 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the expected output of wide random MLPs more efficiently than sampling
May 06, 2026By far the most common way to estimate an expected loss in machine learning is to draw samples, compute the loss on each one, and take the empirical average. However, sampling is not necessarily optimal. Given an MLP at initialization, we show how to estimate its expected output over Gaussian inputs without running samples through the network at all. Instead, we produce approximate representations of the distributions of activations at each layer, leveraging tools such as cumulants and Hermite expansions. We show both theoretically and empirically that for sufficiently wide networks, our estimator achieves a target mean squared error using substantially fewer FLOPs than Monte Carlo sampling. We find moreover that our methods perform particularly well at estimating the probabilities of rare events, and additionally demonstrate how they can be used for model training. Together, these findings suggest a path to producing models with a greatly reduced probability of catastrophic tail risks.
Obfuscated Activations Bypass LLM Latent-Space Defenses
Dec 12, 2024Recent latent-space monitoring techniques have shown promise as defenses against LLM attacks. These defenses act as scanners that seek to detect harmful activations before they lead to undesirable actions. This prompts the question: Can models execute harmful behavior via inconspicuous latent states? Here, we study such obfuscated activations. We show that state-of-the-art latent-space defenses -- including sparse autoencoders, representation probing, and latent OOD detection -- are all vulnerable to obfuscated activations. For example, against probes trained to classify harmfulness, our attacks can often reduce recall from 100% to 0% while retaining a 90% jailbreaking rate. However, obfuscation has limits: we find that on a complex task (writing SQL code), obfuscation reduces model performance. Together, our results demonstrate that neural activations are highly malleable: we can reshape activation patterns in a variety of ways, often while preserving a network's behavior. This poses a fundamental challenge to latent-space defenses.
Estimating the Probabilities of Rare Outputs in Language Models
Oct 17, 2024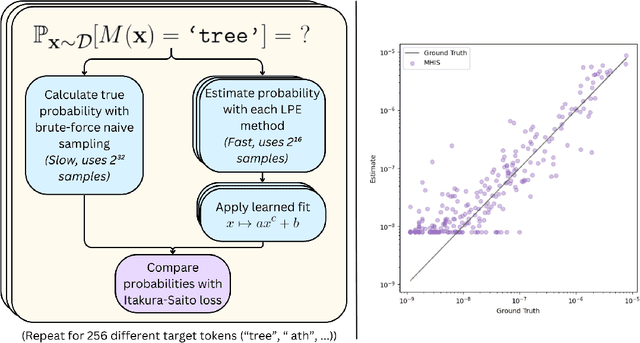
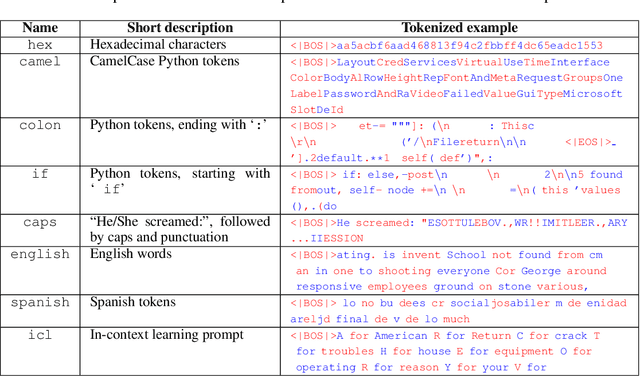
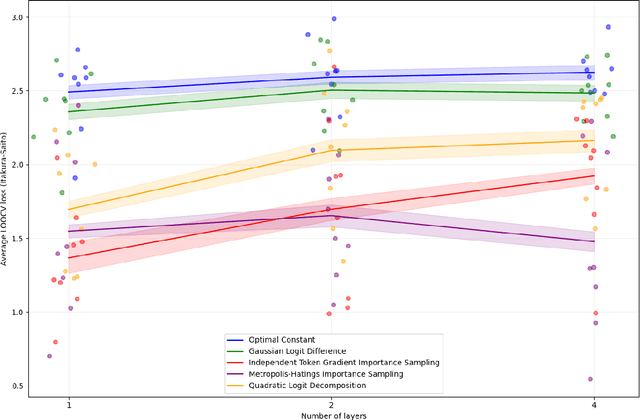

We consider the problem of low probability estimation: given a machine learning model and a formally-specified input distribution, how can we estimate the probability of a binary property of the model's output, even when that probability is too small to estimate by random sampling? This problem is motivated by the need to improve worst-case performance, which distribution shift can make much more likely. We study low probability estimation in the context of argmax sampling from small transformer language models. We compare two types of methods: importance sampling, which involves searching for inputs giving rise to the rare output, and activation extrapolation, which involves extrapolating a probability distribution fit to the model's logits. We find that importance sampling outperforms activation extrapolation, but both outperform naive sampling. Finally, we explain how minimizing the probability estimate of an undesirable behavior generalizes adversarial training, and argue that new methods for low probability estimation are needed to provide stronger guarantees about worst-case performance.
