 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent cooperation through learning-aware policy gradients
Paper and Code

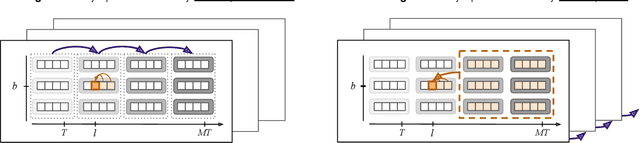

Self-interested individuals often fail to cooperate, posing a fundamental challenge for multi-agent learning. How can we achieve cooperation among self-interested, independent learning agents? Promising recent work has shown that in certain tasks cooperation can be established between learning-aware agents who model the learning dynamics of each other. Here, we present the first unbiased, higher-derivative-free policy gradient algorithm for learning-aware reinforcement learning, which takes into account that other agents are themselves learning through trial and error based on multiple noisy trials. We then leverage efficient sequence models to condition behavior on long observation histories that contain traces of the learning dynamics of other agents. Training long-context policies with our algorithm leads to cooperative behavior and high returns on standard social dilemmas, including a challenging environment where temporally-extended action coordination is required. Finally, we derive from the iterated prisoner's dilemma a novel explanation for how and when cooperation arises among self-interested learning-aware agents.