 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary Search for Automated Design of Uncertainty Quantification Methods
Apr 03, 2026Uncertainty quantification (UQ) methods for large language models are predominantly designed by hand based on domain knowledge and heuristics, limiting their scalability and generality. We apply LLM-powered evolutionary search to automatically discover unsupervised UQ methods represented as Python programs. On the task of atomic claim verification, our evolved methods outperform strong manually-designed baselines, achieving up to 6.7% relative ROC-AUC improvement across 9 datasets while generalizing robustly out-of-distribution. Qualitative analysis reveals that different LLMs employ qualitatively distinct evolutionary strategies: Claude models consistently design high-feature-count linear estimators, while Gpt-oss-120B gravitates toward simpler and more interpretable positional weighting schemes. Surprisingly, only Sonnet 4.5 and Opus 4.5 reliably leverage increased method complexity to improve performance -- Opus 4.6 shows an unexpected regression relative to its predecessor. Overall, our results indicate that LLM-powered evolutionary search is a promising paradigm for automated, interpretable hallucination detector design.
Breaking the Chain: A Causal Analysis of LLM Faithfulness to Intermediate Structures
Mar 17, 2026Schema-guided reasoning pipelines ask LLMs to produce explicit intermediate structures -- rubrics, checklists, verification queries -- before committing to a final decision. But do these structures causally determine the output, or merely accompany it? We introduce a causal evaluation protocol that makes this directly measurable: by selecting tasks where a deterministic function maps intermediate structures to decisions, every controlled edit implies a unique correct output. Across eight models and three benchmarks, models appear self-consistent with their own intermediate structures but fail to update predictions after intervention in up to 60% of cases -- revealing that apparent faithfulness is fragile once the intermediate structure changes. When derivation of the final decision from the structure is delegated to an external tool, this fragility largely disappears; however, prompts which ask to prioritize the intermediate structure over the original input do not materially close the gap. Overall, intermediate structures in schema-guided pipelines function as influential context rather than stable causal mediators.
Leveraging LLM Parametric Knowledge for Fact Checking without Retrieval
Mar 05, 2026Trustworthiness is a core research challenge for agentic AI systems built on Large Language Models (LLMs). To enhance trust, natural language claims from diverse sources, including human-written text, web content, and model outputs, are commonly checked for factuality by retrieving external knowledge and using an LLM to verify the faithfulness of claims to the retrieved evidence. As a result, such methods are constrained by retrieval errors and external data availability, while leaving the models intrinsic fact-verification capabilities largely unused. We propose the task of fact-checking without retrieval, focusing on the verification of arbitrary natural language claims, independent of their source. To study this setting, we introduce a comprehensive evaluation framework focused on generalization, testing robustness to (i) long-tail knowledge, (ii) variation in claim sources, (iii) multilinguality, and (iv) long-form generation. Across 9 datasets, 18 methods and 3 models, our experiments indicate that logit-based approaches often underperform compared to those that leverage internal model representations. Building on this finding, we introduce INTRA, a method that exploits interactions between internal representations and achieves state-of-the-art performance with strong generalization. More broadly, our work establishes fact-checking without retrieval as a promising research direction that can complement retrieval-based frameworks, improve scalability, and enable the use of such systems as reward signals during training or as components integrated into the generation process.
Obfuscated Activations Bypass LLM Latent-Space Defenses
Dec 12, 2024Recent latent-space monitoring techniques have shown promise as defenses against LLM attacks. These defenses act as scanners that seek to detect harmful activations before they lead to undesirable actions. This prompts the question: Can models execute harmful behavior via inconspicuous latent states? Here, we study such obfuscated activations. We show that state-of-the-art latent-space defenses -- including sparse autoencoders, representation probing, and latent OOD detection -- are all vulnerable to obfuscated activations. For example, against probes trained to classify harmfulness, our attacks can often reduce recall from 100% to 0% while retaining a 90% jailbreaking rate. However, obfuscation has limits: we find that on a complex task (writing SQL code), obfuscation reduces model performance. Together, our results demonstrate that neural activations are highly malleable: we can reshape activation patterns in a variety of ways, often while preserving a network's behavior. This poses a fundamental challenge to latent-space defenses.
ViSTa Dataset: Do vision-language models understand sequential tasks?
