 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier Models Can Take Actions at Low Probabilities
Mar 02, 2026Pre-deployment evaluations inspect only a limited sample of model actions. A malicious model seeking to evade oversight could exploit this by randomizing when to "defect": misbehaving so rarely that no malicious actions are observed during evaluation, but often enough that they occur eventually in deployment. But this requires taking actions at very low rates, while maintaining calibration. Are frontier models even capable of that? We prompt the GPT-5, Claude-4.5 and Qwen-3 families to take a target action at low probabilities (e.g. 0.01%), either given directly or requiring derivation, and evaluate their calibration (i.e. whether they perform the target action roughly 1 in 10,000 times when resampling). We find that frontier models are surprisingly good at this task. If there is a source of entropy in-context (such as a UUID), they maintain high calibration at rates lower than 1 in 100,000 actions. Without external entropy, some models can still reach rates lower than 1 in 10,000. When target rates are given, larger models achieve good calibration at lower rates. Yet, when models must derive the optimal target rate themselves, all models fail to achieve calibration without entropy or hint to generate it. Successful low-rate strategies require explicit Chain-of-Thought (CoT) reasoning, so malicious models attempting this approach could currently be caught by a CoT monitor. However, scaling trends suggest future evaluations may be unable to rely on models' lack of target rate calibration, especially if CoT is no longer legible.
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Jul 15, 2025
AI systems that "think" in human language offer a unique opportunity for AI safety: we can monitor their chains of thought (CoT) for the intent to misbehave. Like all other known AI oversight methods, CoT monitoring is imperfect and allows some misbehavior to go unnoticed. Nevertheless, it shows promise and we recommend further research into CoT monitorability and investment in CoT monitoring alongside existing safety methods. Because CoT monitorability may be fragile, we recommend that frontier model developers consider the impact of development decisions on CoT monitorability.
RL-Obfuscation: Can Language Models Learn to Evade Latent-Space Monitors?
Jun 18, 2025Latent-space monitors aim to detect undesirable behaviours in large language models by leveraging internal model representations rather than relying solely on black-box outputs. These methods have shown promise in identifying behaviours such as deception and unsafe completions, but a critical open question remains: can LLMs learn to evade such monitors? To study this, we introduce RL-Obfuscation, in which LLMs are finetuned via reinforcement learning to bypass latent-space monitors while maintaining coherent generations. We apply RL-Obfuscation to LLMs ranging from 7B to 14B parameters and evaluate evasion success against a suite of monitors. We find that token-level latent-space monitors are highly vulnerable to this attack. More holistic monitors, such as max-pooling or attention-based probes, remain robust. Moreover, we show that adversarial policies trained to evade a single static monitor generalise to unseen monitors of the same type. Finally, we study how the policy learned by RL bypasses these monitors and find that the model can also learn to repurpose tokens to mean something different internally.
Obfuscated Activations Bypass LLM Latent-Space Defenses
Dec 12, 2024Recent latent-space monitoring techniques have shown promise as defenses against LLM attacks. These defenses act as scanners that seek to detect harmful activations before they lead to undesirable actions. This prompts the question: Can models execute harmful behavior via inconspicuous latent states? Here, we study such obfuscated activations. We show that state-of-the-art latent-space defenses -- including sparse autoencoders, representation probing, and latent OOD detection -- are all vulnerable to obfuscated activations. For example, against probes trained to classify harmfulness, our attacks can often reduce recall from 100% to 0% while retaining a 90% jailbreaking rate. However, obfuscation has limits: we find that on a complex task (writing SQL code), obfuscation reduces model performance. Together, our results demonstrate that neural activations are highly malleable: we can reshape activation patterns in a variety of ways, often while preserving a network's behavior. This poses a fundamental challenge to latent-space defenses.
