 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMHDash: An Online Platform for Benchmarking Mental Health-Aware AI Assistants
Jan 30, 2026Large language models (LLMs) are increasingly applied in mental health support systems, where reliable recognition of high-risk states such as suicidal ideation and self-harm is safety-critical. However, existing evaluations primarily rely on aggregate performance metrics, which often obscure risk-specific failure modes and provide limited insight into model behavior in realistic, multi-turn interactions. We present MHDash, an open-source platform designed to support the development, evaluation, and auditing of AI systems for mental health applications. MHDash integrates data collection, structured annotation, multi-turn dialogue generation, and baseline evaluation into a unified pipeline. The platform supports annotations across multiple dimensions, including Concern Type, Risk Level, and Dialogue Intent, enabling fine-grained and risk-aware analysis. Our results reveal several key findings: (i) simple baselines and advanced LLM APIs exhibit comparable overall accuracy yet diverge significantly on high-risk cases; (ii) some LLMs maintain consistent ordinal severity ranking while failing absolute risk classification, whereas others achieve reasonable aggregate scores but suffer from high false negative rates on severe categories; and (iii) performance gaps are amplified in multi-turn dialogues, where risk signals emerge gradually. These observations demonstrate that conventional benchmarks are insufficient for safety-critical mental health settings. By releasing MHDash as an open platform, we aim to promote reproducible research, transparent evaluation, and safety-aligned development of AI systems for mental health support.
Unified Kernel-Segregated Transpose Convolution Operation
Feb 27, 2025The optimization of the transpose convolution layer for deep learning applications is achieved with the kernel segregation mechanism. However, kernel segregation has disadvantages, such as computing extra elements to obtain the output feature map with odd dimensions while launching a thread. To mitigate this problem, we introduce a unified kernel segregation approach that limits the usage of memory and computational resources by employing one unified kernel to execute four sub-kernels. The findings reveal that the suggested approach achieves an average computational speedup of 2.03x (3.89x) when tested on specific datasets with an RTX 2070 GPU (Intel Xeon CPU). The ablation study shows an average computational speedup of 3.5x when evaluating the transpose convolution layers from well-known Generative Adversarial Networks (GANs). The implementation of the proposed method for the transpose convolution layers in the EB-GAN model demonstrates significant memory savings of up to 35 MB.
Facebook Report on Privacy of fNIRS data
Jan 01, 2024The primary goal of this project is to develop privacy-preserving machine learning model training techniques for fNIRS data. This project will build a local model in a centralized setting with both differential privacy (DP) and certified robustness. It will also explore collaborative federated learning to train a shared model between multiple clients without sharing local fNIRS datasets. To prevent unintentional private information leakage of such clients' private datasets, we will also implement DP in the federated learning setting.
Auto DP-SGD: Dual Improvements of Privacy and Accuracy via Automatic Clipping Threshold and Noise Multiplier Estimation
Dec 05, 2023



DP-SGD has emerged as a popular method to protect personally identifiable information in deep learning applications. Unfortunately, DP-SGD's per-sample gradient clipping and uniform noise addition during training can significantly degrade model utility. To enhance the model's utility, researchers proposed various adaptive DP-SGD methods. However, we examine and discover that these techniques result in greater privacy leakage or lower accuracy than the traditional DP-SGD method, or a lack of evaluation on a complex data set such as CIFAR100. To address these limitations, we propose an Auto DP-SGD. Our method automates clipping threshold estimation based on the DL model's gradient norm and scales the gradients of each training sample without losing gradient information. This helps to improve the algorithm's utility while using a less privacy budget. To further improve accuracy, we introduce automatic noise multiplier decay mechanisms to decrease the noise multiplier after every epoch. Finally, we develop closed-form mathematical expressions using tCDP accountant for automatic noise multiplier and automatic clipping threshold estimation. Through extensive experimentation, we demonstrate that Auto DP-SGD outperforms existing SOTA DP-SGD methods in privacy and accuracy on various benchmark datasets. We also show that privacy can be improved by lowering the scale factor and using learning rate schedulers without significantly reducing accuracy. Specifically, Auto DP-SGD, when used with a step noise multiplier, improves accuracy by 3.20, 1.57, 6.73, and 1.42 for the MNIST, CIFAR10, CIFAR100, and AG News Corpus datasets, respectively. Furthermore, it obtains a substantial reduction in the privacy budget of 94.9, 79.16, 67.36, and 53.37 for the corresponding data sets.
Kernel-Segregated Transpose Convolution Operation
Sep 08, 2022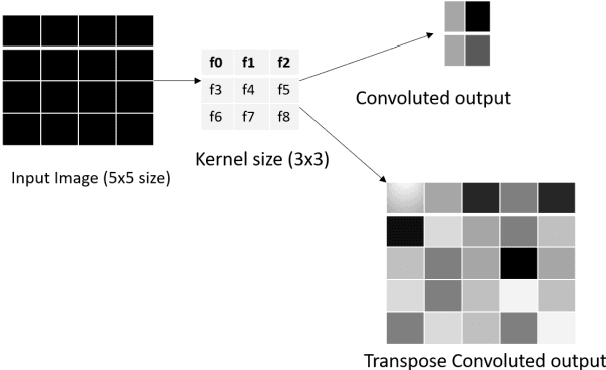

