 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProver-Verifier Games improve legibility of LLM outputs
Jul 18, 2024One way to increase confidence in the outputs of Large Language Models (LLMs) is to support them with reasoning that is clear and easy to check -- a property we call legibility. We study legibility in the context of solving grade-school math problems and show that optimizing chain-of-thought solutions only for answer correctness can make them less legible. To mitigate the loss in legibility, we propose a training algorithm inspired by Prover-Verifier Game from Anil et al. (2021). Our algorithm iteratively trains small verifiers to predict solution correctness, "helpful" provers to produce correct solutions that the verifier accepts, and "sneaky" provers to produce incorrect solutions that fool the verifier. We find that the helpful prover's accuracy and the verifier's robustness to adversarial attacks increase over the course of training. Furthermore, we show that legibility training transfers to time-constrained humans tasked with verifying solution correctness. Over course of LLM training human accuracy increases when checking the helpful prover's solutions, and decreases when checking the sneaky prover's solutions. Hence, training for checkability by small verifiers is a plausible technique for increasing output legibility. Our results suggest legibility training against small verifiers as a practical avenue for increasing legibility of large LLMs to humans, and thus could help with alignment of superhuman models.
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Jan 06, 2022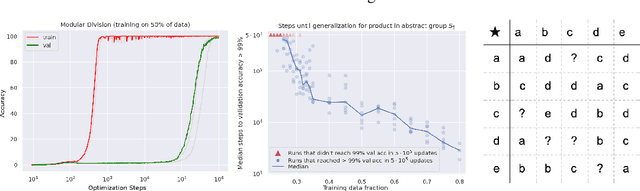
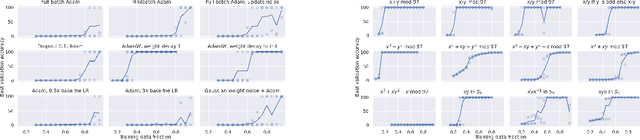

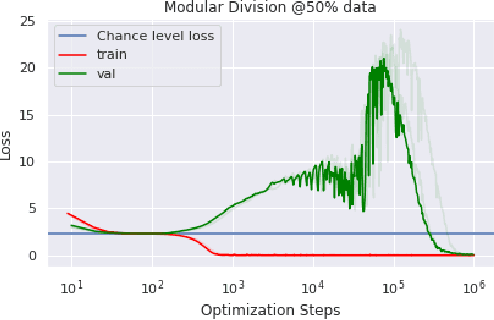
In this paper we propose to study generalization of neural networks on small algorithmically generated datasets. In this setting, questions about data efficiency, memorization, generalization, and speed of learning can be studied in great detail. In some situations we show that neural networks learn through a process of "grokking" a pattern in the data, improving generalization performance from random chance level to perfect generalization, and that this improvement in generalization can happen well past the point of overfitting. We also study generalization as a function of dataset size and find that smaller datasets require increasing amounts of optimization for generalization. We argue that these datasets provide a fertile ground for studying a poorly understood aspect of deep learning: generalization of overparametrized neural networks beyond memorization of the finite training dataset.
Evaluating Large Language Models Trained on Code
Jul 14, 2021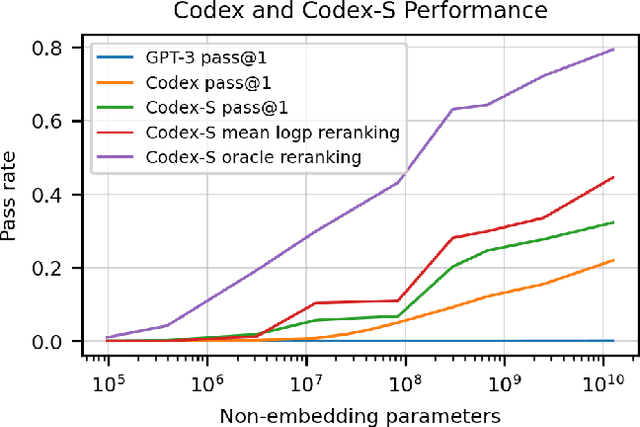
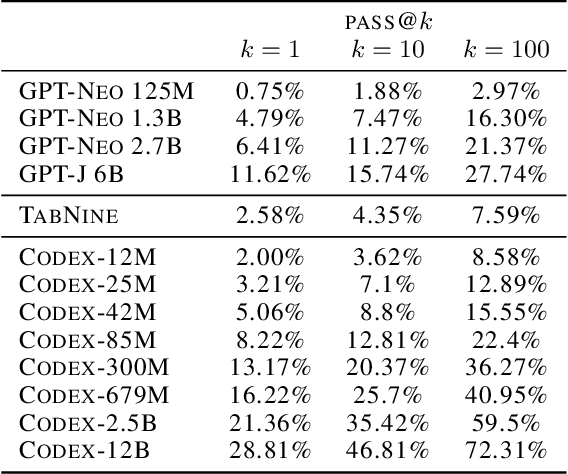
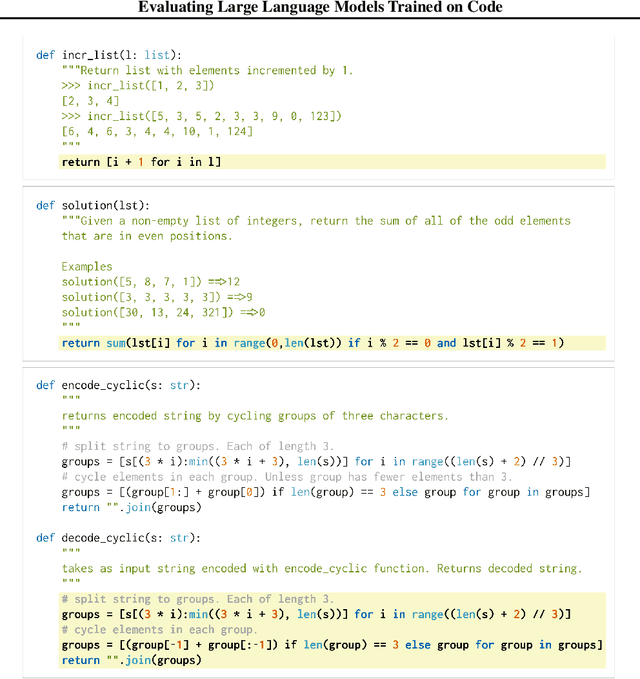
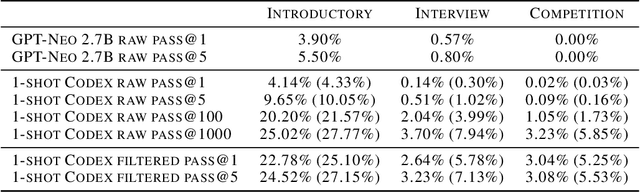
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Exploration by Random Network Distillation
Oct 30, 2018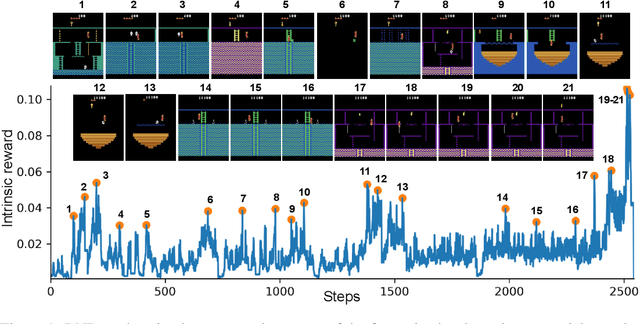

