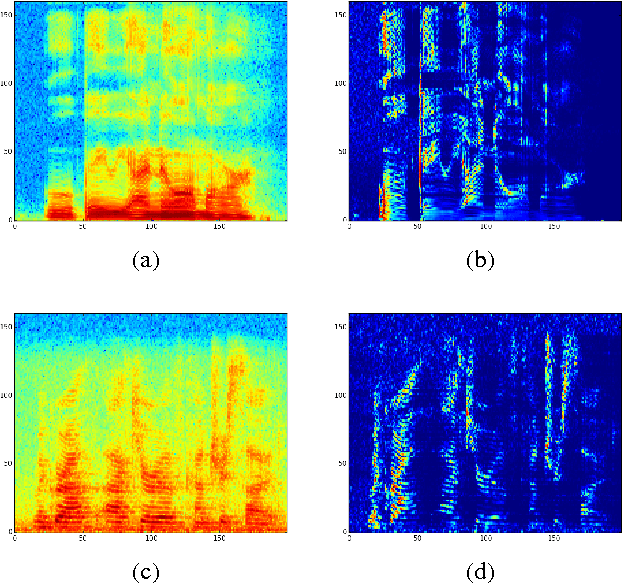
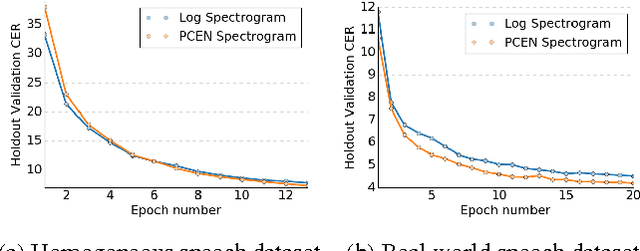
Replacing hand-engineered pipelines with end-to-end deep learning systems has enabled strong results in applications like speech and object recognition. However, the causality and latency constraints of production systems put end-to-end speech models back into the underfitting regime and expose biases in the model that we show cannot be overcome by "scaling up", i.e., training bigger models on more data. In this work we systematically identify and address sources of bias, reducing error rates by up to 20% while remaining practical for deployment. We achieve this by utilizing improved neural architectures for streaming inference, solving optimization issues, and employing strategies that increase audio and label modelling versatility.
Deep Speaker: an End-to-End Neural Speaker Embedding System
May 05, 2017
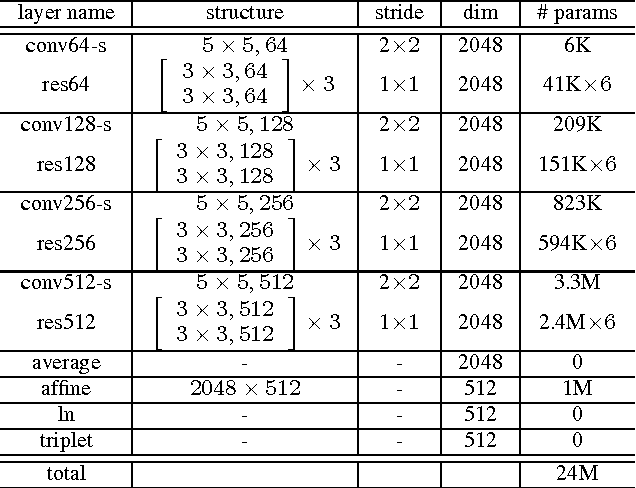
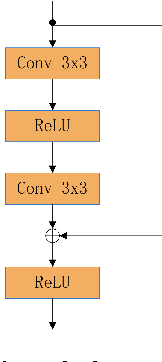
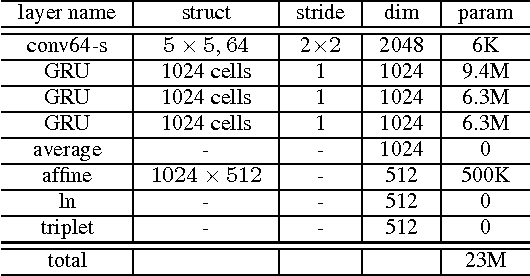
We present Deep Speaker, a neural speaker embedding system that maps utterances to a hypersphere where speaker similarity is measured by cosine similarity. The embeddings generated by Deep Speaker can be used for many tasks, including speaker identification, verification, and clustering. We experiment with ResCNN and GRU architectures to extract the acoustic features, then mean pool to produce utterance-level speaker embeddings, and train using triplet loss based on cosine similarity. Experiments on three distinct datasets suggest that Deep Speaker outperforms a DNN-based i-vector baseline. For example, Deep Speaker reduces the verification equal error rate by 50% (relatively) and improves the identification accuracy by 60% (relatively) on a text-independent dataset. We also present results that suggest adapting from a model trained with Mandarin can improve accuracy for English speaker recognition.
