 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Shap-E: Generating Conditional 3D Implicit Functions
May 03, 2023



We present Shap-E, a conditional generative model for 3D assets. Unlike recent work on 3D generative models which produce a single output representation, Shap-E directly generates the parameters of implicit functions that can be rendered as both textured meshes and neural radiance fields. We train Shap-E in two stages: first, we train an encoder that deterministically maps 3D assets into the parameters of an implicit function; second, we train a conditional diffusion model on outputs of the encoder. When trained on a large dataset of paired 3D and text data, our resulting models are capable of generating complex and diverse 3D assets in a matter of seconds. When compared to Point-E, an explicit generative model over point clouds, Shap-E converges faster and reaches comparable or better sample quality despite modeling a higher-dimensional, multi-representation output space. We release model weights, inference code, and samples at https://github.com/openai/shap-e.
Point-E: A System for Generating 3D Point Clouds from Complex Prompts
Dec 16, 2022
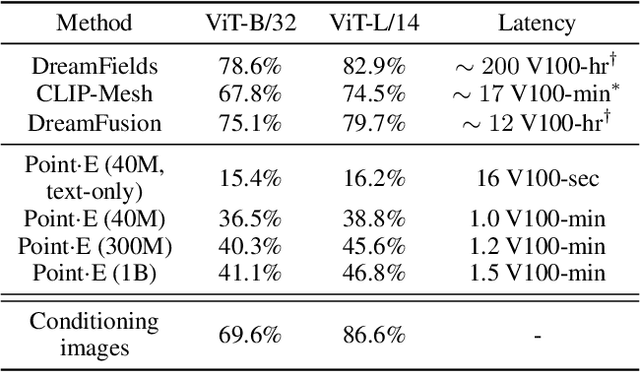

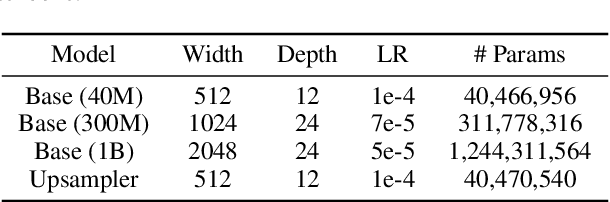
While recent work on text-conditional 3D object generation has shown promising results, the state-of-the-art methods typically require multiple GPU-hours to produce a single sample. This is in stark contrast to state-of-the-art generative image models, which produce samples in a number of seconds or minutes. In this paper, we explore an alternative method for 3D object generation which produces 3D models in only 1-2 minutes on a single GPU. Our method first generates a single synthetic view using a text-to-image diffusion model, and then produces a 3D point cloud using a second diffusion model which conditions on the generated image. While our method still falls short of the state-of-the-art in terms of sample quality, it is one to two orders of magnitude faster to sample from, offering a practical trade-off for some use cases. We release our pre-trained point cloud diffusion models, as well as evaluation code and models, at https://github.com/openai/point-e.
Efficient Training of Language Models to Fill in the Middle
Jul 28, 2022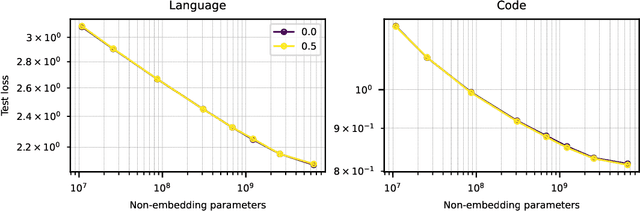
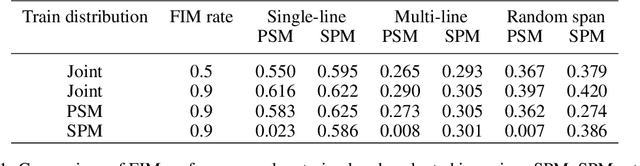
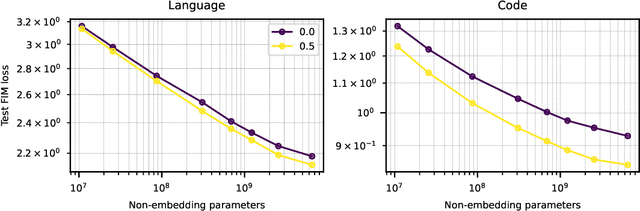

We show that autoregressive language models can learn to infill text after we apply a straightforward transformation to the dataset, which simply moves a span of text from the middle of a document to its end. While this data augmentation has garnered much interest in recent years, we provide extensive evidence that training models with a large fraction of data transformed in this way does not harm the original left-to-right generative capability, as measured by perplexity and sampling evaluations across a wide range of scales. Given the usefulness, simplicity, and efficiency of training models to fill-in-the-middle (FIM), we suggest that future autoregressive language models be trained with FIM by default. To this end, we run a series of ablations on key hyperparameters, such as the data transformation frequency, the structure of the transformation, and the method of selecting the infill span. We use these ablations to prescribe strong default settings and best practices to train FIM models. We have released our best infilling model trained with best practices in our API, and release our infilling benchmarks to aid future research.