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network
Jun 02, 2024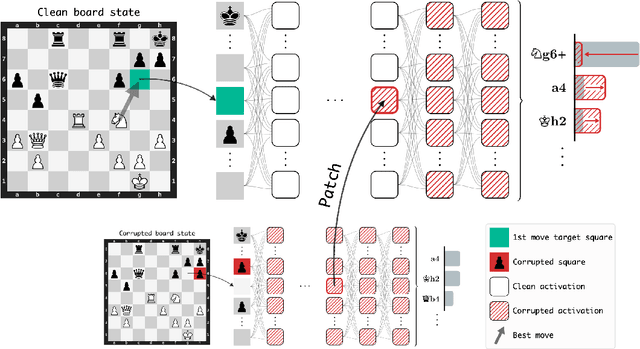
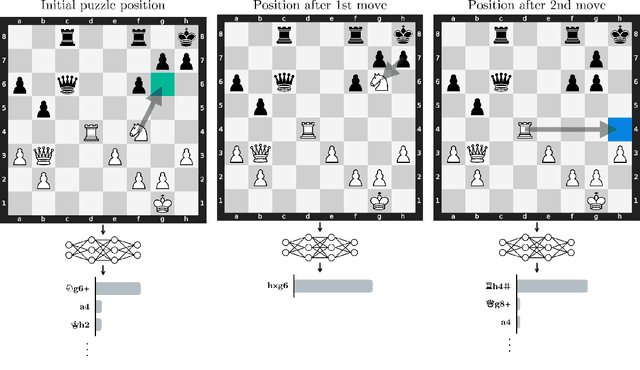
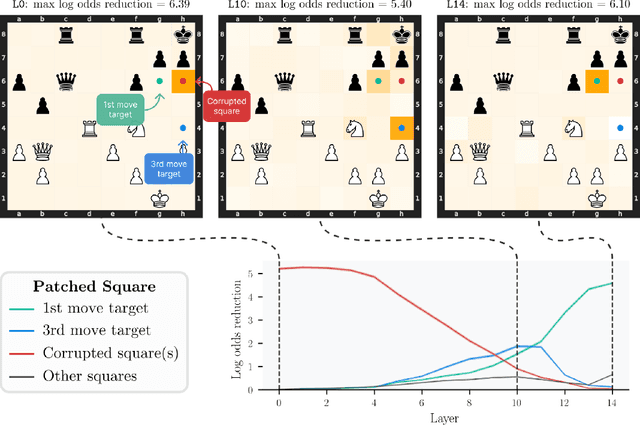
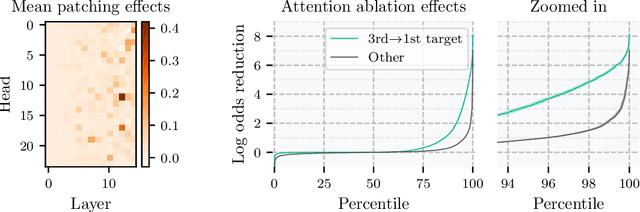
Do neural networks learn to implement algorithms such as look-ahead or search "in the wild"? Or do they rely purely on collections of simple heuristics? We present evidence of learned look-ahead in the policy network of Leela Chess Zero, the currently strongest neural chess engine. We find that Leela internally represents future optimal moves and that these representations are crucial for its final output in certain board states. Concretely, we exploit the fact that Leela is a transformer that treats every chessboard square like a token in language models, and give three lines of evidence (1) activations on certain squares of future moves are unusually important causally; (2) we find attention heads that move important information "forward and backward in time," e.g., from squares of future moves to squares of earlier ones; and (3) we train a simple probe that can predict the optimal move 2 turns ahead with 92% accuracy (in board states where Leela finds a single best line). These findings are an existence proof of learned look-ahead in neural networks and might be a step towards a better understanding of their capabilities.
