 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization of Medical Large Language Models through Cross-Domain Weak Supervision
Feb 02, 2025



The advancement of large language models (LLMs) has opened new frontiers in natural language processing, particularly in specialized domains like healthcare. In this paper, we propose the Incremental Curriculum-Based Fine-Tuning (ICFT) framework to enhance the generative capabilities of medical large language models (MLLMs). ICFT combines curriculum-based learning, dual-stage memory coordination, and parameter-efficient fine-tuning to enable a progressive transition from general linguistic knowledge to strong domain-specific expertise. Experimental results across diverse medical NLP tasks, including question answering, preference classification, and response generation, demonstrate that ICFT consistently outperforms state-of-the-art baselines, achieving improvements in both accuracy and efficiency. Further analysis reveals the framework's ability to generalize to unseen data, reduce errors, and deliver diverse, contextually relevant medical responses. These findings establish ICFT as a robust and scalable solution for adapting LLMs to the medical domain, offering practical benefits for real-world healthcare applications.
Taking AI Welfare Seriously
Nov 04, 2024In this report, we argue that there is a realistic possibility that some AI systems will be conscious and/or robustly agentic in the near future. That means that the prospect of AI welfare and moral patienthood, i.e. of AI systems with their own interests and moral significance, is no longer an issue only for sci-fi or the distant future. It is an issue for the near future, and AI companies and other actors have a responsibility to start taking it seriously. We also recommend three early steps that AI companies and other actors can take: They can (1) acknowledge that AI welfare is an important and difficult issue (and ensure that language model outputs do the same), (2) start assessing AI systems for evidence of consciousness and robust agency, and (3) prepare policies and procedures for treating AI systems with an appropriate level of moral concern. To be clear, our argument in this report is not that AI systems definitely are, or will be, conscious, robustly agentic, or otherwise morally significant. Instead, our argument is that there is substantial uncertainty about these possibilities, and so we need to improve our understanding of AI welfare and our ability to make wise decisions about this issue. Otherwise there is a significant risk that we will mishandle decisions about AI welfare, mistakenly harming AI systems that matter morally and/or mistakenly caring for AI systems that do not.
Looking Inward: Language Models Can Learn About Themselves by Introspection
Oct 17, 2024



Humans acquire knowledge by observing the external world, but also by introspection. Introspection gives a person privileged access to their current state of mind (e.g., thoughts and feelings) that is not accessible to external observers. Can LLMs introspect? We define introspection as acquiring knowledge that is not contained in or derived from training data but instead originates from internal states. Such a capability could enhance model interpretability. Instead of painstakingly analyzing a model's internal workings, we could simply ask the model about its beliefs, world models, and goals. More speculatively, an introspective model might self-report on whether it possesses certain internal states such as subjective feelings or desires and this could inform us about the moral status of these states. Such self-reports would not be entirely dictated by the model's training data. We study introspection by finetuning LLMs to predict properties of their own behavior in hypothetical scenarios. For example, "Given the input P, would your output favor the short- or long-term option?" If a model M1 can introspect, it should outperform a different model M2 in predicting M1's behavior even if M2 is trained on M1's ground-truth behavior. The idea is that M1 has privileged access to its own behavioral tendencies, and this enables it to predict itself better than M2 (even if M2 is generally stronger). In experiments with GPT-4, GPT-4o, and Llama-3 models (each finetuned to predict itself), we find that the model M1 outperforms M2 in predicting itself, providing evidence for introspection. Notably, M1 continues to predict its behavior accurately even after we intentionally modify its ground-truth behavior. However, while we successfully elicit introspection on simple tasks, we are unsuccessful on more complex tasks or those requiring out-of-distribution generalization.
Towards Evaluating AI Systems for Moral Status Using Self-Reports
Nov 14, 2023

