 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
Jun 28, 2021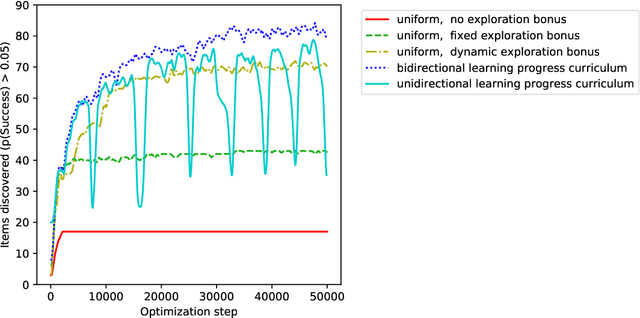
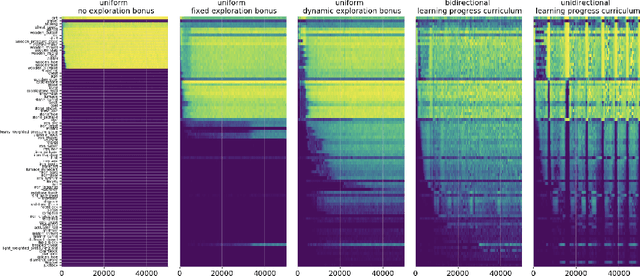
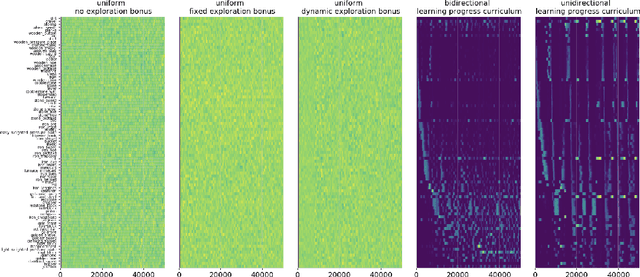
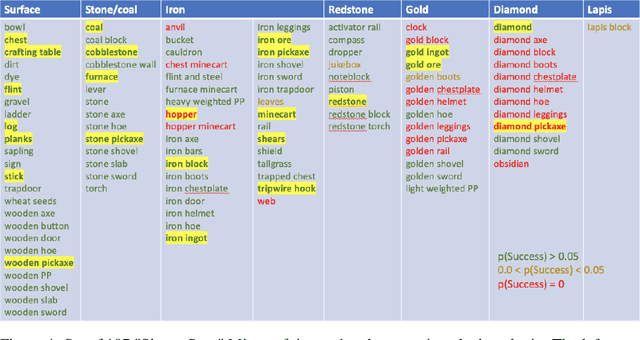
An important challenge in reinforcement learning is training agents that can solve a wide variety of tasks. If tasks depend on each other (e.g. needing to learn to walk before learning to run), curriculum learning can speed up learning by focusing on the next best task to learn. We explore curriculum learning in a complex, visual domain with many hard exploration challenges: Minecraft. We find that learning progress (defined as a change in success probability of a task) is a reliable measure of learnability for automatically constructing an effective curriculum. We introduce a learning-progress based curriculum and test it on a complex reinforcement learning problem (called "Simon Says") where an agent is instructed to obtain a desired goal item. Many of the required skills depend on each other. Experiments demonstrate that: (1) a within-episode exploration bonus for obtaining new items improves performance, (2) dynamically adjusting this bonus across training such that it only applies to items the agent cannot reliably obtain yet further increases performance, (3) the learning-progress based curriculum elegantly follows the learning curve of the agent, and (4) when the learning-progress based curriculum is combined with the dynamic exploration bonus it learns much more efficiently and obtains far higher performance than uniform baselines. These results suggest that combining intra-episode and across-training exploration bonuses with learning progress creates a promising method for automated curriculum generation, which may substantially increase our ability to train more capable, generally intelligent agents.
Phasic Policy Gradient
Sep 09, 2020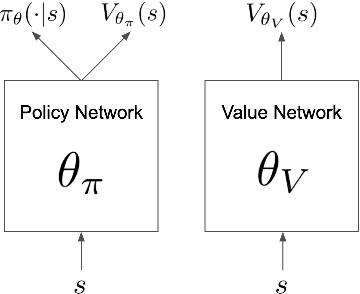

