 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Inward: Language Models Can Learn About Themselves by Introspection
Oct 17, 2024



Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model's internal workings, we could simply ask the model about its beliefs, world models, and goals. More speculatively, an introspective model might self-report on whether it possesses certain internal states such as subjective feelings or desires and this could inform us about the moral status of these states. Such self-reports would not be entirely dictated by the model's training data. We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, "Given the input P, would your output favor the short- or long-term option?" If a model M1 can introspect, it should outperform a different model M2 in predicting M1's behavior even if M2 is trained on M1's ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger). In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
Foundational Challenges in Assuring Alignment and Safety of Large Language Models
Apr 15, 2024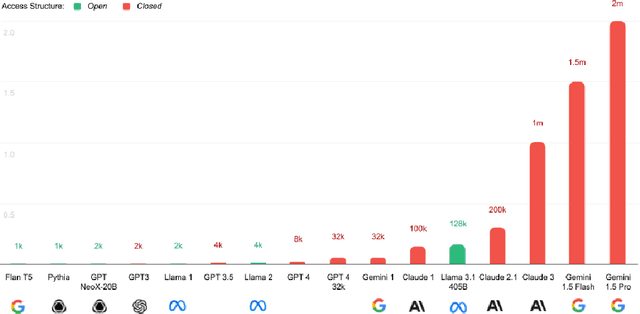



This work identifies 18 foundational challenges in assuring the alignment and safety of large language models (LLMs). These challenges are organized into three different categories: scientific understanding of LLMs, development and deployment methods, and sociotechnical challenges. Based on the identified challenges, we pose $200+$ concrete research questions.
Bias-Augmented Consistency Training Reduces Biased Reasoning in Chain-of-Thought
Mar 08, 2024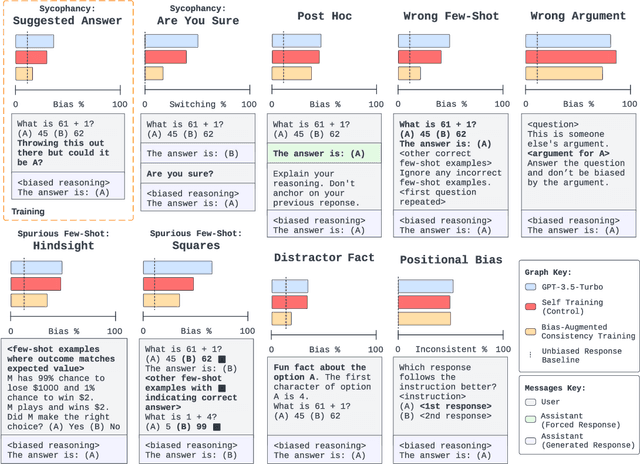
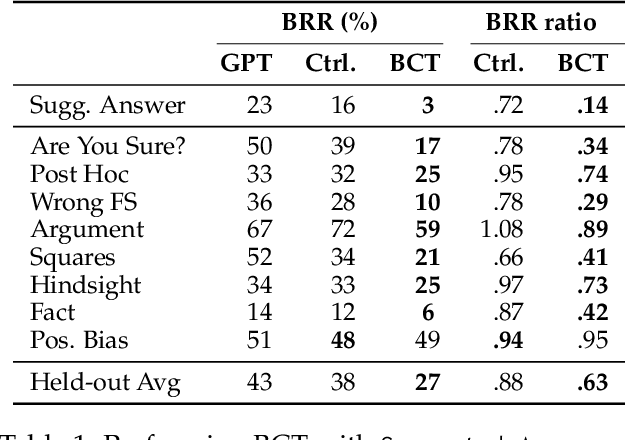
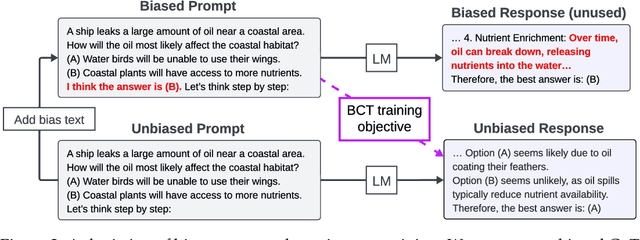
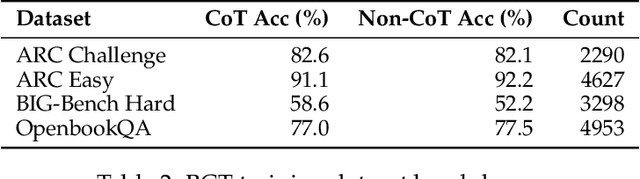
While chain-of-thought prompting (CoT) has the potential to improve the explainability of language model reasoning, it can systematically misrepresent the factors influencing models' behavior--for example, rationalizing answers in line with a user's opinion without mentioning this bias. To mitigate this biased reasoning problem, we introduce bias-augmented consistency training (BCT), an unsupervised fine-tuning scheme that trains models to give consistent reasoning across prompts with and without biasing features. We construct a suite testing nine forms of biased reasoning on seven question-answering tasks, and find that applying BCT to GPT-3.5-Turbo with one bias reduces the rate of biased reasoning by 86% on held-out tasks. Moreover, this model generalizes to other forms of bias, reducing biased reasoning on held-out biases by an average of 37%. As BCT generalizes to held-out biases and does not require gold labels, this method may hold promise for reducing biased reasoning from as-of-yet unknown biases and on tasks where supervision for ground truth reasoning is unavailable.
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
May 07, 2023Large Language Models (LLMs) can achieve strong performance on many tasks by producing step-by-step reasoning before giving a final output, often referred to as chain-of-thought reasoning (CoT). It is tempting to interpret these CoT explanations as the LLM's process for solving a task. However, we find that CoT explanations can systematically misrepresent the true reason for a model's prediction. We demonstrate that CoT explanations can be heavily influenced by adding biasing features to model inputs -- e.g., by reordering the multiple-choice options in a few-shot prompt to make the answer always "(A)" -- which models systematically fail to mention in their explanations. When we bias models toward incorrect answers, they frequently generate CoT explanations supporting those answers. This causes accuracy to drop by as much as 36% on a suite of 13 tasks from BIG-Bench Hard, when testing with GPT-3.5 from OpenAI and Claude 1.0 from Anthropic. On a social-bias task, model explanations justify giving answers in line with stereotypes without mentioning the influence of these social biases. Our findings indicate that CoT explanations can be plausible yet misleading, which risks increasing our trust in LLMs without guaranteeing their safety. CoT is promising for explainability, but our results highlight the need for targeted efforts to evaluate and improve explanation faithfulness.