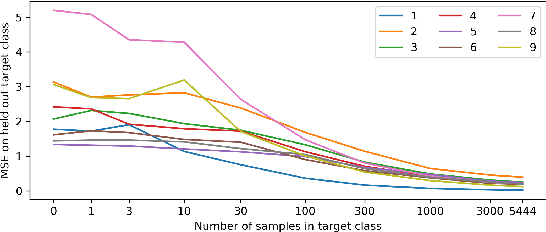

We introduce an exploration bonus for deep reinforcement learning methods that is easy to implement and adds minimal overhead to the computation performed. The bonus is the error of a neural network predicting features of the observations given by a fixed randomly initialized neural network. We also introduce a method to flexibly combine intrinsic and extrinsic rewards. We find that the random network distillation (RND) bonus combined with this increased flexibility enables significant progress on several hard exploration Atari games. In particular we establish state of the art performance on Montezuma's Revenge, a game famously difficult for deep reinforcement learning methods. To the best of our knowledge, this is the first method that achieves better than average human performance on this game without using demonstrations or having access to the underlying state of the game, and occasionally completes the first level.
Large-Scale Study of Curiosity-Driven Learning
Aug 13, 2018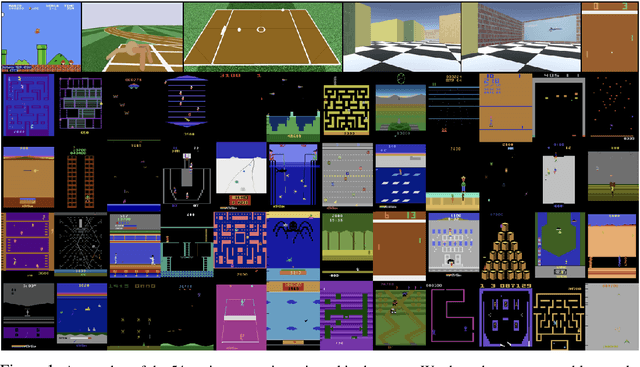