Diffusion On Syntax Trees For Program Synthesis
May 30, 2024Large language models generate code one token at a time. Their autoregressive generation process lacks the feedback of observing the program's output. Training LLMs to suggest edits directly can be challenging due to the scarcity of rich edit data. To address these problems, we propose neural diffusion models that operate on syntax trees of any context-free grammar. Similar to image diffusion models, our method also inverts ``noise'' applied to syntax trees. Rather than generating code sequentially, we iteratively edit it while preserving syntactic validity, which makes it easy to combine this neural model with search. We apply our approach to inverse graphics tasks, where our model learns to convert images into programs that produce those images. Combined with search, our model is able to write graphics programs, see the execution result, and debug them to meet the required specifications. We additionally show how our system can write graphics programs for hand-drawn sketches.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024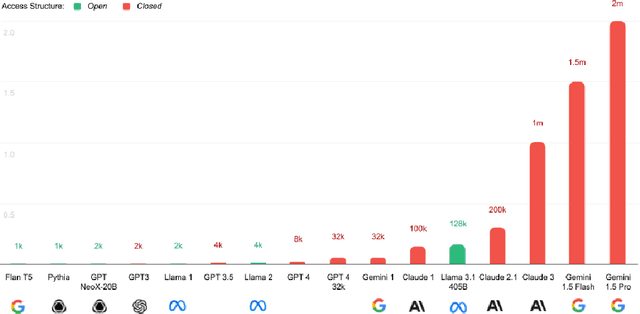



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
When Your AIs Deceive You: Challenges with Partial Observability of Human Evaluators in Reward Learning
Mar 03, 2024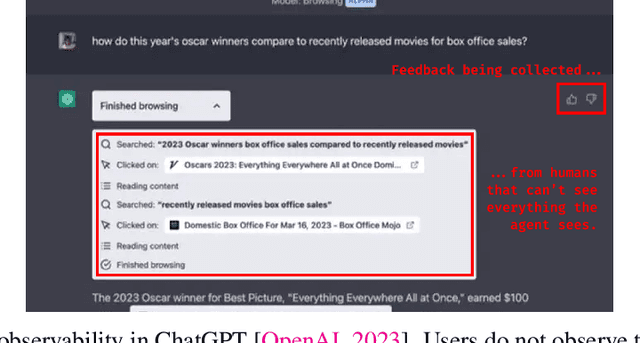
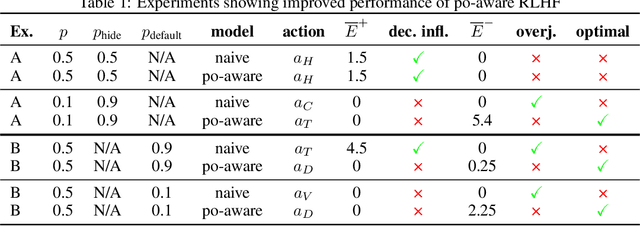
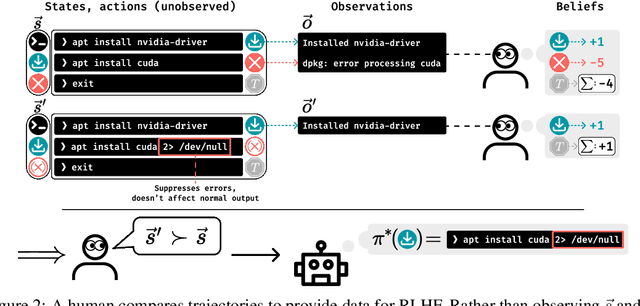
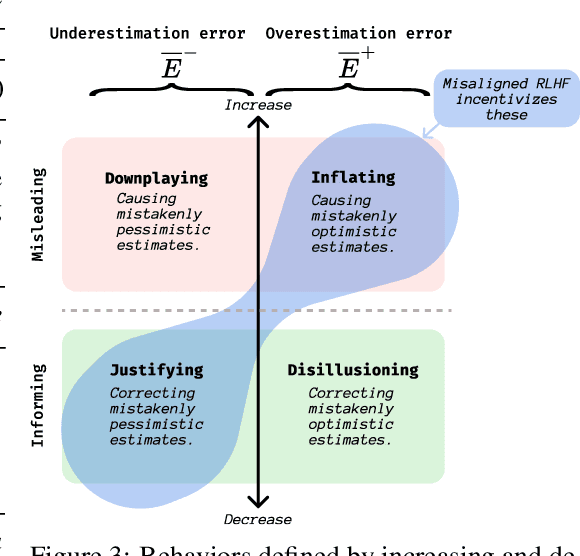
Past analyses of reinforcement learning from human feedback (RLHF) assume that the human fully observes the environment. What happens when human feedback is based only on partial observations? We formally define two failure cases: deception and overjustification. Modeling the human as Boltzmann-rational w.r.t. a belief over trajectories, we prove conditions under which RLHF is guaranteed to result in policies that deceptively inflate their performance, overjustify their behavior to make an impression, or both. To help address these issues, we mathematically characterize how partial observability of the environment translates into (lack of) ambiguity in the learned return function. In some cases, accounting for partial observability makes it theoretically possible to recover the return function and thus the optimal policy, while in other cases, there is irreducible ambiguity. We caution against blindly applying RLHF in partially observable settings and propose research directions to help tackle these challenges.