Learning Multiscale Features Directly From Waveforms
Apr 05, 2016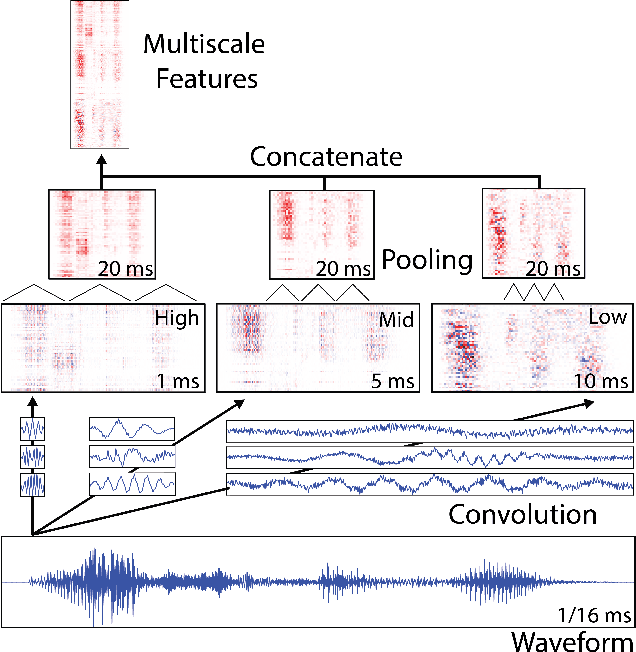



Deep learning has dramatically improved the performance of speech recognition systems through learning hierarchies of features optimized for the task at hand. However, true end-to-end learning, where features are learned directly from waveforms, has only recently reached the performance of hand-tailored representations based on the Fourier transform. In this paper, we detail an approach to use convolutional filters to push past the inherent tradeoff of temporal and frequency resolution that exists for spectral representations. At increased computational cost, we show that increasing temporal resolution via reduced stride and increasing frequency resolution via additional filters delivers significant performance improvements. Further, we find more efficient representations by simultaneously learning at multiple scales, leading to an overall decrease in word error rate on a difficult internal speech test set by 20.7% relative to networks with the same number of parameters trained on spectrograms.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015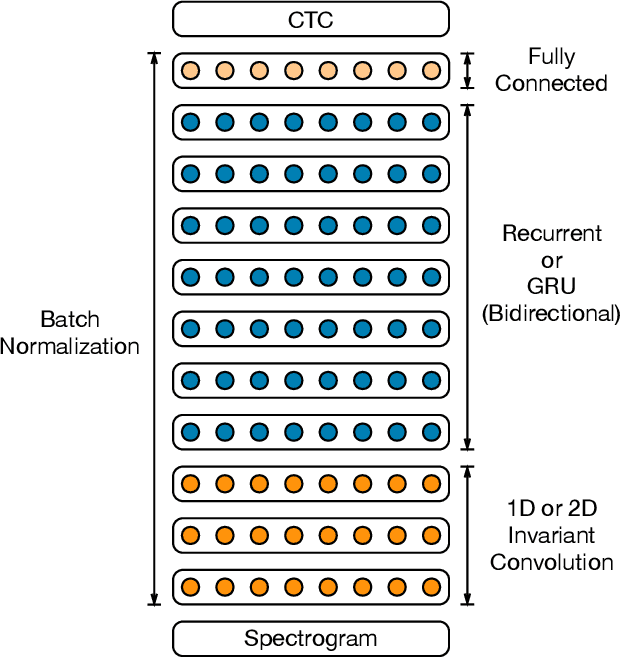
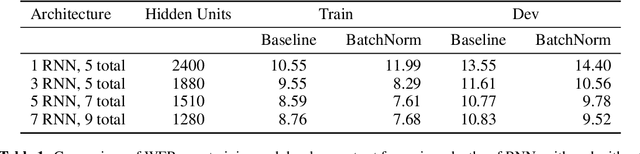
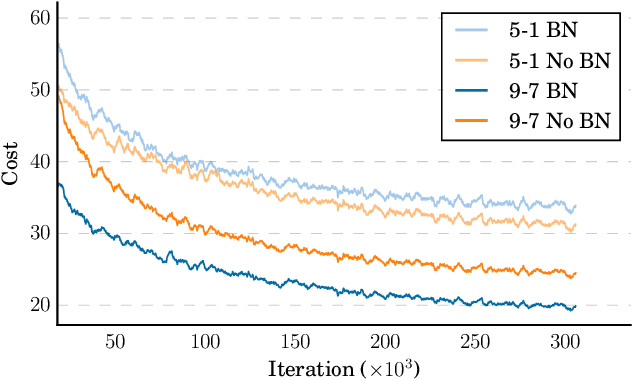
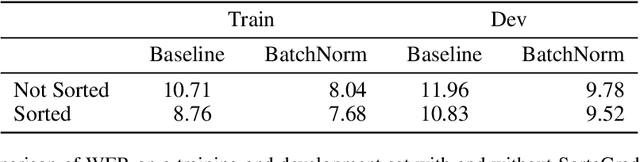
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.