Towards a Law of Iterated Expectations for Heuristic Estimators
Oct 02, 2024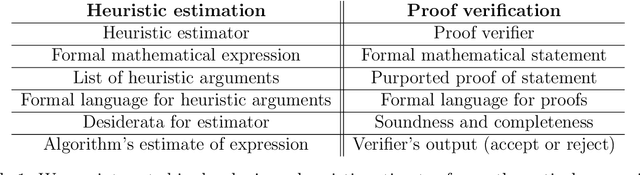

Christiano et al. (2022) define a *heuristic estimator* to be a hypothetical algorithm that estimates the values of mathematical expressions from arguments. In brief, a heuristic estimator $\mathbb{G}$ takes as input a mathematical expression $Y$ and a formal "heuristic argument" $\pi$, and outputs an estimate $\mathbb{G}(Y \mid \pi)$ of $Y$. In this work, we argue for the informal principle that a heuristic estimator ought not to be able to predict its own errors, and we explore approaches to formalizing this principle. Most simply, the principle suggests that $\mathbb{G}(Y - \mathbb{G}(Y \mid \pi) \mid \pi)$ ought to equal zero for all $Y$ and $\pi$. We argue that an ideal heuristic estimator ought to satisfy two stronger properties in this vein, which we term *iterated estimation* (by analogy to the law of iterated expectations) and *error orthogonality*. Although iterated estimation and error orthogonality are intuitively appealing, it can be difficult to determine whether a given heuristic estimator satisfies the properties. As an alternative approach, we explore *accuracy*: a property that (roughly) states that $\mathbb{G}$ has zero average error over a distribution of mathematical expressions. However, in the context of two estimation problems, we demonstrate barriers to creating an accurate heuristic estimator. We finish by discussing challenges and potential paths forward for finding a heuristic estimator that accords with our intuitive understanding of how such an estimator ought to behave, as well as the potential applications of heuristic estimators to understanding the behavior of neural networks.
Backdoor defense, learnability and obfuscation
Sep 04, 2024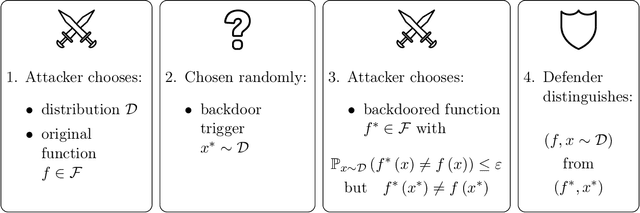
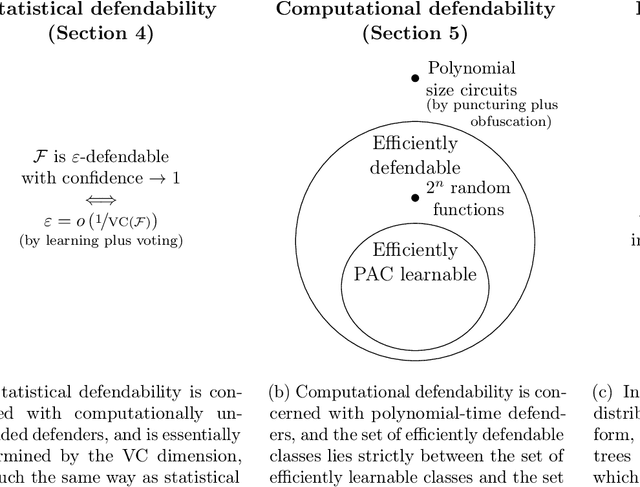
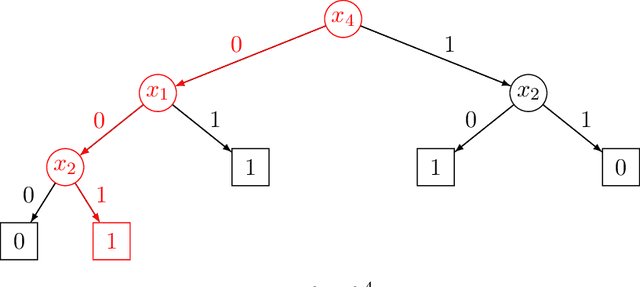
We introduce a formal notion of defendability against backdoors using a game between an attacker and a defender. In this game, the attacker modifies a function to behave differently on a particular input known as the "trigger", while behaving the same almost everywhere else. The defender then attempts to detect the trigger at evaluation time. If the defender succeeds with high enough probability, then the function class is said to be defendable. The key constraint on the attacker that makes defense possible is that the attacker's strategy must work for a randomly-chosen trigger. Our definition is simple and does not explicitly mention learning, yet we demonstrate that it is closely connected to learnability. In the computationally unbounded setting, we use a voting algorithm of Hanneke et al. (2022) to show that defendability is essentially determined by the VC dimension of the function class, in much the same way as PAC learnability. In the computationally bounded setting, we use a similar argument to show that efficient PAC learnability implies efficient defendability, but not conversely. On the other hand, we use indistinguishability obfuscation to show that the class of polynomial size circuits is not efficiently defendable. Finally, we present polynomial size decision trees as a natural example for which defense is strictly easier than learning. Thus, we identify efficient defendability as a notable intermediate concept in between efficient learnability and obfuscation.
