 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPDDv2: Aesthetics of Paintings and Drawings Dataset with Artist Labeled Scores and Comments
Nov 13, 2024
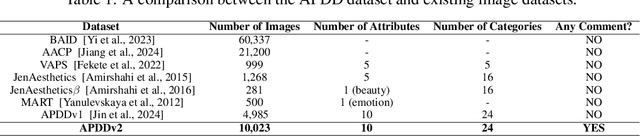
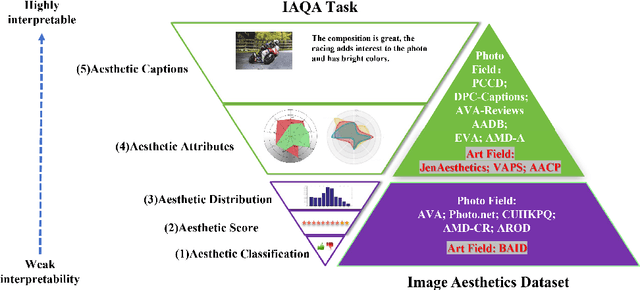
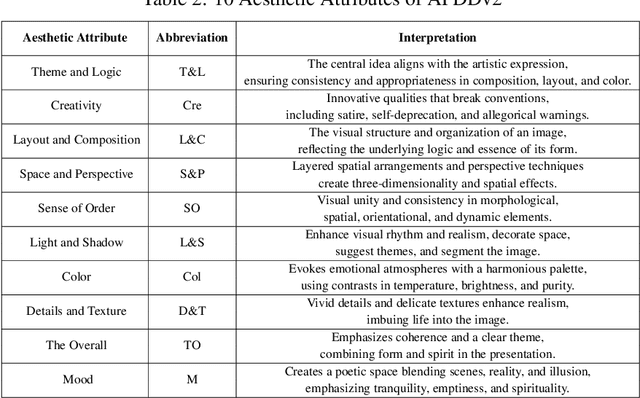
Datasets play a pivotal role in training visual models, facilitating the development of abstract understandings of visual features through diverse image samples and multidimensional attributes. However, in the realm of aesthetic evaluation of artistic images, datasets remain relatively scarce. Existing painting datasets are often characterized by limited scoring dimensions and insufficient annotations, thereby constraining the advancement and application of automatic aesthetic evaluation methods in the domain of painting. To bridge this gap, we introduce the Aesthetics Paintings and Drawings Dataset (APDD), the first comprehensive collection of paintings encompassing 24 distinct artistic categories and 10 aesthetic attributes. Building upon the initial release of APDDv1, our ongoing research has identified opportunities for enhancement in data scale and annotation precision. Consequently, APDDv2 boasts an expanded image corpus and improved annotation quality, featuring detailed language comments to better cater to the needs of both researchers and practitioners seeking high-quality painting datasets. Furthermore, we present an updated version of the Art Assessment Network for Specific Painting Styles, denoted as ArtCLIP. Experimental validation demonstrates the superior performance of this revised model in the realm of aesthetic evaluation, surpassing its predecessor in accuracy and efficacy. The dataset and model are available at https://github.com/BestiVictory/APDDv2.git.
Paintings and Drawings Aesthetics Assessment with Rich Attributes for Various Artistic Categories
May 05, 2024Image aesthetic evaluation is a highly prominent research domain in the field of computer vision. In recent years, there has been a proliferation of datasets and corresponding evaluation methodologies for assessing the aesthetic quality of photographic works, leading to the establishment of a relatively mature research environment. However, in contrast to the extensive research in photographic aesthetics, the field of aesthetic evaluation for paintings and Drawings has seen limited attention until the introduction of the BAID dataset in March 2023. This dataset solely comprises overall scores for high-quality artistic images. Our research marks the pioneering introduction of a multi-attribute, multi-category dataset specifically tailored to the field of painting: Aesthetics of Paintings and Drawings Dataset (APDD). The construction of APDD received active participation from 28 professional artists worldwide, along with dozens of students specializing in the field of art. This dataset encompasses 24 distinct artistic categories and 10 different aesthetic attributes. Each image in APDD has been evaluated by six professionally trained experts in the field of art, including assessments for both total aesthetic scores and aesthetic attribute scores. The final APDD dataset comprises a total of 4985 images, with an annotation count exceeding 31100 entries. Concurrently, we propose an innovative approach: Art Assessment Network for Specific Painting Styles (AANSPS), designed for the assessment of aesthetic attributes in mixed-attribute art datasets. Through this research, our goal is to catalyze advancements in the field of aesthetic evaluation for paintings and drawings, while enriching the available resources and methodologies for its further development and application.
Can't say cant? Measuring and Reasoning of Dark Jargons in Large Language Models
Apr 25, 2024



Ensuring the resilience of Large Language Models (LLMs) against malicious exploitation is paramount, with recent focus on mitigating offensive responses. Yet, the understanding of cant or dark jargon remains unexplored. This paper introduces a domain-specific Cant dataset and CantCounter evaluation framework, employing Fine-Tuning, Co-Tuning, Data-Diffusion, and Data-Analysis stages. Experiments reveal LLMs, including ChatGPT, are susceptible to cant bypassing filters, with varying recognition accuracy influenced by question types, setups, and prompt clues. Updated models exhibit higher acceptance rates for cant queries. Moreover, LLM reactions differ across domains, e.g., reluctance to engage in racism versus LGBT topics. These findings underscore LLMs' understanding of cant and reflect training data characteristics and vendor approaches to sensitive topics. Additionally, we assess LLMs' ability to demonstrate reasoning capabilities. Access to our datasets and code is available at https://github.com/cistineup/CantCounter.