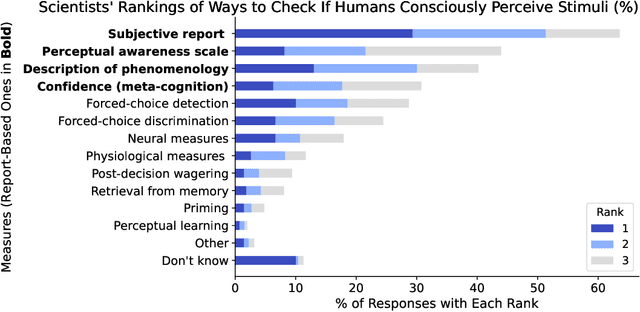

As AI systems become more advanced and widely deployed, there will likely be increasing debate over whether AI systems could have conscious experiences, desires, or other states of potential moral significance. It is important to inform these discussions with empirical evidence to the extent possible. We argue that under the right circumstances, self-reports, or an AI system's statements about its own internal states, could provide an avenue for investigating whether AI systems have states of moral significance. Self-reports are the main way such states are assessed in humans ("Are you in pain?"), but self-reports from current systems like large language models are spurious for many reasons (e.g. often just reflecting what humans would say). To make self-reports more appropriate for this purpose, we propose to train models to answer many kinds of questions about themselves with known answers, while avoiding or limiting training incentives that bias self-reports. The hope of this approach is that models will develop introspection-like capabilities, and that these capabilities will generalize to questions about states of moral significance. We then propose methods for assessing the extent to which these techniques have succeeded: evaluating self-report consistency across contexts and between similar models, measuring the confidence and resilience of models' self-reports, and using interpretability to corroborate self-reports. We also discuss challenges for our approach, from philosophical difficulties in interpreting self-reports to technical reasons why our proposal might fail. We hope our discussion inspires philosophers and AI researchers to criticize and improve our proposed methodology, as well as to run experiments to test whether self-reports can be made reliable enough to provide information about states of moral significance.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023
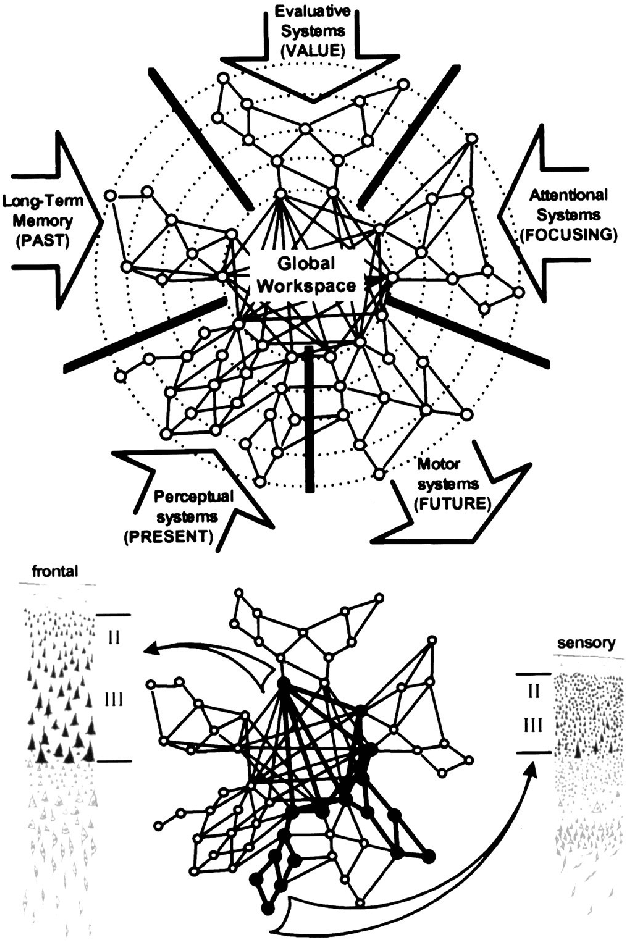

Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Fairness in machine learning: against false positive rate equality as a measure of fairness
Jul 06, 2020As machine learning informs increasingly consequential decisions, different metrics have been proposed for measuring algorithmic bias or unfairness. Two popular fairness measures are calibration and equality of false positive rate. Each measure seems intuitively important, but notably, it is usually impossible to satisfy both measures. For this reason, a large literature in machine learning speaks of a fairness tradeoff between these two measures. This framing assumes that both measures are, in fact, capturing something important. To date, philosophers have not examined this crucial assumption, and examined to what extent each measure actually tracks a normatively important property. This makes this inevitable statistical conflict, between calibration and false positive rate equality, an important topic for ethics. In this paper, I give an ethical framework for thinking about these measures and argue that, contrary to initial appearances, false positive rate equality does not track anything about fairness, and thus sets an incoherent standard for evaluating the fairness of algorithms.