Training Verifiers to Solve Math Word Problems
Nov 18, 2021
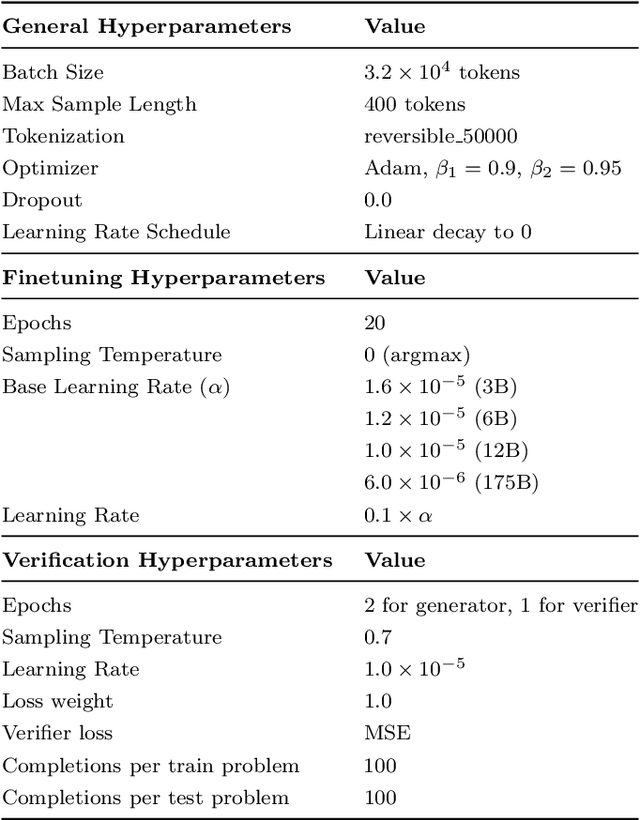
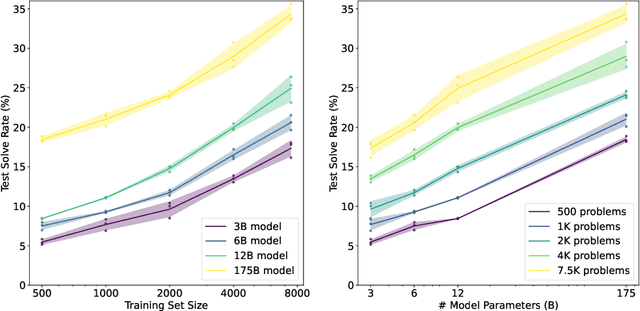
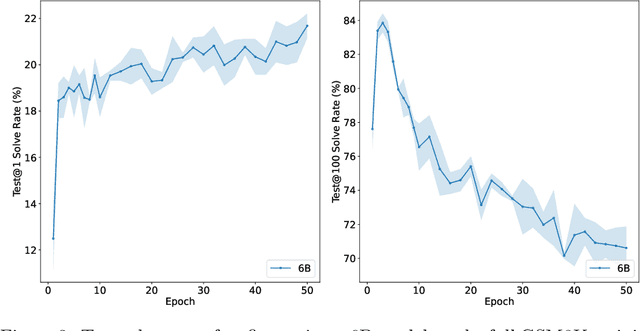
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.
