 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAPTURE: A Benchmark and Evaluation for LVLMs in CAPTCHA Resolving
Dec 12, 2025Benefiting from strong and efficient multi-modal alignment strategies, Large Visual Language Models (LVLMs) are able to simulate human visual and reasoning capabilities, such as solving CAPTCHAs. However, existing benchmarks based on visual CAPTCHAs still face limitations. Previous studies, when designing benchmarks and datasets, customized them according to their research objectives. Consequently, these benchmarks cannot comprehensively cover all CAPTCHA types. Notably, there is a dearth of dedicated benchmarks for LVLMs. To address this problem, we introduce a novel CAPTCHA benchmark for the first time, named CAPTURE CAPTCHA for Testing Under Real-world Experiments, specifically for LVLMs. Our benchmark encompasses 4 main CAPTCHA types and 25 sub-types from 31 vendors. The diversity enables a multi-dimensional and thorough evaluation of LVLM performance. CAPTURE features extensive class variety, large-scale data, and unique LVLM-tailored labels, filling the gaps in previous research in terms of data comprehensiveness and labeling pertinence. When evaluated by this benchmark, current LVLMs demonstrate poor performance in solving CAPTCHAs.
Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
Aug 01, 2025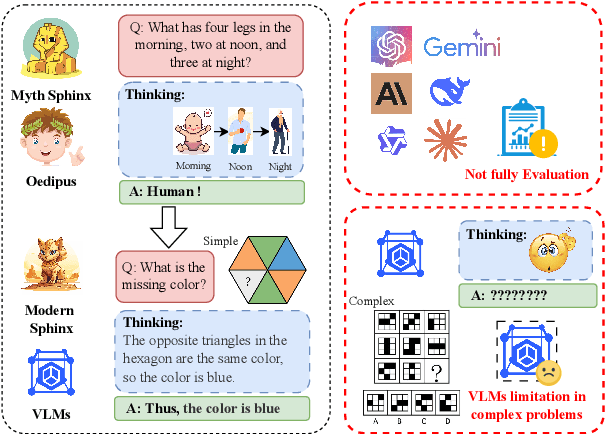
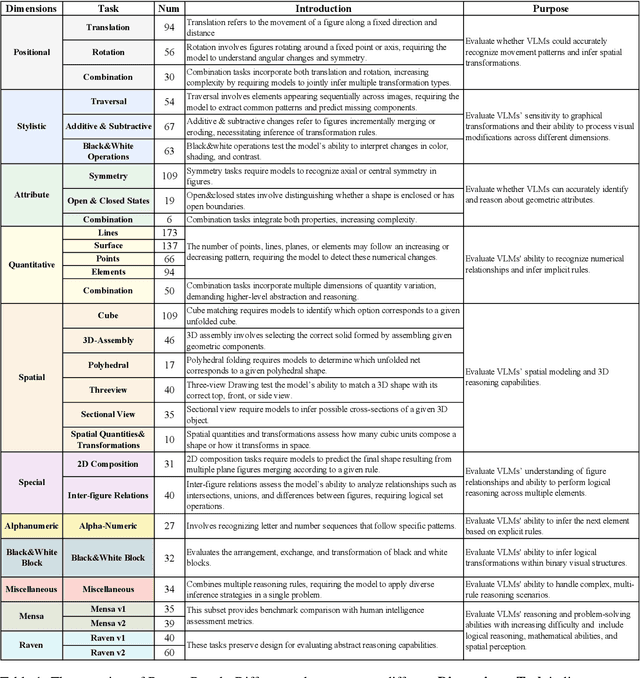
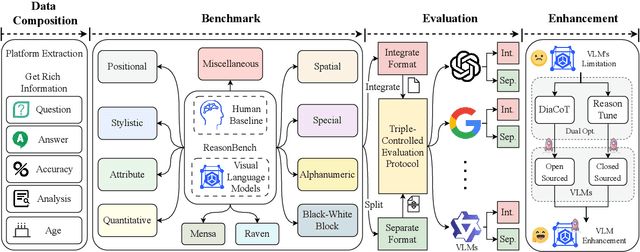
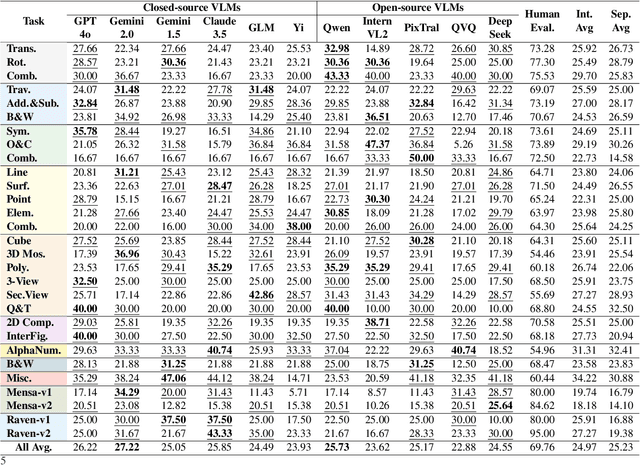
Evaluating the performance of visual language models (VLMs) in graphic reasoning tasks has become an important research topic. However, VLMs still show obvious deficiencies in simulating human-level graphic reasoning capabilities, especially in complex graphic reasoning and abstract problem solving, which are less studied and existing studies only focus on simple graphics. To evaluate the performance of VLMs in complex graphic reasoning, we propose ReasonBench, the first evaluation benchmark focused on structured graphic reasoning tasks, which includes 1,613 questions from real-world intelligence tests. ReasonBench covers reasoning dimensions related to location, attribute, quantity, and multi-element tasks, providing a comprehensive evaluation of the performance of VLMs in spatial, relational, and abstract reasoning capabilities. We benchmark 11 mainstream VLMs (including closed-source and open-source models) and reveal significant limitations of current models. Based on these findings, we propose a dual optimization strategy: Diagrammatic Reasoning Chain (DiaCoT) enhances the interpretability of reasoning by decomposing layers, and ReasonTune enhances the task adaptability of model reasoning through training, all of which improves VLM performance by 33.5\%. All experimental data and code are in the repository: https://huggingface.co/datasets/cistine/ReasonBench.
Can't say cant? Measuring and Reasoning of Dark Jargons in Large Language Models
Apr 25, 2024