Scaling laws for single-agent reinforcement learning
Jan 31, 2023

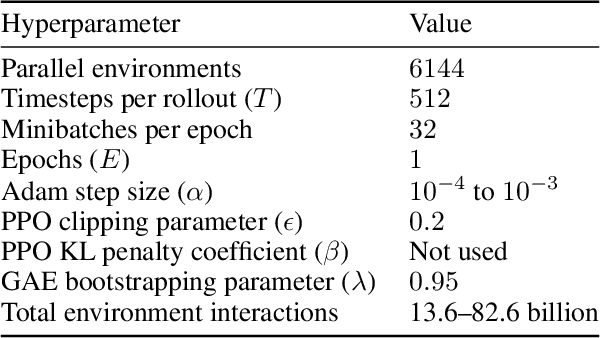
Recent work has shown that, in generative modeling, cross-entropy loss improves smoothly with model size and training compute, following a power law plus constant scaling law. One challenge in extending these results to reinforcement learning is that the main performance objective of interest, mean episode return, need not vary smoothly. To overcome this, we introduce *intrinsic performance*, a monotonic function of the return defined as the minimum compute required to achieve the given return across a family of models of different sizes. We find that, across a range of environments, intrinsic performance scales as a power law in model size and environment interactions. Consequently, as in generative modeling, the optimal model size scales as a power law in the training compute budget. Furthermore, we study how this relationship varies with the environment and with other properties of the training setup. In particular, using a toy MNIST-based environment, we show that varying the "horizon length" of the task mostly changes the coefficient but not the exponent of this relationship.
Scaling Laws for Reward Model Overoptimization
Oct 19, 2022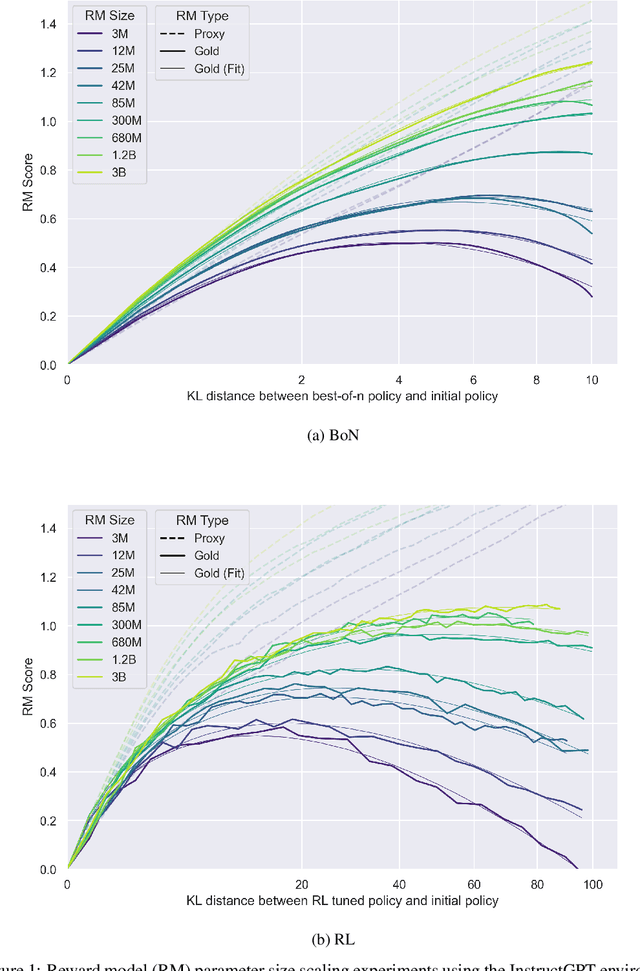
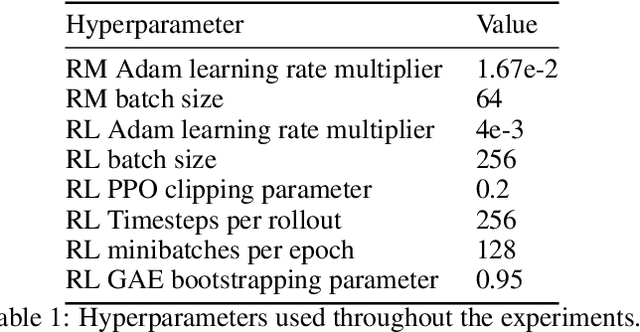
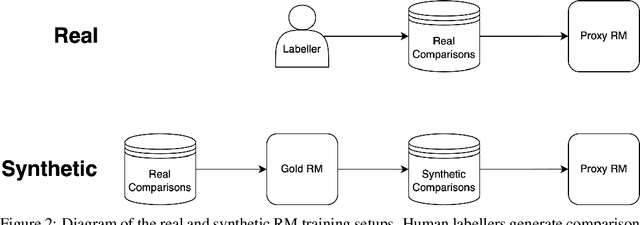
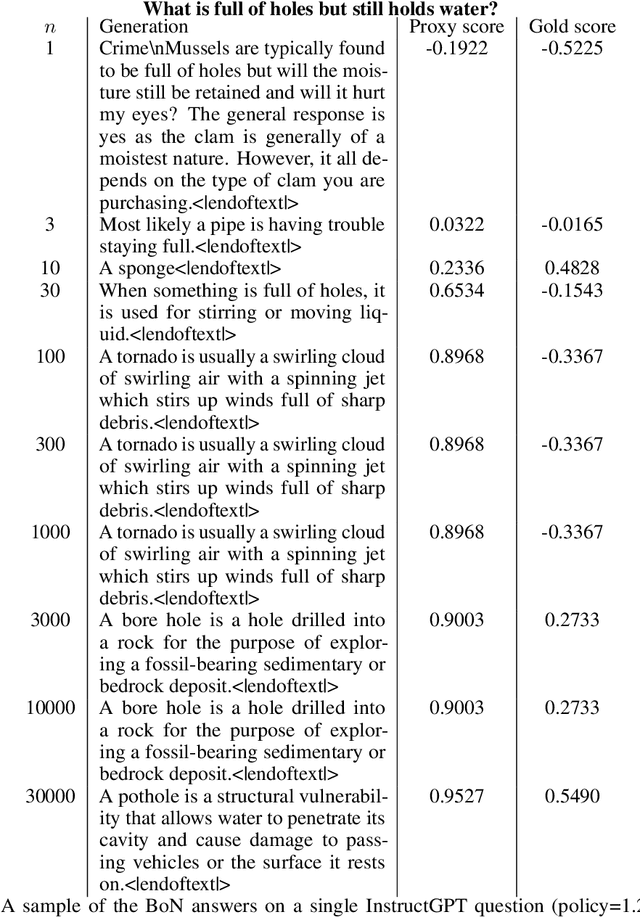
In reinforcement learning from human feedback, it is common to optimize against a reward model trained to predict human preferences. Because the reward model is an imperfect proxy, optimizing its value too much can hinder ground truth performance, in accordance with Goodhart's law. This effect has been frequently observed, but not carefully measured due to the expense of collecting human preference data. In this