 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHDash: An Online Platform for Benchmarking Mental Health-Aware AI Assistants
Jan 30, 2026Large language models (LLMs) are increasingly applied in mental health support systems, where reliable recognition of high-risk states such as suicidal ideation and self-harm is safety-critical. However, existing evaluations primarily rely on aggregate performance metrics, which often obscure risk-specific failure modes and provide limited insight into model behavior in realistic, multi-turn interactions. We present MHDash, an open-source platform designed to support the development, evaluation, and auditing of AI systems for mental health applications. MHDash integrates data collection, structured annotation, multi-turn dialogue generation, and baseline evaluation into a unified pipeline. The platform supports annotations across multiple dimensions, including Concern Type, Risk Level, and Dialogue Intent, enabling fine-grained and risk-aware analysis. Our results reveal several key findings: (i) simple baselines and advanced LLM APIs exhibit comparable overall accuracy yet diverge significantly on high-risk cases; (ii) some LLMs maintain consistent ordinal severity ranking while failing absolute risk classification, whereas others achieve reasonable aggregate scores but suffer from high false negative rates on severe categories; and (iii) performance gaps are amplified in multi-turn dialogues, where risk signals emerge gradually. These observations demonstrate that conventional benchmarks are insufficient for safety-critical mental health settings. By releasing MHDash as an open platform, we aim to promote reproducible research, transparent evaluation, and safety-aligned development of AI systems for mental health support.
Unified Kernel-Segregated Transpose Convolution Operation
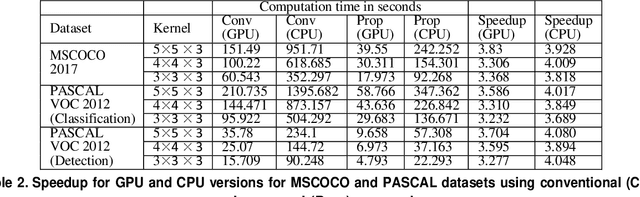
Feb 27, 2025The optimization of the transpose convolution layer for deep learning applications is achieved with the kernel segregation mechanism. However, kernel segregation has disadvantages, such as computing extra elements to obtain the output feature map with odd dimensions while launching a thread. To mitigate this problem, we introduce a unified kernel segregation approach that limits the usage of memory and computational resources by employing one unified kernel to execute four sub-kernels. The findings reveal that the suggested approach achieves an average computational speedup of 2.03x (3.89x) when tested on specific datasets with an RTX 2070 GPU (Intel Xeon CPU). The ablation study shows an average computational speedup of 3.5x when evaluating the transpose convolution layers from well-known Generative Adversarial Networks (GANs). The implementation of the proposed method for the transpose convolution layers in the EB-GAN model demonstrates significant memory savings of up to 35 MB.
Securing the Future: Exploring Privacy Risks and Security Questions in Robotic Systems
Sep 16, 2024The integration of artificial intelligence, especially large language models in robotics, has led to rapid advancements in the field. We are now observing an unprecedented surge in the use of robots in our daily lives. The development and continual improvements of robots are moving at an astonishing pace. Although these remarkable improvements facilitate and enhance our lives, several security and privacy concerns have not been resolved yet. Therefore, it has become crucial to address the privacy and security threats of robotic systems while improving our experiences. In this paper, we aim to present existing applications and threats of robotics, anticipated future evolution, and the security and privacy issues they may imply. We present a series of open questions for researchers and practitioners to explore further.
* 11 pages, Conference Paper
Can't say cant? Measuring and Reasoning of Dark Jargons in Large Language Models
Apr 25, 2024



Ensuring the resilience of Large Language Models (LLMs) against malicious exploitation is paramount, with recent focus on mitigating offensive responses. Yet, the understanding of cant or dark jargon remains unexplored. This paper introduces a domain-specific Cant dataset and CantCounter evaluation framework, employing Fine-Tuning, Co-Tuning, Data-Diffusion, and Data-Analysis stages. Experiments reveal LLMs, including ChatGPT, are susceptible to cant bypassing filters, with varying recognition accuracy influenced by question types, setups, and prompt clues. Updated models exhibit higher acceptance rates for cant queries. Moreover, LLM reactions differ across domains, e.g., reluctance to engage in racism versus LGBT topics. These findings underscore LLMs' understanding of cant and reflect training data characteristics and vendor approaches to sensitive topics. Additionally, we assess LLMs' ability to demonstrate reasoning capabilities. Access to our datasets and code is available at https://github.com/cistineup/CantCounter.