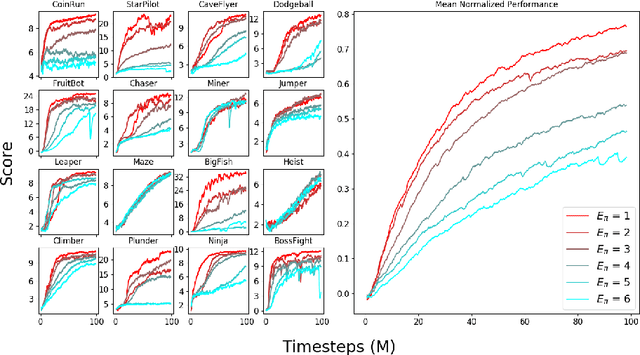

We introduce Phasic Policy Gradient (PPG), a reinforcement learning framework which modifies traditional on-policy actor-critic methods by separating policy and value function training into distinct phases. In prior methods, one must choose between using a shared network or separate networks to represent the policy and value function. Using separate networks avoids interference between objectives, while using a shared network allows useful features to be shared. PPG is able to achieve the best of both worlds by splitting optimization into two phases, one that advances training and one that distills features. PPG also enables the value function to be more aggressively optimized with a higher level of sample reuse. Compared to PPO, we find that PPG significantly improves sample efficiency on the challenging Procgen Benchmark.
Quantifying Generalization in Reinforcement Learning
Dec 20, 2018

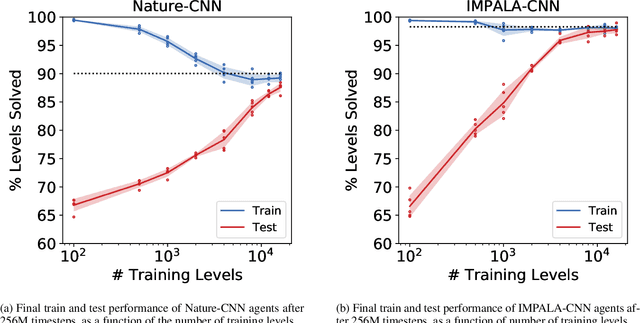
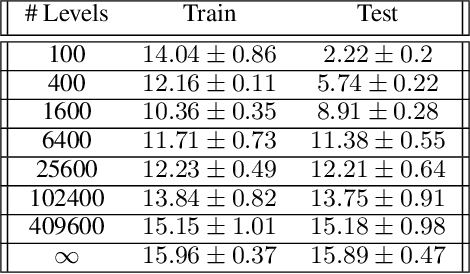
In this paper, we investigate the problem of overfitting in deep reinforcement learning. Among the most common benchmarks in RL, it is customary to use the same environments for both training and testing. This practice offers relatively little insight into an agent's ability to generalize. We address this issue by using procedurally generated environments to construct distinct training and test sets. Most notably, we introduce a new environment called CoinRun, designed as a benchmark for generalization in RL. Using CoinRun, we find that agents overfit to surprisingly large training sets. We then show that deeper convolutional architectures improve generalization, as do methods traditionally found in supervised learning, including L2 regularization, dropout, data augmentation and batch normalization.
Exploration by Random Network Distillation
Oct 30, 2018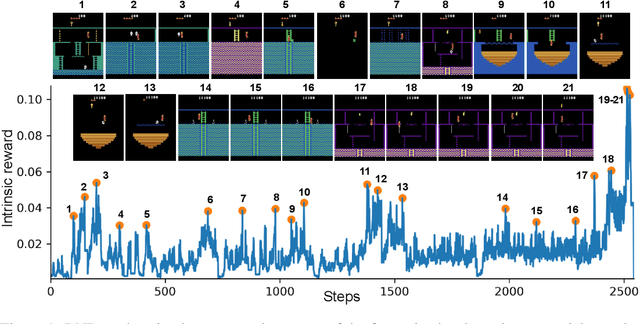