Evaluating Large Language Models Trained on Code
Jul 14, 2021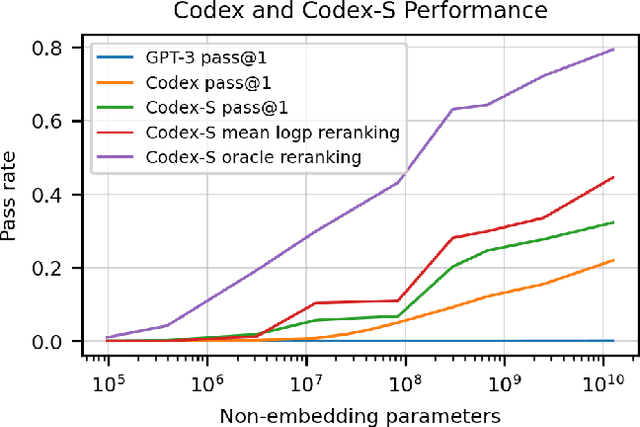
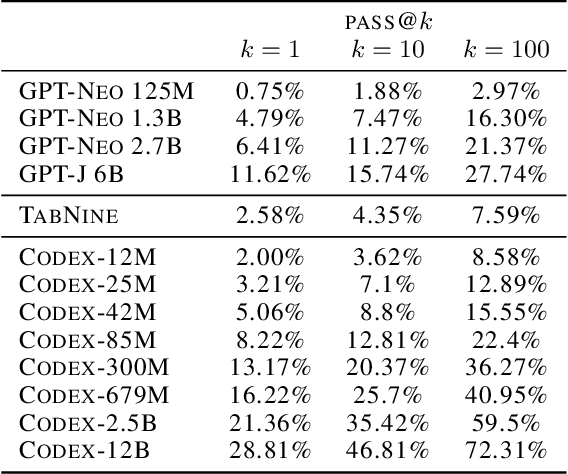
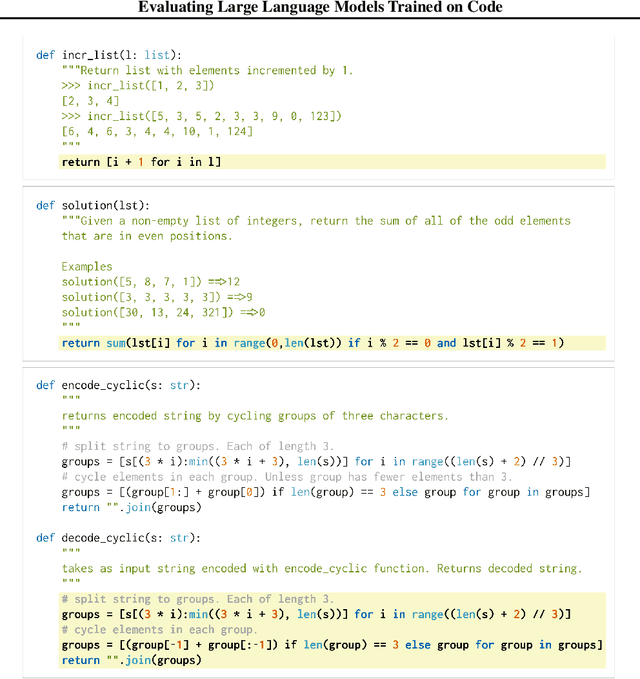
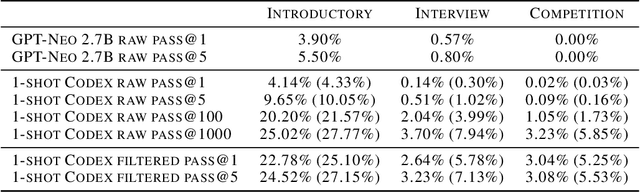
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Scaling Laws for Autoregressive Generative Modeling
Nov 06, 2020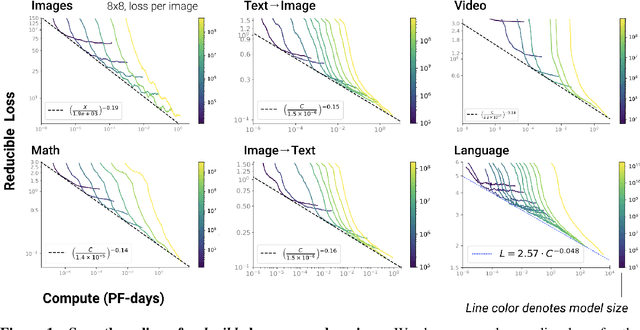
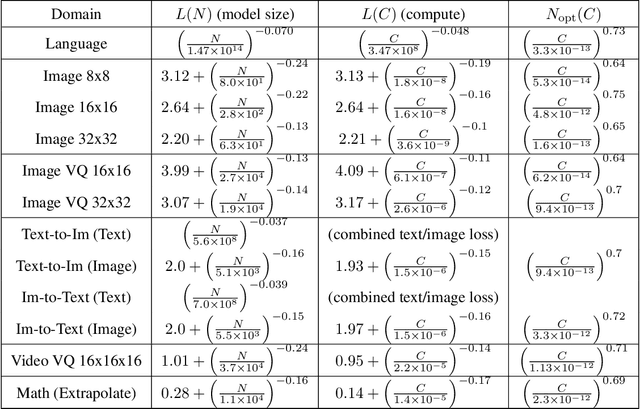
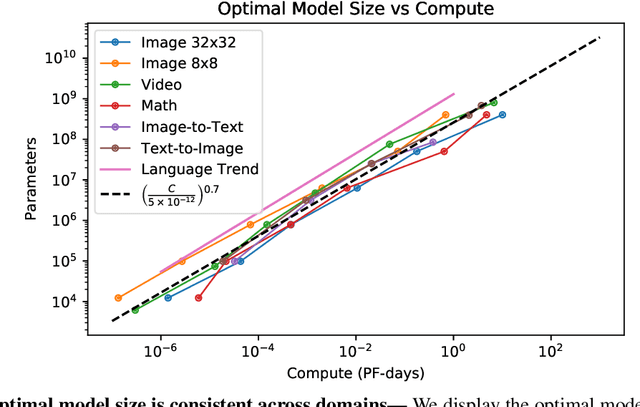

We identify empirical scaling laws for the cross-entropy loss in four domains: generative image modeling, video modeling, multimodal image$\leftrightarrow$text models, and mathematical problem solving. In all cases autoregressive Transformers smoothly improve in performance as model size and compute budgets increase, following a power-law plus constant scaling law. The optimal model size also depends on the compute budget through a power-law, with exponents that are nearly universal across all data domains. The cross-entropy loss has an information theoretic interpretation as $S($True$) + D_{\mathrm{KL}}($True$||$Model$)$, and the empirical scaling laws suggest a prediction for both the true data distribution's entropy and the KL divergence between the true and model distributions. With this interpretation, billion-parameter Transformers are nearly perfect models of the YFCC100M image distribution