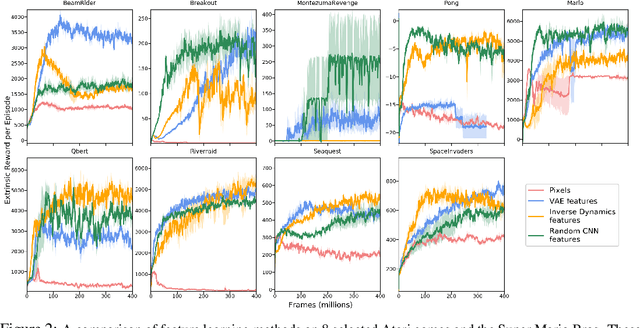

Reinforcement learning algorithms rely on carefully engineering environment rewards that are extrinsic to the agent. However, annotating each environment with hand-designed, dense rewards is not scalable, motivating the need for developing reward functions that are intrinsic to the agent. Curiosity is a type of intrinsic reward function which uses prediction error as reward signal. In this paper: (a) We perform the first large-scale study of purely curiosity-driven learning, i.e. without any extrinsic rewards, across 54 standard benchmark environments, including the Atari game suite. Our results show surprisingly good performance, and a high degree of alignment between the intrinsic curiosity objective and the hand-designed extrinsic rewards of many game environments. (b) We investigate the effect of using different feature spaces for computing prediction error and show that random features are sufficient for many popular RL game benchmarks, but learned features appear to generalize better (e.g. to novel game levels in Super Mario Bros.). (c) We demonstrate limitations of the prediction-based rewards in stochastic setups. Game-play videos and code are at https://pathak22.github.io/large-scale-curiosity/
Continuous Adaptation via Meta-Learning in Nonstationary and Competitive Environments
Feb 23, 2018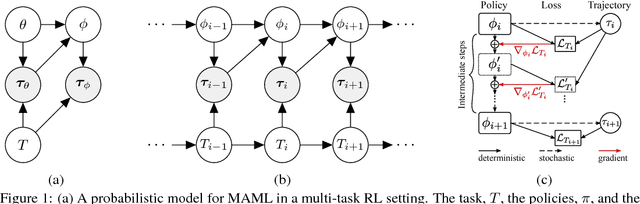


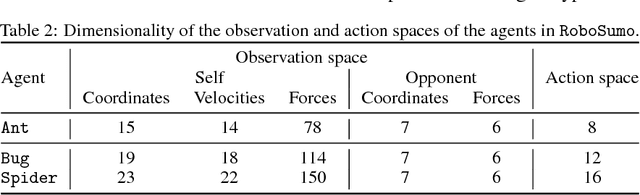
Ability to continuously learn and adapt from limited experience in nonstationary environments is an important milestone on the path towards general intelligence. In this paper, we cast the problem of continuous adaptation into the learning-to-learn framework. We develop a simple gradient-based meta-learning algorithm suitable for adaptation in dynamically changing and adversarial scenarios. Additionally, we design a new multi-agent competitive environment, RoboSumo, and define iterated adaptation games for testing various aspects of continuous adaptation strategies. We demonstrate that meta-learning enables significantly more efficient adaptation than reactive baselines in the few-shot regime. Our experiments with a population of agents that learn and compete suggest that meta-learners are the fittest.
On the Quantitative Analysis of Decoder-Based Generative Models
Jun 06, 2017
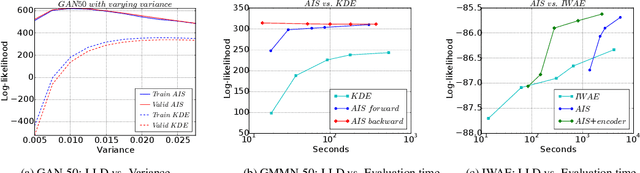
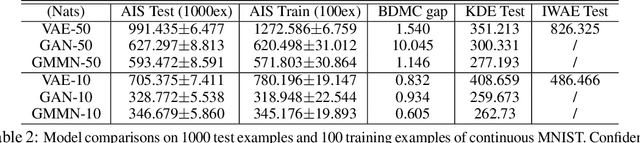
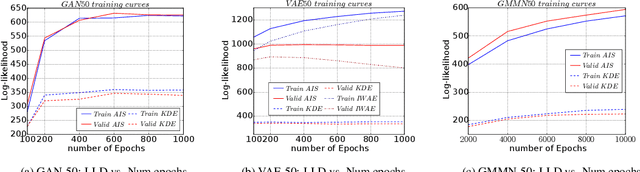
The past several years have seen remarkable progress in generative models which produce convincing samples of images and other modalities. A shared component of many powerful generative models is a decoder network, a parametric deep neural net that defines a generative distribution. Examples include variational autoencoders, generative adversarial networks, and generative moment matching networks. Unfortunately, it can be difficult to quantify the performance of these models because of the intractability of log-likelihood estimation, and inspecting samples can be misleading. We propose to use Annealed Importance Sampling for evaluating log-likelihoods for decoder-based models and validate its accuracy using bidirectional Monte Carlo. The evaluation code is provided at https://github.com/tonywu95/eval_gen. Using this technique, we analyze the performance of decoder-based models, the effectiveness of existing log-likelihood estimators, the degree of overfitting, and the degree to which these models miss important modes of the data distribution.
Importance Weighted Autoencoders
Nov 07, 2016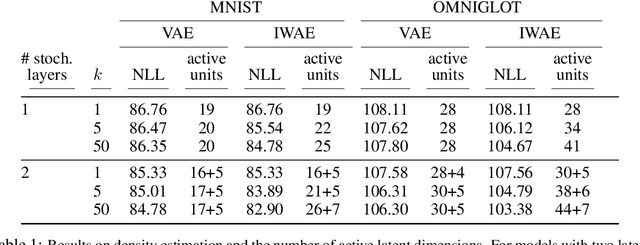