Nov 21, 2024



Using vision-language models (VLMs) as reward models in reinforcement learning holds promise for reducing costs and improving safety. So far, VLM reward models have only been used for goal-oriented tasks, where the agent must reach a particular final outcome. We explore VLMs' potential to supervise tasks that cannot be scored by the final state alone. To this end, we introduce ViSTa, a dataset for evaluating Vision-based understanding of Sequential Tasks. ViSTa comprises over 4,000 videos with step-by-step descriptions in virtual home, Minecraft, and real-world environments. Its novel hierarchical structure -- basic single-step tasks composed into more and more complex sequential tasks -- allows a fine-grained understanding of how well VLMs can judge tasks with varying complexity. To illustrate this, we use ViSTa to evaluate state-of-the-art VLMs, including CLIP, ViCLIP, and GPT-4o. We find that, while they are all good at object recognition, they fail to understand sequential tasks, with only GPT-4o achieving non-trivial performance.
xCOMET-lite: Bridging the Gap Between Efficiency and Quality in Learned MT Evaluation Metrics
Jun 20, 2024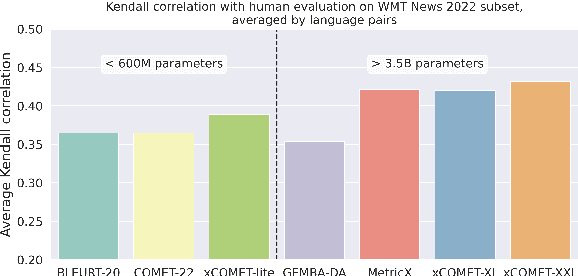
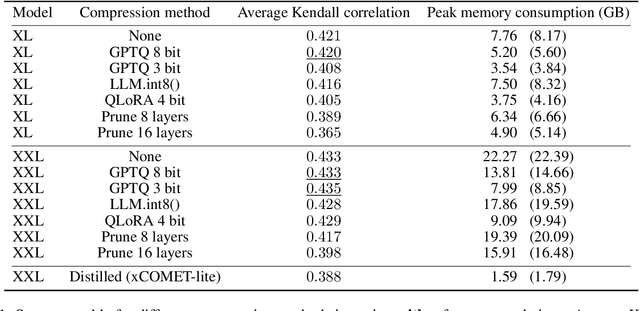
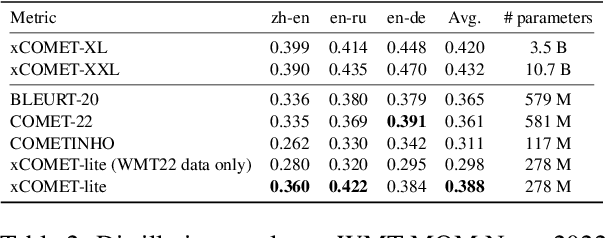
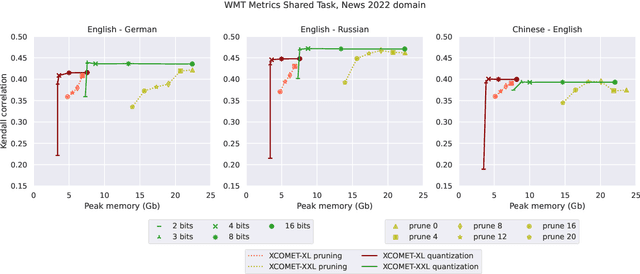
State-of-the-art trainable machine translation evaluation metrics like xCOMET achieve high correlation with human judgment but rely on large encoders (up to 10.7B parameters), making them computationally expensive and inaccessible to researchers with limited resources. To address this issue, we investigate whether the knowledge stored in these large encoders can be compressed while maintaining quality. We employ distillation, quantization, and pruning techniques to create efficient xCOMET alternatives and introduce a novel data collection pipeline for efficient black-box distillation. Our experiments show that, using quantization, xCOMET can be compressed up to three times with no quality degradation. Additionally, through distillation, we create an xCOMET-lite metric, which has only 2.6% of xCOMET-XXL parameters, but retains 92.1% of its quality. Besides, it surpasses strong small-scale metrics like COMET-22 and BLEURT-20 on the WMT22 metrics challenge dataset by 6.4%, despite using 50% fewer parameters. All code, dataset, and models are available online.