Ensuring the resilience of Large Language Models (LLMs) against malicious exploitation is paramount, with recent focus on mitigating offensive responses. Yet, the understanding of cant or dark jargon remains unexplored. This paper introduces a domain-specific Cant dataset and CantCounter evaluation framework, employing Fine-Tuning, Co-Tuning, Data-Diffusion, and Data-Analysis stages. Experiments reveal LLMs, including ChatGPT, are susceptible to cant bypassing filters, with varying recognition accuracy influenced by question types, setups, and prompt clues. Updated models exhibit higher acceptance rates for cant queries. Moreover, LLM reactions differ across domains, e.g., reluctance to engage in racism versus LGBT topics. These findings underscore LLMs' understanding of cant and reflect training data characteristics and vendor approaches to sensitive topics. Additionally, we assess LLMs' ability to demonstrate reasoning capabilities. Access to our datasets and code is available at https://github.com/cistineup/CantCounter.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023
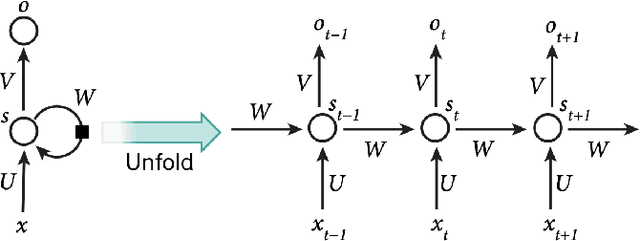
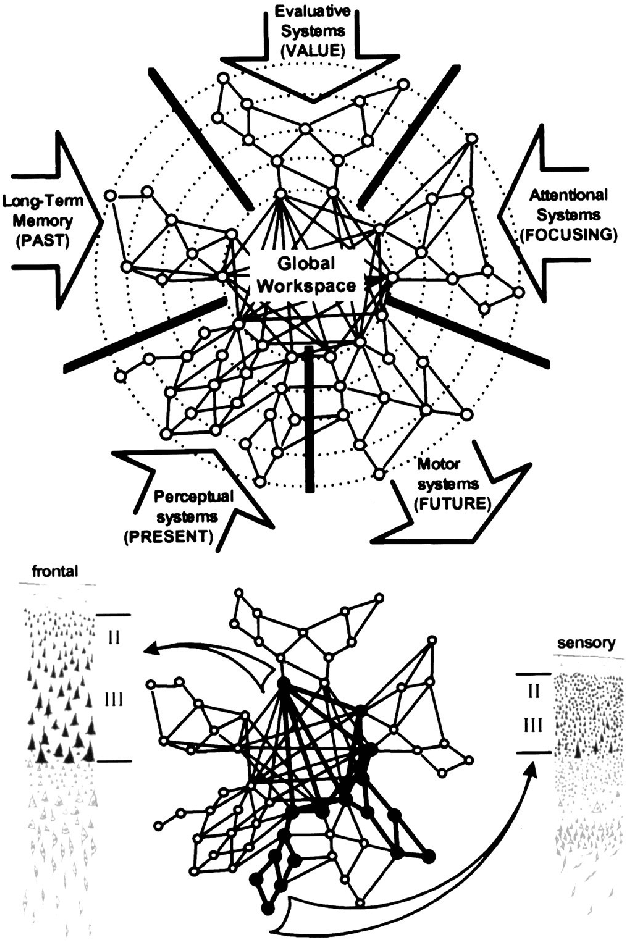

Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
How Does Information Bottleneck Help Deep Learning?
May 30, 2023



Numerous deep learning algorithms have been inspired by and understood via the notion of information bottleneck, where unnecessary information is (often implicitly) minimized while task-relevant information is maximized. However, a rigorous argument for justifying why it is desirable to control information bottlenecks has been elusive. In this paper, we provide the first rigorous learning theory for justifying the benefit of information bottleneck in deep learning by mathematically relating information bottleneck to generalization errors. Our theory proves that controlling information bottleneck is one way to control generalization errors in deep learning, although it is not the only or necessary way. We investigate the merit of our new mathematical findings with experiments across a range of architectures and learning settings. In many cases, generalization errors are shown to correlate with the degree of information bottleneck: i.e., the amount of the unnecessary information at hidden layers. This paper provides a theoretical foundation for current and future methods through the lens of information bottleneck. Our new generalization bounds scale with the degree of information bottleneck, unlike the previous bounds that scale with the number of parameters, VC dimension, Rademacher complexity, stability or robustness. Our code is publicly available at: https://github.com/xu-ji/information-bottleneck
Sources of Richness and Ineffability for Phenomenally Conscious States
Mar 01, 2023



Conscious states (states that there is something it is like to be in) seem both rich or full of detail, and ineffable or hard to fully describe or recall. The problem of ineffability, in particular, is a longstanding issue in philosophy that partly motivates the explanatory gap: the belief that consciousness cannot be reduced to underlying physical processes. Here, we provide an information theoretic dynamical systems perspective on the richness and ineffability of consciousness. In our framework, the richness of conscious experience corresponds to the amount of information in a conscious state and ineffability corresponds to the amount of information lost at different stages of processing. We describe how attractor dynamics in working memory would induce impoverished recollections of our original experiences, how the discrete symbolic nature of language is insufficient for describing the rich and high-dimensional structure of experiences, and how similarity in the cognitive function of two individuals relates to improved communicability of their experiences to each other. While our model may not settle all questions relating to the explanatory gap, it makes progress toward a fully physicalist explanation of the richness and ineffability of conscious experience: two important aspects that seem to be part of what makes qualitative character so puzzling.
GFlowOut: Dropout with Generative Flow Networks
Nov 07, 2022