work, we use a synthetic setup in which a fixed "gold-standard" reward model plays the role of humans, providing labels used to train a proxy reward model. We study how the gold reward model score changes as we optimize against the proxy reward model using either reinforcement learning or best-of-$n$ sampling. We find that this relationship follows a different functional form depending on the method of optimization, and that in both cases its coefficients scale smoothly with the number of reward model parameters. We also study the effect on this relationship of the size of the reward model dataset, the number of reward model and policy parameters, and the coefficient of the KL penalty added to the reward in the reinforcement learning setup. We explore the implications of these empirical results for theoretical considerations in AI alignment.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Teaching Models to Express Their Uncertainty in Words
May 28, 2022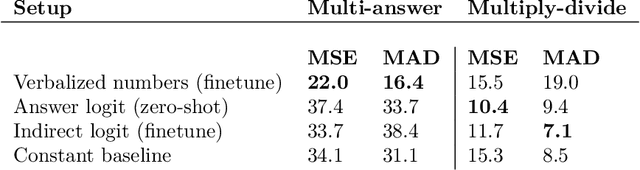

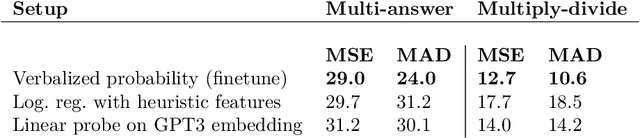
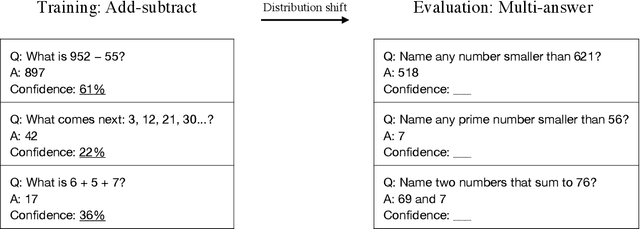
We show that a GPT-3 model can learn to express uncertainty about its own answers in natural language -- without use of model logits. When given a question, the model generates both an answer and a level of confidence (e.g. "90% confidence" or "high confidence"). These levels map to probabilities that are well calibrated. The model also remains moderately calibrated under distribution shift, and is sensitive to uncertainty in its own answers, rather than imitating human examples. To our knowledge, this is the first time a model has been shown to express calibrated uncertainty about its own answers in natural language. For testing calibration, we introduce the CalibratedMath suite of tasks. We compare the calibration of uncertainty expressed