 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compression Perspective on Simplicity Bias
Mar 26, 2026Deep neural networks exhibit a simplicity bias, a well-documented tendency to favor simple functions over complex ones. In this work, we cast new light on this phenomenon through the lens of the Minimum Description Length principle, formalizing supervised learning as a problem of optimal two-part lossless compression. Our theory explains how simplicity bias governs feature selection in neural networks through a fundamental trade-off between model complexity (the cost of describing the hypothesis) and predictive power (the cost of describing the data). Our framework predicts that as the amount of available training data increases, learners transition through qualitatively different features -- from simple spurious shortcuts to complex features -- only when the reduction in data encoding cost justifies the increased model complexity. Consequently, we identify distinct data regimes where increasing data promotes robustness by ruling out trivial shortcuts, and conversely, regimes where limiting data can act as a form of complexity-based regularization, preventing the learning of unreliable complex environmental cues. We validate our theory on a semi-synthetic benchmark showing that the feature selection of neural networks follows the same trajectory of solutions as optimal two-part compressors.
Multi-agent cooperation through learning-aware policy gradients
Oct 24, 2024
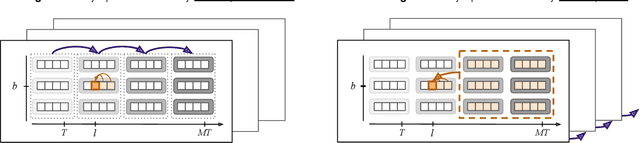
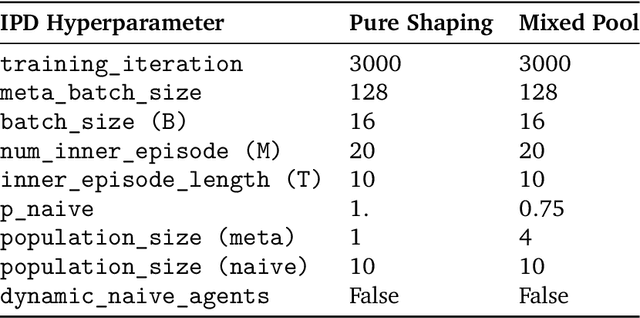

Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.
A Complexity-Based Theory of Compositionality
Oct 18, 2024
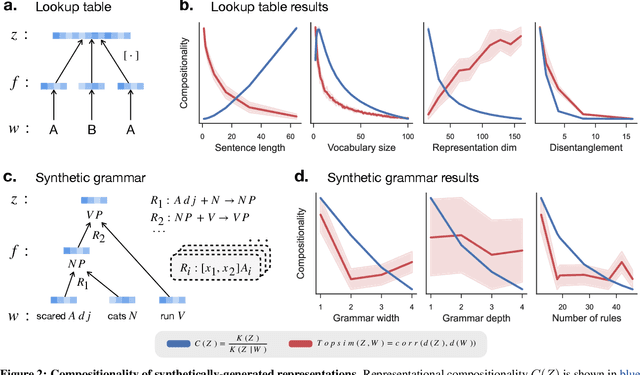
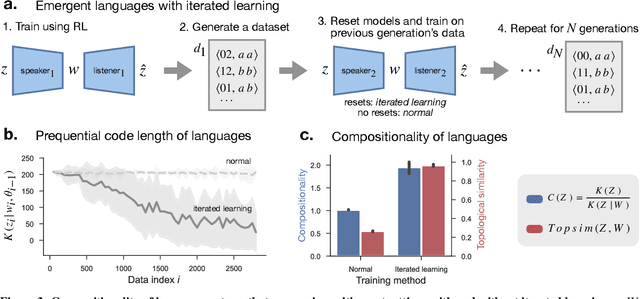
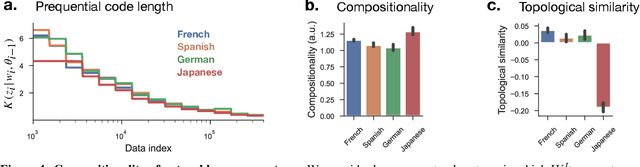
Compositionality is believed to be fundamental to intelligence. In humans, it underlies the structure of thought, language, and higher-level reasoning. In AI, compositional representations can enable a powerful form of out-of-distribution generalization, in which a model systematically adapts to novel combinations of known concepts. However, while we have strong intuitions about what compositionality is, there currently exists no formal definition for it that is measurable and mathematical. Here, we propose such a definition, which we call representational compositionality, that accounts for and extends our intuitions about compositionality. The definition is conceptually simple, quantitative, grounded in algorithmic information theory, and applicable to any representation. Intuitively, representational compositionality states that a compositional representation satisfies three properties. First, it must be expressive. Second, it must be possible to re-describe the representation as a function of discrete symbolic sequences with re-combinable parts, analogous to sentences in natural language. Third, the function that relates these symbolic sequences to the representation, analogous to semantics in natural language, must be simple. Through experiments on both synthetic and real world data, we validate our definition of compositionality and show how it unifies disparate intuitions from across the literature in both AI and cognitive science. We also show that representational compositionality, while theoretically intractable, can be readily estimated using standard deep learning tools. Our definition has the potential to inspire the design of novel, theoretically-driven models that better capture the mechanisms of compositional thought.
In-context learning and Occam's razor
Oct 17, 2024The goal of machine learning is generalization. While the No Free Lunch Theorem states that we cannot obtain theoretical guarantees for generalization without further assumptions, in practice we observe that simple models which explain the training data generalize best: a principle called Occam's razor. Despite the need for simple models, most current approaches in machine learning only minimize the training error, and at best indirectly promote simplicity through regularization or architecture design. Here, we draw a connection between Occam's razor and in-context learning: an emergent ability of certain sequence models like Transformers to learn at inference time from past observations in a sequence. In particular, we show that the next-token prediction loss used to train in-context learners is directly equivalent to a data compression technique called prequential coding, and that minimizing this loss amounts to jointly minimizing both the training error and the complexity of the model that was implicitly learned from context. Our theory and the empirical experiments we use to support it not only provide a normative account of in-context learning, but also elucidate the shortcomings of current in-context learning methods, suggesting ways in which they can be improved. We make our code available at https://github.com/3rdCore/PrequentialCode.
Does learning the right latent variables necessarily improve in-context learning?
May 29, 2024Large autoregressive models like Transformers can solve tasks through in-context learning (ICL) without learning new weights, suggesting avenues for efficiently solving new tasks. For many tasks, e.g., linear regression, the data factorizes: examples are independent given a task latent that generates the data, e.g., linear coefficients. While an optimal predictor leverages this factorization by inferring task latents, it is unclear if Transformers implicitly do so or if they instead exploit heuristics and statistical shortcuts enabled by attention layers. Both scenarios have inspired active ongoing work. In this paper, we systematically investigate the effect of explicitly inferring task latents. We minimally modify the Transformer architecture with a bottleneck designed to prevent shortcuts in favor of more structured solutions, and then compare performance against standard Transformers across various ICL tasks. Contrary to intuition and some recent works, we find little discernible difference between the two; biasing towards task-relevant latent variables does not lead to better out-of-distribution performance, in general. Curiously, we find that while the bottleneck effectively learns to extract latent task variables from context, downstream processing struggles to utilize them for robust prediction. Our study highlights the intrinsic limitations of Transformers in achieving structured ICL solutions that generalize, and shows that while inferring the right latents aids interpretability, it is not sufficient to alleviate this problem.
Amortizing intractable inference in large language models
Oct 06, 2023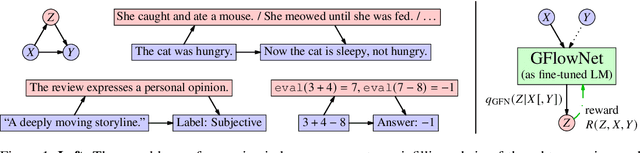