Facebook Report on Privacy of fNIRS data
Jan 01, 2024The primary goal of this project is to develop privacy-preserving machine learning model training techniques for fNIRS data. This project will build a local model in a centralized setting with both differential privacy (DP) and certified robustness. It will also explore collaborative federated learning to train a shared model between multiple clients without sharing local fNIRS datasets. To prevent unintentional private information leakage of such clients' private datasets, we will also implement DP in the federated learning setting.
Kernel-Segregated Transpose Convolution Operation
Sep 08, 2022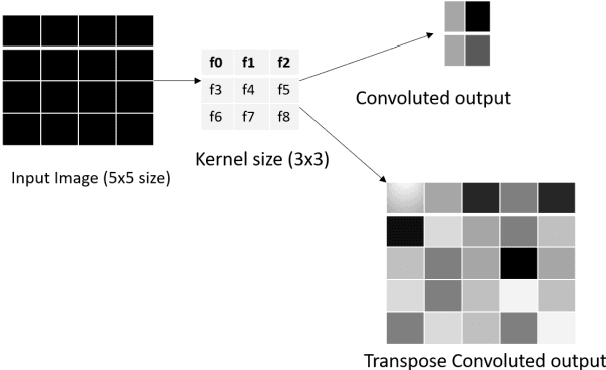

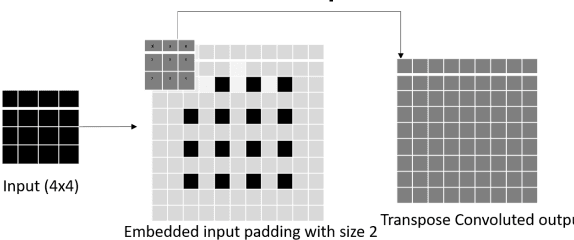
Transpose convolution has shown prominence in many deep learning applications. However, transpose convolution layers are computationally intensive due to the increased feature map size due to adding zeros after each element in each row and column. Thus, convolution operation on the expanded input feature map leads to poor utilization of hardware resources. The main reason for unnecessary multiplication operations is zeros at predefined positions in the input feature map. We propose an algorithmic-level optimization technique for the effective transpose convolution implementation to solve these problems. Based on kernel activations, we segregated the original kernel into four sub-kernels. This scheme could reduce memory requirements and unnecessary multiplications. Our proposed method was $3.09 (3.02) \times$ faster computation using the Titan X GPU (Intel Dual Core CPU) with a flower dataset from the Kaggle website. Furthermore, the proposed optimization method can be generalized to existing devices without additional hardware requirements. A simple deep learning model containing one transpose convolution layer was used to evaluate the optimization method. It showed $2.2 \times$ faster training using the MNIST dataset with an Intel Dual-core CPU than the conventional implementation.
Privacy-Preserving Deep Learning Model for Covid-19 Disease Detection
Sep 07, 2022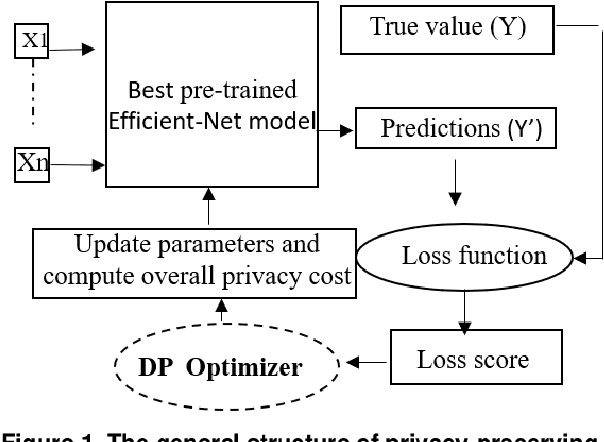
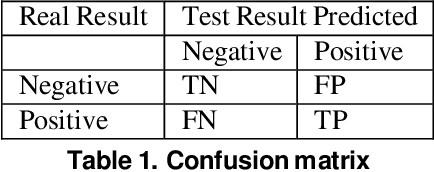
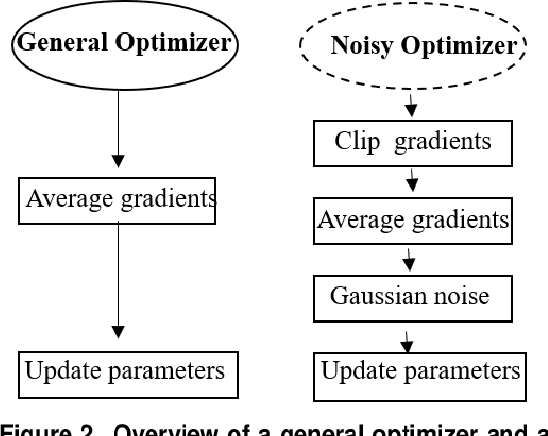
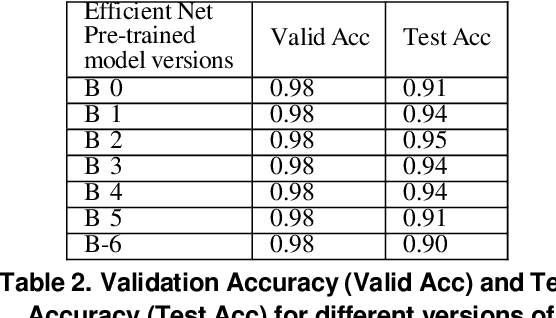
Recent studies demonstrated that X-ray radiography showed higher accuracy than Polymerase Chain Reaction (PCR) testing for COVID-19 detection. Therefore, applying deep learning models to X-rays and radiography images increases the speed and accuracy of determining COVID-19 cases. However, due to Health Insurance Portability and Accountability (HIPAA) compliance, the hospitals were unwilling to share patient data due to privacy concerns. To maintain privacy, we propose differential private deep learning models to secure the patients' private information. The dataset from the Kaggle website is used to evaluate the designed model for COVID-19 detection. The EfficientNet model version was selected according to its highest test accuracy. The injection of differential privacy constraints into the best-obtained model was made to evaluate performance. The accuracy is noted by varying the trainable layers, privacy loss, and limiting information from each sample. We obtained 84\% accuracy with a privacy loss of 10 during the fine-tuning process.