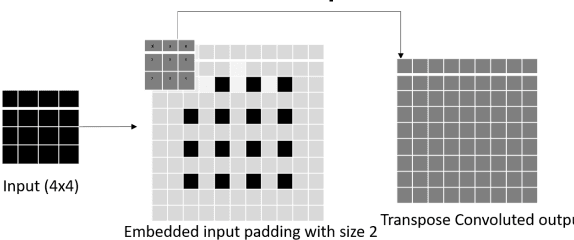
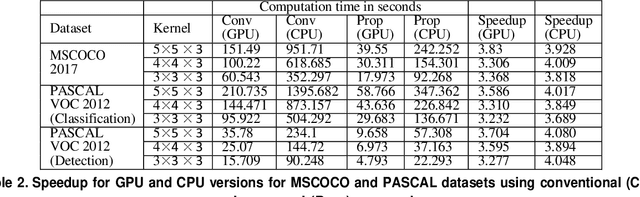
Transpose convolution has shown prominence in many deep learning applications. However, transpose convolution layers are computationally intensive due to the increased feature map size due to adding zeros after each element in each row and column. Thus, convolution operation on the expanded input feature map leads to poor utilization of hardware resources. The main reason for unnecessary multiplication operations is zeros at predefined positions in the input feature map. We propose an algorithmic-level optimization technique for the effective transpose convolution implementation to solve these problems. Based on kernel activations, we segregated the original kernel into four sub-kernels. This scheme could reduce memory requirements and unnecessary multiplications. Our proposed method was $3.09 (3.02) \times$ faster computation using the Titan X GPU (Intel Dual Core CPU) with a flower dataset from the Kaggle website. Furthermore, the proposed optimization method can be generalized to existing devices without additional hardware requirements. A simple deep learning model containing one transpose convolution layer was used to evaluate the optimization method. It showed $2.2 \times$ faster training using the MNIST dataset with an Intel Dual-core CPU than the conventional implementation.
Universal Spam Detection using Transfer Learning of BERT Model
Feb 07, 2022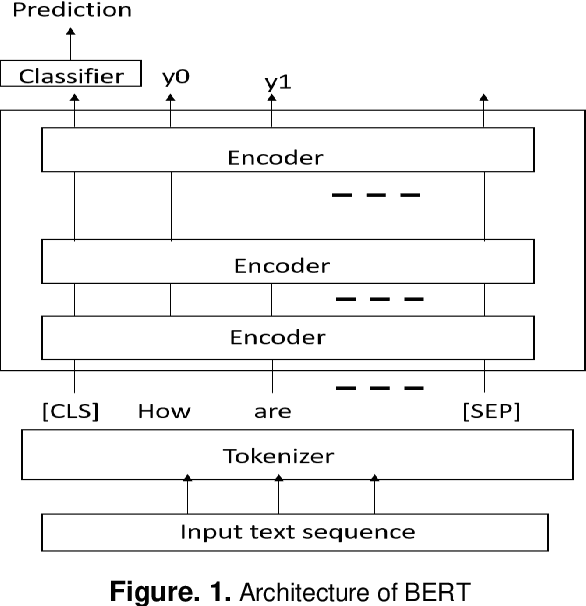



Deep learning transformer models become important by training on text data based on self-attention mechanisms. This manuscript demonstrated a novel universal spam detection model using pre-trained Google's Bidirectional Encoder Representations from Transformers (BERT) base uncased models with four datasets by efficiently classifying ham or spam emails in real-time scenarios. Different methods for Enron, Spamassain, Lingspam, and Spamtext message classification datasets, were used to train models individually in which a single model was obtained with acceptable performance on four datasets. The Universal Spam Detection Model (USDM) was trained with four datasets and leveraged hyperparameters from each model. The combined model was finetuned with the same hyperparameters from these four models separately. When each model using its corresponding dataset, an F1-score is at and above 0.9 in individual models. An overall accuracy reached 97%, with an F1 score of 0.96. Research results and implications were discussed.
Unified Fake News Detection using Transfer Learning of Bidirectional Encoder Representation from Transformers model
Feb 03, 2022

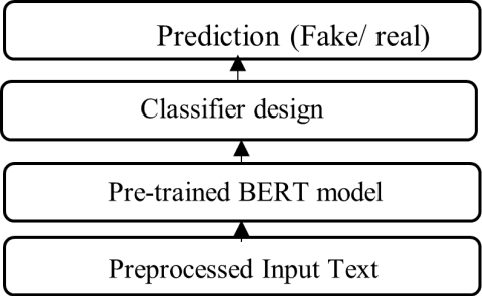
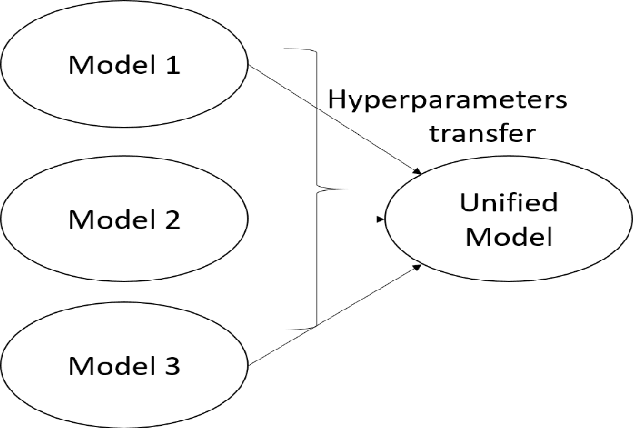
Automatic detection of fake news is needed for the public as the accessibility of social media platforms has been increasing rapidly. Most of the prior models were designed and validated on individual datasets separately. But the lack of generalization in models might lead to poor performance when deployed in real-world applications since the individual datasets only cover limited subjects and sequence length over the samples. This paper attempts to develop a unified model by combining publicly available datasets to detect fake news samples effectively.