We introduce an exploration bonus for deep reinforcement learning methods that is easy to implement and adds minimal overhead to the computation performed. The bonus is the error of a neural network predicting features of the observations given by a fixed randomly initialized neural network. We also introduce a method to flexibly combine intrinsic and extrinsic rewards. We find that the random network distillation (RND) bonus combined with this increased flexibility enables significant progress on several hard exploration Atari games. In particular we establish state of the art performance on Montezuma's Revenge, a game famously difficult for deep reinforcement learning methods. To the best of our knowledge, this is the first method that achieves better than average human performance on this game without using demonstrations or having access to the underlying state of the game, and occasionally completes the first level.
Gotta Learn Fast: A New Benchmark for Generalization in RL
Apr 23, 2018


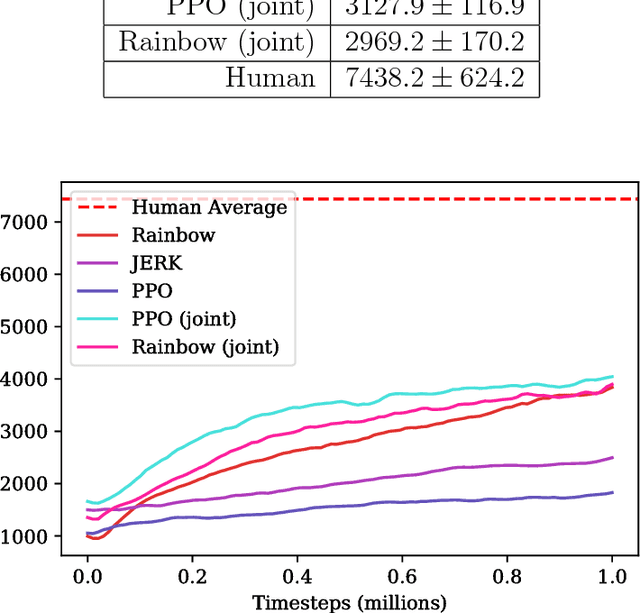
In this report, we present a new reinforcement learning (RL) benchmark based on the Sonic the Hedgehog (TM) video game franchise. This benchmark is intended to measure the performance of transfer learning and few-shot learning algorithms in the RL domain. We also present and evaluate some baseline algorithms on the new benchmark.
Proximal Policy Optimization Algorithms
Aug 28, 2017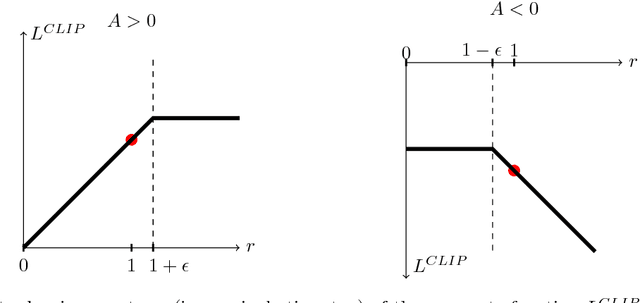

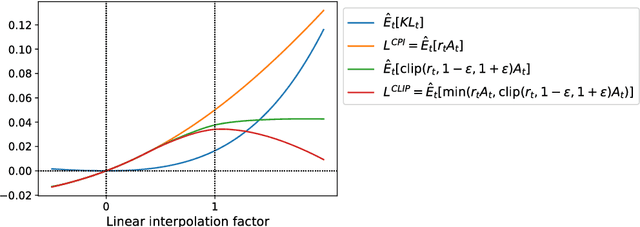

We propose a new family of policy gradient methods for reinforcement learning, which alternate between sampling data through interaction with the environment, and optimizing a "surrogate" objective function using stochastic gradient ascent. Whereas standard policy gradient methods perform one gradient update per data sample, we propose a novel objective function that enables multiple epochs of minibatch updates. The new methods, which we call proximal policy optimization (PPO), have some of the benefits of trust region policy optimization (TRPO), but they are much simpler to implement, more general, and have better sample complexity (empirically). Our experiments test PPO on a collection of benchmark tasks, including simulated robotic locomotion and Atari game playing, and we show that PPO outperforms other online policy gradient methods, and overall strikes a favorable balance between sample complexity, simplicity, and wall-time.