aaeCAPTCHA: The Design and Implementation of Audio Adversarial CAPTCHA
Mar 05, 2022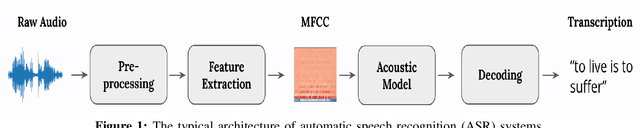
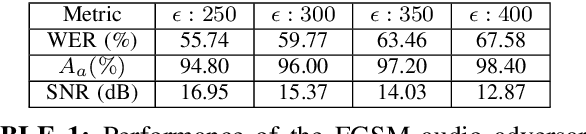
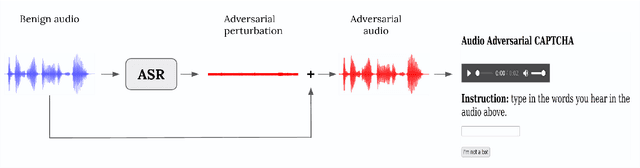
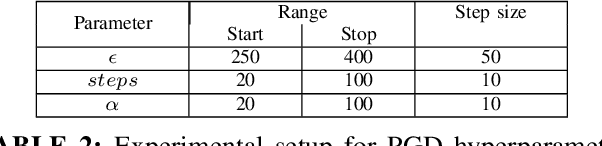
CAPTCHAs are designed to prevent malicious bot programs from abusing websites. Most online service providers deploy audio CAPTCHAs as an alternative to text and image CAPTCHAs for visually impaired users. However, prior research investigating the security of audio CAPTCHAs found them highly vulnerable to automated attacks using Automatic Speech Recognition (ASR) systems. To improve the robustness of audio CAPTCHAs against automated abuses, we present the design and implementation of an audio adversarial CAPTCHA (aaeCAPTCHA) system in this paper. The aaeCAPTCHA system exploits audio adversarial examples as CAPTCHAs to prevent the ASR systems from automatically solving them. Furthermore, we conducted a rigorous security evaluation of our new audio CAPTCHA design against five state-of-the-art DNN-based ASR systems and three commercial Speech-to-Text (STT) services. Our experimental evaluations demonstrate that aaeCAPTCHA is highly secure against these speech recognition technologies, even when the attacker has complete knowledge of the current attacks against audio adversarial examples. We also conducted a usability evaluation of the proof-of-concept implementation of the aaeCAPTCHA scheme. Our results show that it achieves high robustness at a moderate usability cost compared to normal audio CAPTCHAs. Finally, our extensive analysis highlights that aaeCAPTCHA can significantly enhance the security and robustness of traditional audio CAPTCHA systems while maintaining similar usability.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
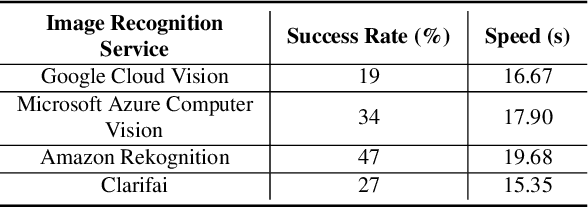
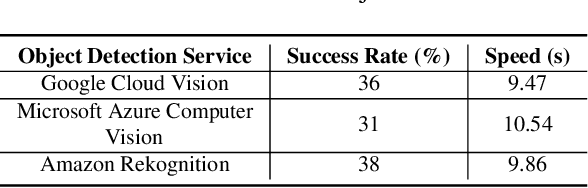
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.