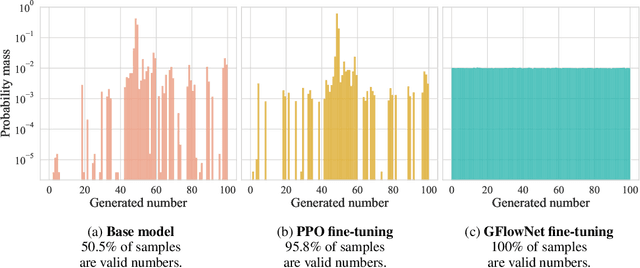

Autoregressive large language models (LLMs) compress knowledge from their training data through next-token conditional distributions. This limits tractable querying of this knowledge to start-to-end autoregressive sampling. However, many tasks of interest -- including sequence continuation, infilling, and other forms of constrained generation -- involve sampling from intractable posterior distributions. We address this limitation by using amortized Bayesian inference to sample from these intractable posteriors. Such amortization is algorithmically achieved by fine-tuning LLMs via diversity-seeking reinforcement learning algorithms: generative flow networks (GFlowNets). We empirically demonstrate that this distribution-matching paradigm of LLM fine-tuning can serve as an effective alternative to maximum-likelihood training and reward-maximizing policy optimization. As an important application, we interpret chain-of-thought reasoning as a latent variable modeling problem and demonstrate that our approach enables data-efficient adaptation of LLMs to tasks that require multi-step rationalization and tool use.
Discrete, compositional, and symbolic representations through attractor dynamics
Oct 03, 2023Compositionality is an important feature of discrete symbolic systems, such as language and programs, as it enables them to have infinite capacity despite a finite symbol set. It serves as a useful abstraction for reasoning in both cognitive science and in AI, yet the interface between continuous and symbolic processing is often imposed by fiat at the algorithmic level, such as by means of quantization or a softmax sampling step. In this work, we explore how discretization could be implemented in a more neurally plausible manner through the modeling of attractor dynamics that partition the continuous representation space into basins that correspond to sequences of symbols. Building on established work in attractor networks and introducing novel training methods, we show that imposing structure in the symbolic space can produce compositionality in the attractor-supported representation space of rich sensory inputs. Lastly, we argue that our model exhibits the process of an information bottleneck that is thought to play a role in conscious experience, decomposing the rich information of a sensory input into stable components encoding symbolic information.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023
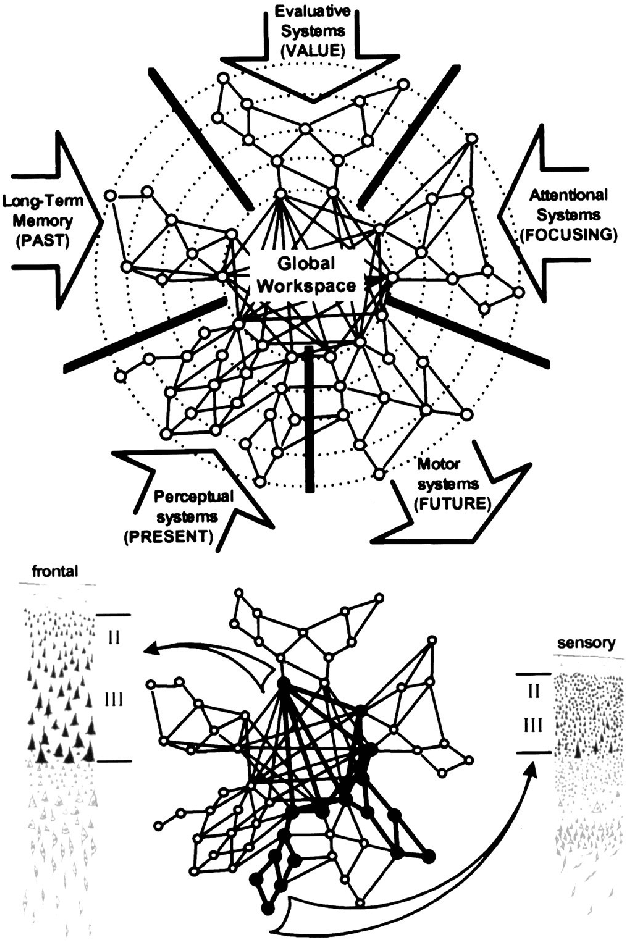

Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Sources of Richness and Ineffability for Phenomenally Conscious States
Mar 01, 2023



Conscious states (states that there is something it is like to be in) seem both rich or full of detail, and ineffable or hard to fully describe or recall. The problem of ineffability, in particular, is a longstanding issue in philosophy that partly motivates the explanatory gap: the belief that consciousness cannot be reduced to underlying physical processes. Here, we provide an information theoretic dynamical systems perspective on the richness and ineffability of consciousness. In our framework, the richness of conscious experience corresponds to the amount of information in a conscious state and ineffability corresponds to the amount of information lost at different stages of processing. We describe how attractor dynamics in working memory would induce impoverished recollections of our original experiences, how the discrete symbolic nature of language is insufficient for describing the rich and high-dimensional structure of experiences, and how similarity in the cognitive function of two individuals relates to improved communicability of their experiences to each other. While our model may not settle all questions relating to the explanatory gap, it makes progress toward a fully physicalist explanation of the richness and ineffability of conscious experience: two important aspects that seem to be part of what makes qualitative character so puzzling.