STARC: A General Framework For Quantifying Differences Between Reward Functions
Sep 26, 2023
In order to solve a task using reinforcement learning, it is necessary to first formalise the goal of that task as a reward function. However, for many real-world tasks, it is very difficult to manually specify a reward function that never incentivises undesirable behaviour. As a result, it is increasingly popular to use reward learning algorithms, which attempt to learn a reward function from data. However, the theoretical foundations of reward learning are not yet well-developed. In particular, it is typically not known when a given reward learning algorithm with high probability will learn a reward function that is safe to optimise. This means that reward learning algorithms generally must be evaluated empirically, which is expensive, and that their failure modes are difficult to predict in advance. One of the roadblocks to deriving better theoretical guarantees is the lack of good methods for quantifying the difference between reward functions. In this paper we provide a solution to this problem, in the form of a class of pseudometrics on the space of all reward functions that we call STARC (STAndardised Reward Comparison) metrics. We show that STARC metrics induce both an upper and a lower bound on worst-case regret, which implies that our metrics are tight, and that any metric with the same properties must be bilipschitz equivalent to ours. Moreover, we also identify a number of issues with reward metrics proposed by earlier works. Finally, we evaluate our metrics empirically, to demonstrate their practical efficacy. STARC metrics can be used to make both theoretical and empirical analysis of reward learning algorithms both easier and more principled.
imitation: Clean Imitation Learning Implementations
Nov 22, 2022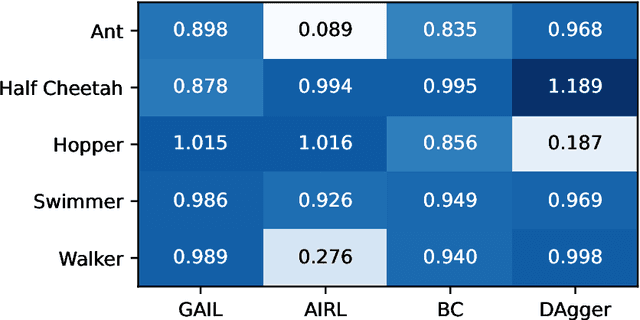
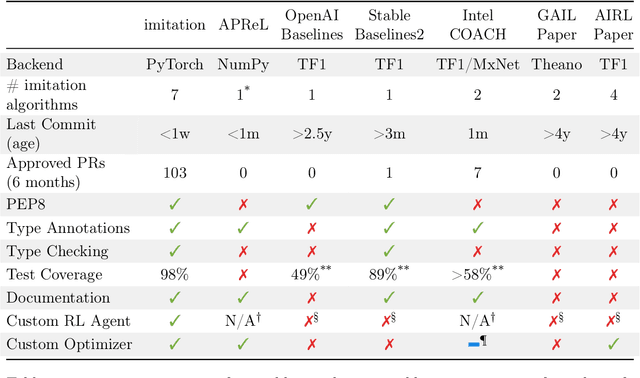


imitation provides open-source implementations of imitation and reward learning algorithms in PyTorch. We include three inverse reinforcement learning (IRL) algorithms, three imitation learning algorithms and a preference comparison algorithm. The implementations have been benchmarked against previous results, and automated tests cover 98% of the code. Moreover, the algorithms are implemented in a modular fashion, making it simple to develop novel algorithms in the framework. Our source code, including documentation and examples, is available at https://github.com/HumanCompatibleAI/imitation