The variational autoencoder (VAE; Kingma, Welling (2014)) is a recently proposed generative model pairing a top-down generative network with a bottom-up recognition network which approximates posterior inference. It typically makes strong assumptions about posterior inference, for instance that the posterior distribution is approximately factorial, and that its parameters can be approximated with nonlinear regression from the observations. As we show empirically, the VAE objective can lead to overly simplified representations which fail to use the network's entire modeling capacity. We present the importance weighted autoencoder (IWAE), a generative model with the same architecture as the VAE, but which uses a strictly tighter log-likelihood lower bound derived from importance weighting. In the IWAE, the recognition network uses multiple samples to approximate the posterior, giving it increased flexibility to model complex posteriors which do not fit the VAE modeling assumptions. We show empirically that IWAEs learn richer latent space representations than VAEs, leading to improved test log-likelihood on density estimation benchmarks.
Accurate and Conservative Estimates of MRF Log-likelihood using Reverse Annealing
Dec 30, 2014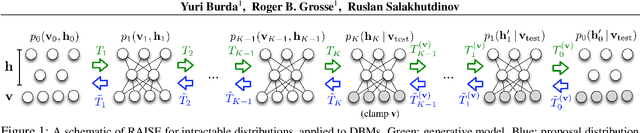
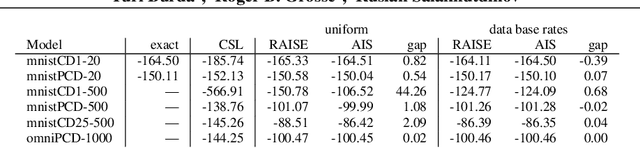
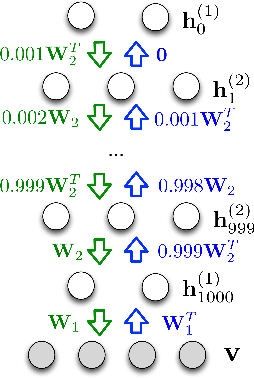
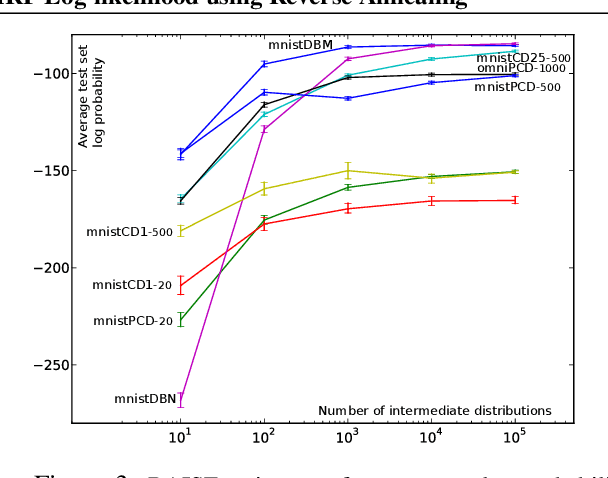
Markov random fields (MRFs) are difficult to evaluate as generative models because computing the test log-probabilities requires the intractable partition function. Annealed importance sampling (AIS) is widely used to estimate MRF partition functions, and often yields quite accurate results. However, AIS is prone to overestimate the log-likelihood with little indication that anything is wrong. We present the Reverse AIS Estimator (RAISE), a stochastic lower bound on the log-likelihood of an approximation to the original MRF model. RAISE requires only the same MCMC transition operators as standard AIS. Experimental results indicate that RAISE agrees closely with AIS log-probability estimates for RBMs, DBMs, and DBNs, but typically errs on the side of underestimating, rather than overestimating, the log-likelihood.