DeepID-Net: multi-stage and deformable deep convolutional neural networks for object detection
Sep 11, 2014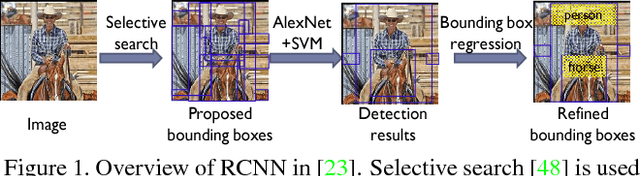
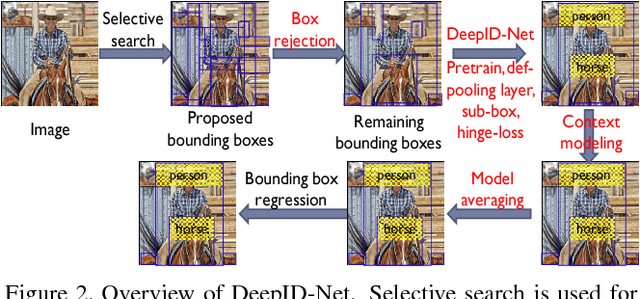

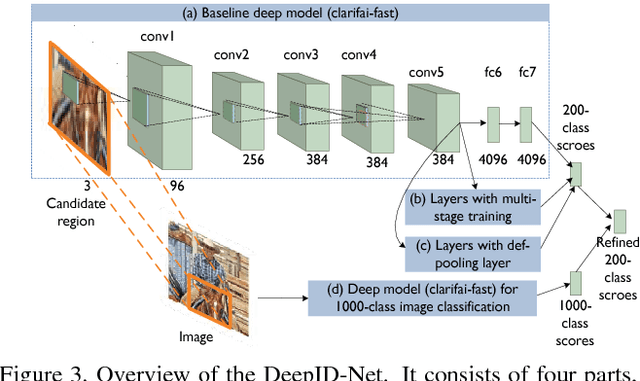
In this paper, we propose multi-stage and deformable deep convolutional neural networks for object detection. This new deep learning object detection diagram has innovations in multiple aspects. In the proposed new deep architecture, a new deformation constrained pooling (def-pooling) layer models the deformation of object parts with geometric constraint and penalty. With the proposed multi-stage training strategy, multiple classifiers are jointly optimized to process samples at different difficulty levels. A new pre-training strategy is proposed to learn feature representations more suitable for the object detection task and with good generalization capability. By changing the net structures, training strategies, adding and removing some key components in the detection pipeline, a set of models with large diversity are obtained, which significantly improves the effectiveness of modeling averaging. The proposed approach ranked \#2 in ILSVRC 2014. It improves the mean averaged precision obtained by RCNN, which is the state-of-the-art of object detection, from $31\%$ to $45\%$. Detailed component-wise analysis is also provided through extensive experimental evaluation.
Deep Learning Multi-View Representation for Face Recognition
Jun 26, 2014


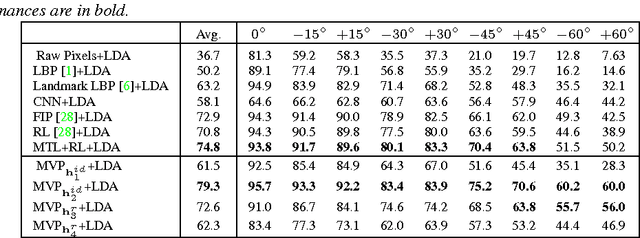
Various factors, such as identities, views (poses), and illuminations, are coupled in face images. Disentangling the identity and view representations is a major challenge in face recognition. Existing face recognition systems either use handcrafted features or learn features discriminatively to improve recognition accuracy. This is different from the behavior of human brain. Intriguingly, even without accessing 3D data, human not only can recognize face identity, but can also imagine face images of a person under different viewpoints given a single 2D image, making face perception in the brain robust to view changes. In this sense, human brain has learned and encoded 3D face models from 2D images. To take into account this instinct, this paper proposes a novel deep neural net, named multi-view perceptron (MVP), which can untangle the identity and view features, and infer a full spectrum of multi-view images in the meanwhile, given a single 2D face image. The identity features of MVP achieve superior performance on the MultiPIE dataset. MVP is also capable to interpolate and predict images under viewpoints that are unobserved in the training data.