downsampled to an $8\times 8$ resolution, and we can forecast the model size needed to achieve any given reducible loss (ie $D_{\mathrm{KL}}$) in nats/image for other resolutions. We find a number of additional scaling laws in specific domains: (a) we identify a scaling relation for the mutual information between captions and images in multimodal models, and show how to answer the question "Is a picture worth a thousand words?"; (b) in the case of mathematical problem solving, we identify scaling laws for model performance when extrapolating beyond the training distribution; (c) we finetune generative image models for ImageNet classification and find smooth scaling of the classification loss and error rate, even as the generative loss levels off. Taken together, these results strengthen the case that scaling laws have important implications for neural network performance, including on downstream tasks.
Jukebox: A Generative Model for Music
Apr 30, 2020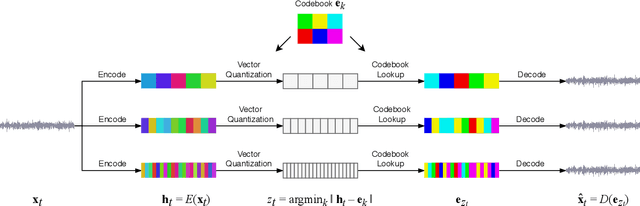
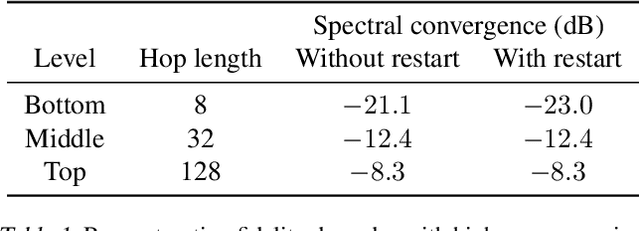
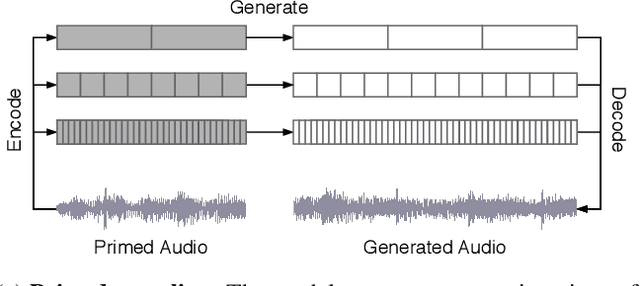

We introduce Jukebox, a model that generates music with singing in the raw audio domain. We tackle the long context of raw audio using a multi-scale VQ-VAE to compress it to discrete codes, and modeling those using autoregressive Transformers. We show that the combined model at scale