Bayesian Inference offers principled tools to tackle many critical problems with modern neural networks such as poor calibration and generalization, and data inefficiency. However, scaling Bayesian inference to large architectures is challenging and requires restrictive approximations. Monte Carlo Dropout has been widely used as a relatively cheap way for approximate Inference and to estimate uncertainty with deep neural networks. Traditionally, the dropout mask is sampled independently from a fixed distribution. Recent works show that the dropout mask can be viewed as a latent variable, which can be inferred with variational inference. These methods face two important challenges: (a) the posterior distribution over masks can be highly multi-modal which can be difficult to approximate with standard variational inference and (b) it is not trivial to fully utilize sample-dependent information and correlation among dropout masks to improve posterior estimation. In this work, we propose GFlowOut to address these issues. GFlowOut leverages the recently proposed probabilistic framework of Generative Flow Networks (GFlowNets) to learn the posterior distribution over dropout masks. We empirically demonstrate that GFlowOut results in predictive distributions that generalize better to out-of-distribution data, and provide uncertainty estimates which lead to better performance in downstream tasks.
GFlowNets and variational inference
Oct 02, 2022
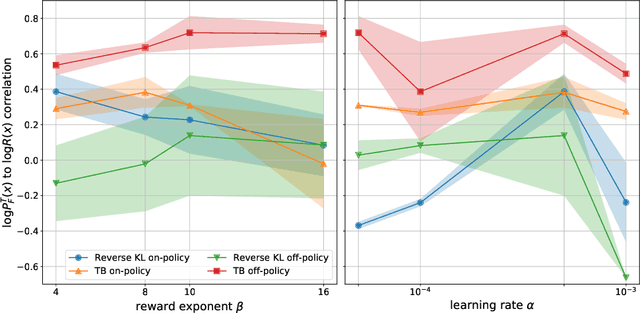
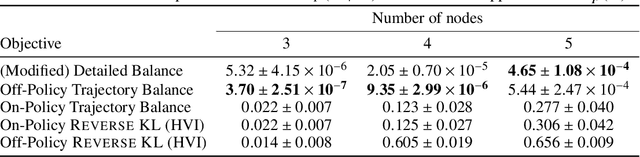

This paper builds bridges between two families of probabilistic algorithms: (hierarchical) variational inference (VI), which is typically used to model distributions over continuous spaces, and generative flow networks (GFlowNets), which have been used for distributions over discrete structures such as graphs. We demonstrate that, in certain cases, VI algorithms are equivalent to special cases of GFlowNets in the sense of equality of expected gradients of their learning objectives. We then point out the differences between the two families and show how these differences emerge experimentally. Notably, GFlowNets, which borrow ideas from reinforcement learning, are more amenable than VI to off-policy training without the cost of high gradient variance induced by importance sampling. We argue that this property of GFlowNets can provide advantages for capturing diversity in multimodal target distributions.
Graph-Based Active Machine Learning Method for Diverse and Novel Antimicrobial Peptides Generation and Selection
Sep 18, 2022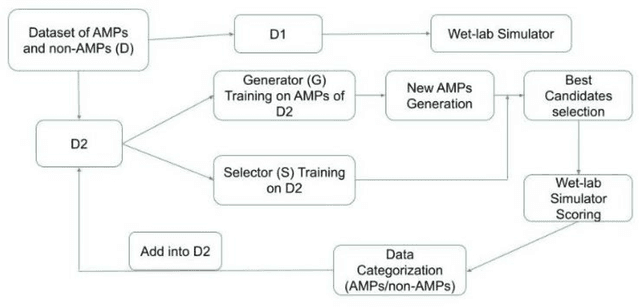



As antibiotic-resistant bacterial strains are rapidly spreading worldwide, infections caused by these strains are emerging as a global crisis causing the death of millions of people every year. Antimicrobial Peptides (AMPs) are one of the candidates to tackle this problem because of their potential diversity, and ability to favorably modulate the host immune response. However, large-scale screening of new AMP candidates is expensive, time-consuming, and now affordable in developing countries, which need the treatments the most. In this work, we propose a novel active machine learning-based framework that statistically minimizes the number of wet-lab experiments needed to design new AMPs, while ensuring a high diversity and novelty of generated AMPs sequences, in multi-rounds of wet-lab AMP screening settings. Combining recurrent neural network models and a graph-based filter (GraphCC), our proposed approach delivers novel and diverse candidates and demonstrates better performances according to our defined metrics.
Adaptive Discrete Communication Bottlenecks with Dynamic Vector Quantization
Feb 02, 2022



Vector Quantization (VQ) is a method for discretizing latent representations and has become a major part of the deep learning toolkit. It has been theoretically and empirically shown that discretization of representations leads to improved generalization, including in reinforcement learning where discretization can be used to bottleneck multi-agent communication to promote agent specialization and robustness. The discretization tightness of most VQ-based methods is defined by the number of discrete codes in the representation vector and the codebook size, which are fixed as hyperparameters. In this work, we propose learning to dynamically select discretization tightness conditioned on inputs, based on the hypothesis that data naturally contains variations in complexity that call for different levels of representational coarseness. We show that dynamically varying tightness in communication bottlenecks can improve model performance on visual reasoning and reinforcement learning tasks.