Stacked LSTM Based Deep Recurrent Neural Network with Kalman Smoothing for Blood Glucose Prediction
Jan 18, 2021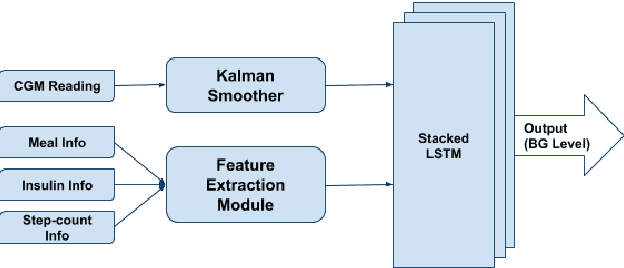
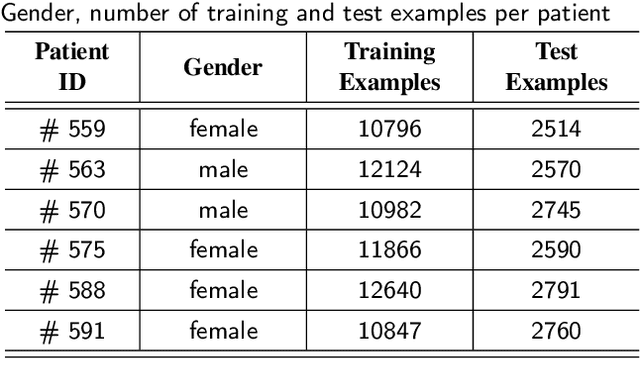
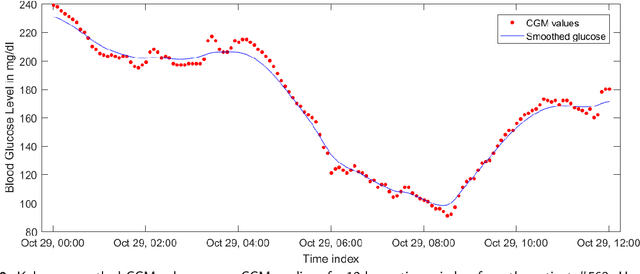
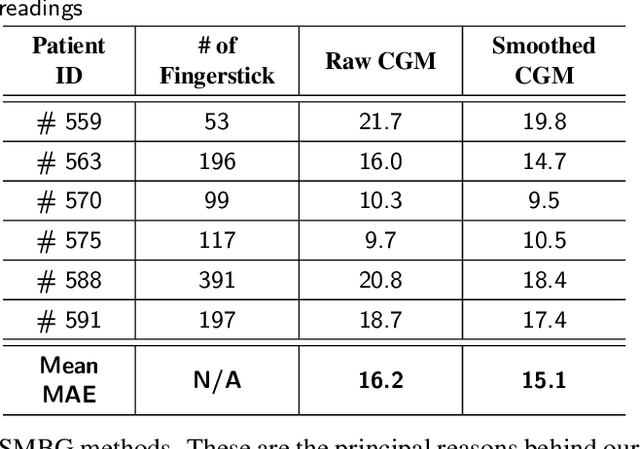
Blood glucose (BG) management is crucial for type-1 diabetes patients resulting in the necessity of reliable artificial pancreas or insulin infusion systems. In recent years, deep learning techniques have been utilized for a more accurate BG level prediction system. However, continuous glucose monitoring (CGM) readings are susceptible to sensor errors. As a result, inaccurate CGM readings would affect BG prediction and make it unreliable, even if the most optimal machine learning model is used. In this work, we propose a novel approach to predicting blood glucose level with a stacked Long short-term memory (LSTM) based deep recurrent neural network (RNN) model considering sensor fault. We use the Kalman smoothing technique for the correction of the inaccurate CGM readings due to sensor error. For the OhioT1DM dataset, containing eight weeks' data from six different patients, we achieve an average RMSE of 6.45 and 17.24 mg/dl for 30 minutes and 60 minutes of prediction horizon (PH), respectively. To the best of our knowledge, this is the leading average prediction accuracy for the ohioT1DM dataset. Different physiological information, e.g., Kalman smoothed CGM data, carbohydrates from the meal, bolus insulin, and cumulative step counts in a fixed time interval, are crafted to represent meaningful features used as input to the model. The goal of our approach is to lower the difference between the predicted CGM values and the fingerstick blood glucose readings - the ground truth. Our results indicate that the proposed approach is feasible for more reliable BG forecasting that might improve the performance of the artificial pancreas and insulin infusion system for T1D diabetes management.