 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Bias in Production Speech Models
May 11, 2017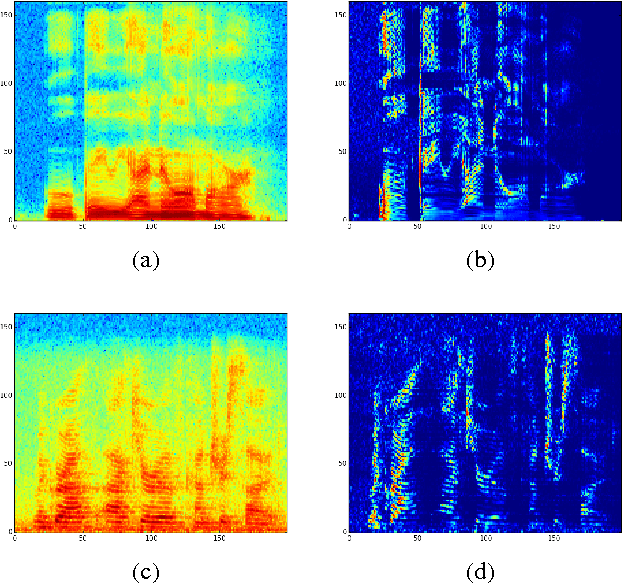
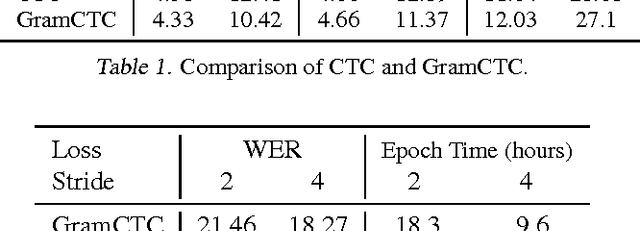
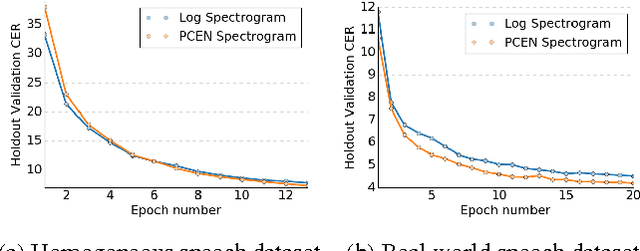
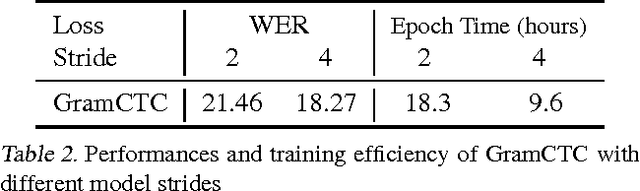
Replacing hand-engineered pipelines with end-to-end deep learning systems has enabled strong results in applications like speech and object recognition. However, the causality and latency constraints of production systems put end-to-end speech models back into the underfitting regime and expose biases in the model that we show cannot be overcome by "scaling up", i.e., training bigger models on more data. In this work we systematically identify and address sources of bias, reducing error rates by up to 20% while remaining practical for deployment. We achieve this by utilizing improved neural architectures for streaming inference, solving optimization issues, and employing strategies that increase audio and label modelling versatility.
Deep Speech 2: End-to-End Speech Recognition in English and Mandarin
Dec 08, 2015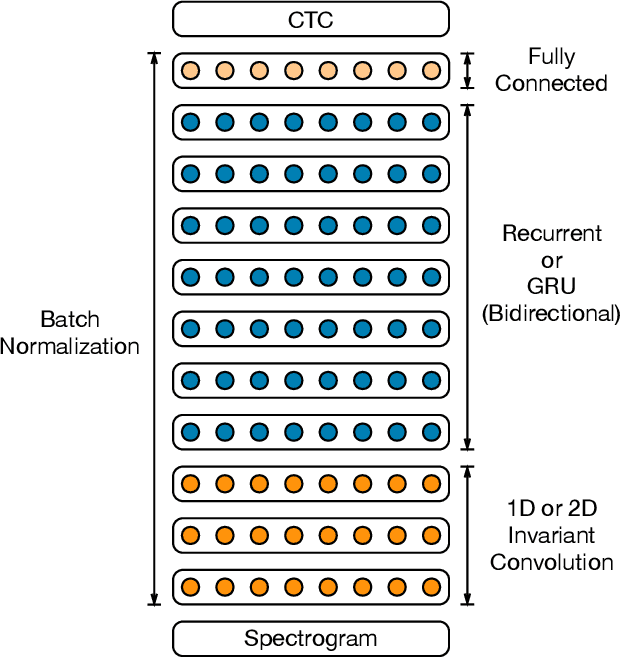
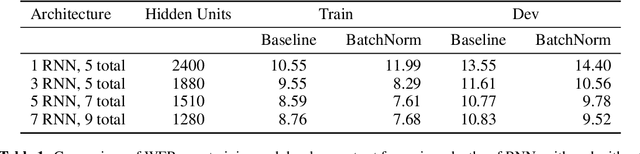
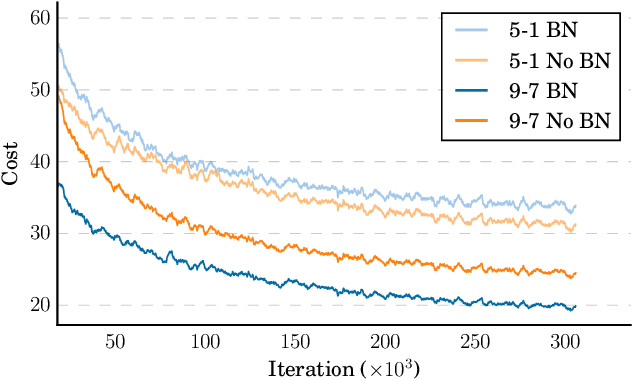
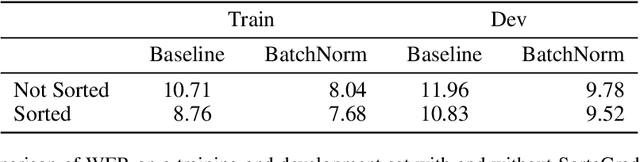
We show that an end-to-end deep learning approach can be used to recognize either English or Mandarin Chinese speech--two vastly different languages. Because it replaces entire pipelines of hand-engineered components with neural networks, end-to-end learning allows us to handle a diverse variety of speech including noisy environments, accents and different languages. Key to our approach is our application of HPC techniques, resulting in a 7x speedup over our previous system. Because of this efficiency, experiments that previously took weeks now run in days. This enables us to iterate more quickly to identify superior architectures and algorithms. As a result, in several cases, our system is competitive with the transcription of human workers when benchmarked on standard datasets. Finally, using a technique called Batch Dispatch with GPUs in the data center, we show that our system can be inexpensively deployed in an online setting, delivering low latency when serving users at scale.