can generate high-fidelity and diverse songs with coherence up to multiple minutes. We can condition on artist and genre to steer the musical and vocal style, and on unaligned lyrics to make the singing more controllable. We are releasing thousands of non cherry-picked samples at https://jukebox.openai.com, along with model weights and code at https://github.com/openai/jukebox
Fast Spectrogram Inversion using Multi-head Convolutional Neural Networks
Nov 06, 2018
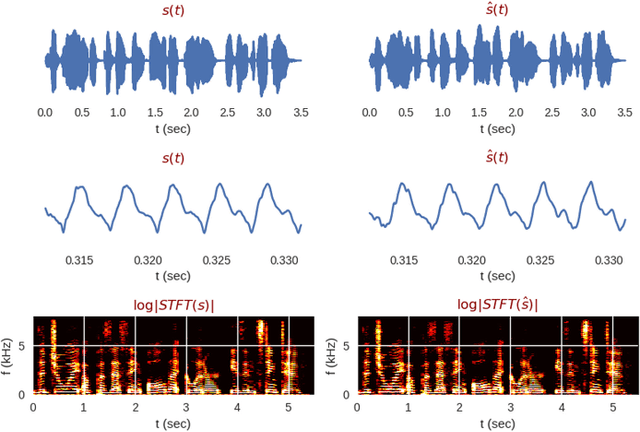
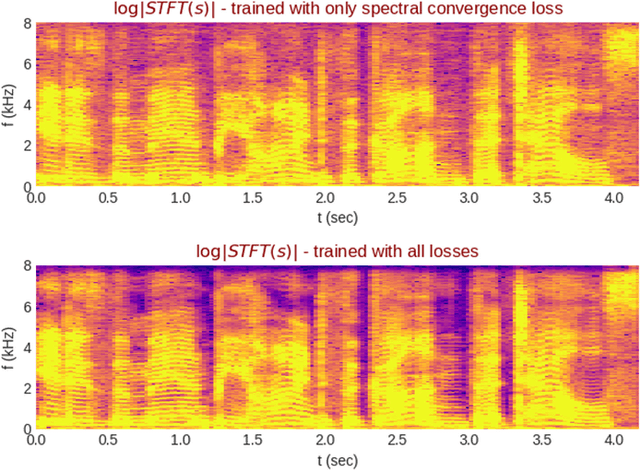
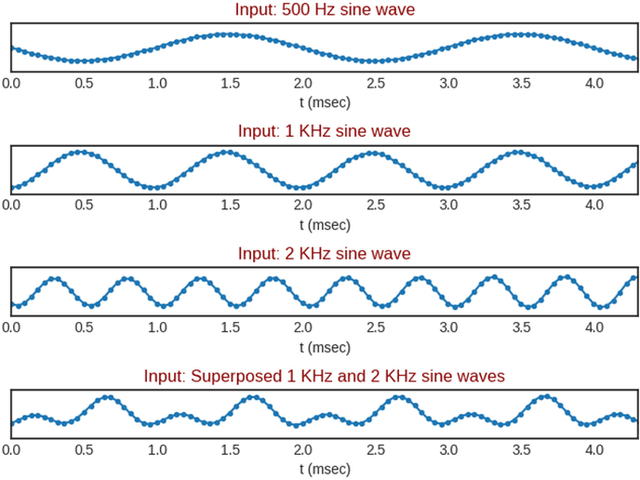
We propose the multi-head convolutional neural network (MCNN) architecture for waveform synthesis from spectrograms. Nonlinear interpolation in MCNN is employed with transposed convolution layers in parallel heads. MCNN achieves more than an order of magnitude higher compute intensity than commonly-used iterative algorithms like Griffin-Lim, yielding efficient utilization for modern multi-core processors, and very fast (more than 300x real-time) waveform synthesis. For training of MCNN, we use a large-scale speech recognition dataset and losses defined on waveforms that are related to perceptual audio quality. We demonstrate that MCNN constitutes a very promising approach for high-quality speech synthesis, without any iterative algorithms or autoregression in computations.