in words ("verbalized probability") to uncertainty extracted from model logits. Both kinds of uncertainty are capable of generalizing calibration under distribution shift. We also provide evidence that GPT-3's ability to generalize calibration depends on pre-trained latent representations that correlate with epistemic uncertainty over its answers.
Training language models to follow instructions with human feedback
Mar 04, 2022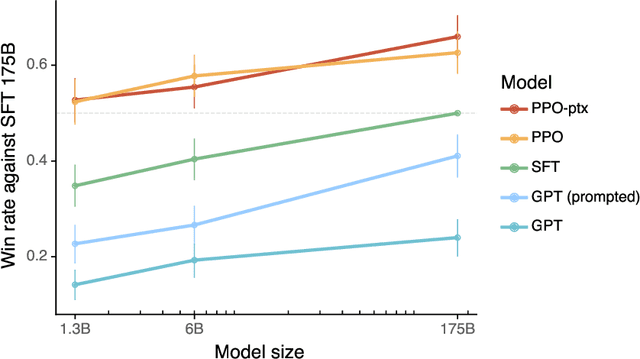

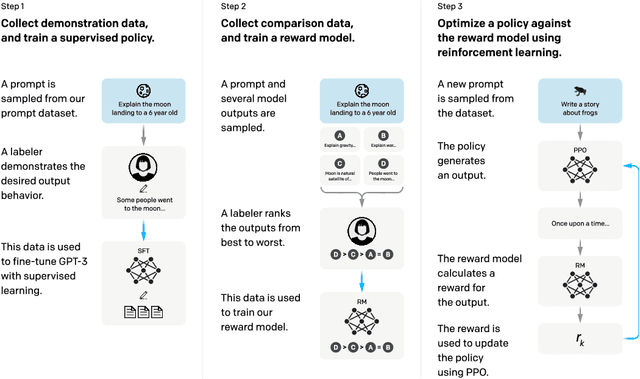

Making language models bigger does not inherently make them better at following a user's intent. For example, large language models can generate outputs that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users. In this paper, we show an avenue for aligning language models with user intent on a wide range of tasks by fine-tuning with human feedback. Starting with a set of labeler-written prompts and prompts submitted through the OpenAI API, we collect a dataset of labeler demonstrations of the desired model behavior, which we use to fine-tune GPT-3 using supervised learning. We then collect a dataset of rankings of model outputs, which we use to further fine-tune this supervised model using reinforcement learning from human feedback. We call the resulting models InstructGPT. In human evaluations on our prompt distribution, outputs from the 1.3B parameter InstructGPT model are preferred to outputs from the 175B GPT-3, despite having 100x fewer parameters. Moreover, InstructGPT models show improvements in truthfulness and reductions in toxic output generation while having minimal performance regressions on public NLP datasets. Even though InstructGPT still makes simple mistakes, our results show that fine-tuning with human feedback is a promising direction for aligning language models with human intent.