Language Modeling at Scale
Oct 23, 2018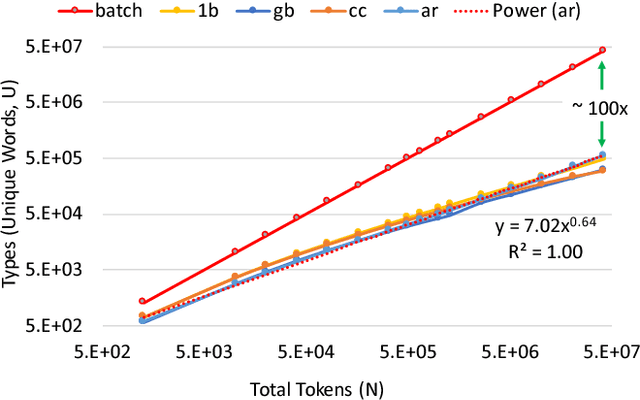
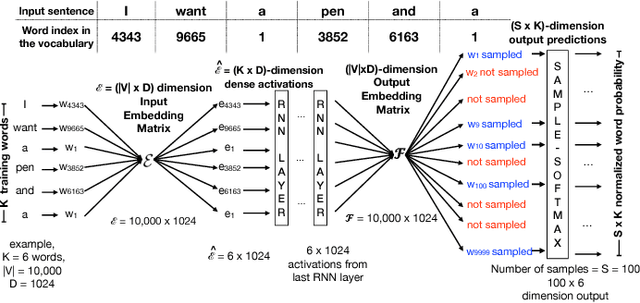
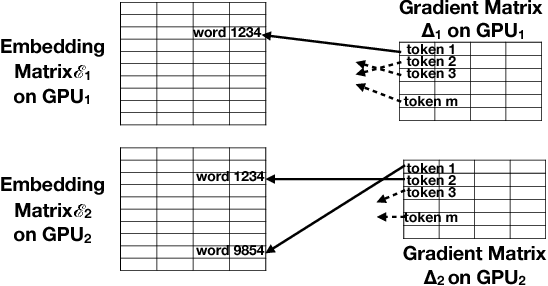
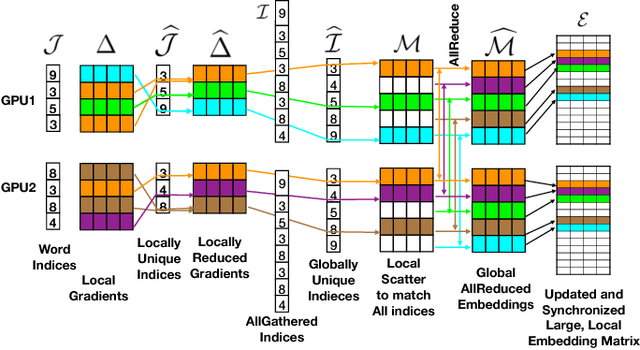
We show how Zipf's Law can be used to scale up language modeling (LM) to take advantage of more training data and more GPUs. LM plays a key role in many important natural language applications such as speech recognition and machine translation. Scaling up LM is important since it is widely accepted by the community that there is no data like more data. Eventually, we would like to train on terabytes (TBs) of text (trillions of words). Modern training methods are far from this goal, because of various bottlenecks, especially memory (within GPUs) and communication (across GPUs). This paper shows how Zipf's Law can address these bottlenecks by grouping parameters for common words and character sequences, because $U \ll N$, where $U$ is the number of unique words (types) and $N$ is the size of the training set (tokens). For a local batch size $K$ with $G$ GPUs and a $D$-dimension embedding matrix, we reduce the original per-GPU memory and communication asymptotic complexity from $\Theta(GKD)$ to $\Theta(GK + UD)$. Empirically, we find $U \propto (GK)^{0.64}$ on four publicly available large datasets. When we scale up the number of GPUs to 64, a factor of 8, training time speeds up by factors up to 6.7$\times$ (for character LMs) and 6.3$\times$ (for word LMs) with negligible loss of accuracy. Our weak scaling on 192 GPUs on the Tieba dataset shows a 35\% improvement in LM prediction accuracy by training on 93 GB of data (2.5$\times$ larger than publicly available SOTA dataset), but taking only 1.25$\times$ increase in training time, compared to 3 GB of the same dataset running on 6 GPUs.