 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Kernel-Segregated Transpose Convolution Operation
Feb 27, 2025The optimization of the transpose convolution layer for deep learning applications is achieved with the kernel segregation mechanism. However, kernel segregation has disadvantages, such as computing extra elements to obtain the output feature map with odd dimensions while launching a thread. To mitigate this problem, we introduce a unified kernel segregation approach that limits the usage of memory and computational resources by employing one unified kernel to execute four sub-kernels. The findings reveal that the suggested approach achieves an average computational speedup of 2.03x (3.89x) when tested on specific datasets with an RTX 2070 GPU (Intel Xeon CPU). The ablation study shows an average computational speedup of 3.5x when evaluating the transpose convolution layers from well-known Generative Adversarial Networks (GANs). The implementation of the proposed method for the transpose convolution layers in the EB-GAN model demonstrates significant memory savings of up to 35 MB.
Kernel-Segregated Transpose Convolution Operation
Sep 08, 2022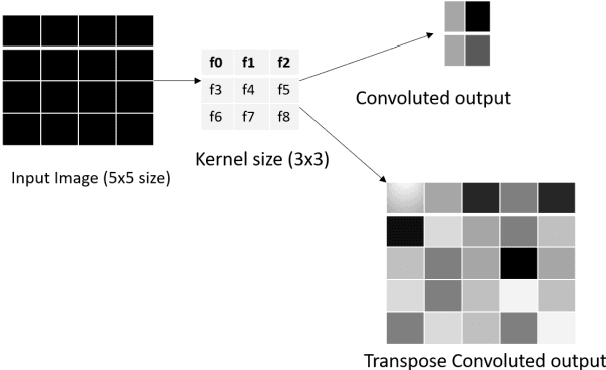

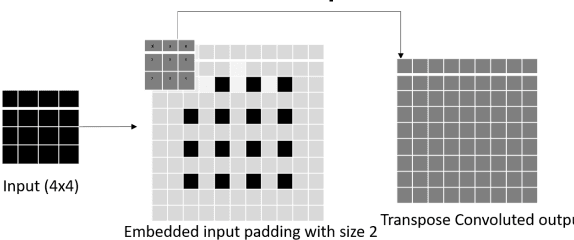
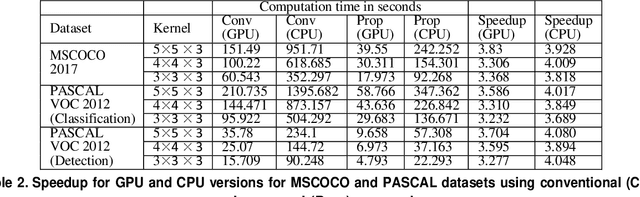
Transpose convolution has shown prominence in many deep learning applications. However, transpose convolution layers are computationally intensive due to the increased feature map size due to adding zeros after each element in each row and column. Thus, convolution operation on the expanded input feature map leads to poor utilization of hardware resources. The main reason for unnecessary multiplication operations is zeros at predefined positions in the input feature map. We propose an algorithmic-level optimization technique for the effective transpose convolution implementation to solve these problems. Based on kernel activations, we segregated the original kernel into four sub-kernels. This scheme could reduce memory requirements and unnecessary multiplications. Our proposed method was $3.09 (3.02) \times$ faster computation using the Titan X GPU (Intel Dual Core CPU) with a flower dataset from the Kaggle website. Furthermore, the proposed optimization method can be generalized to existing devices without additional hardware requirements. A simple deep learning model containing one transpose convolution layer was used to evaluate the optimization method. It showed $2.2 \times$ faster training using the MNIST dataset with an Intel Dual-core CPU than the conventional implementation.
Privacy-Preserving Deep Learning Model for Covid-19 Disease Detection
Sep 07, 2022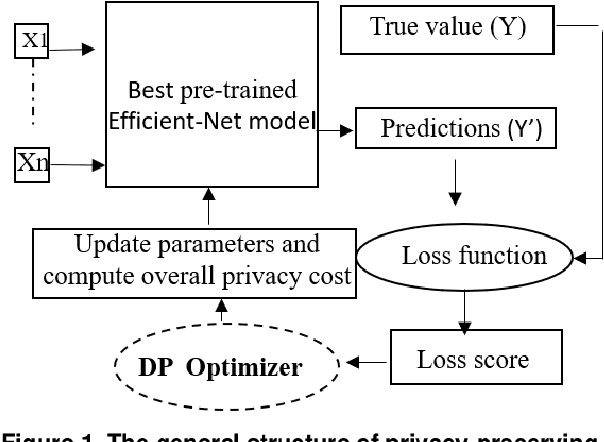
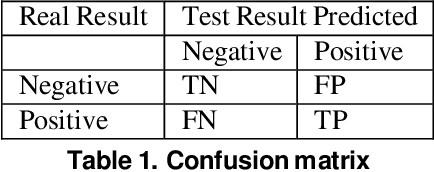
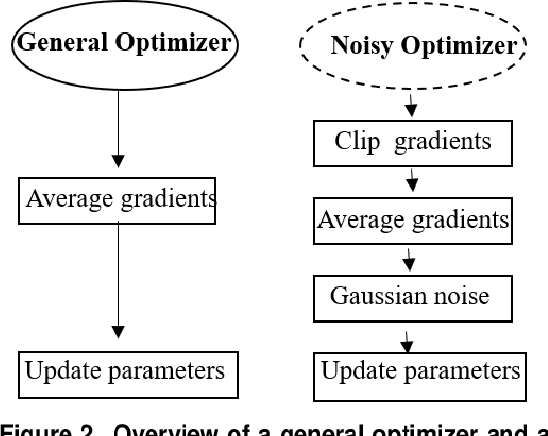
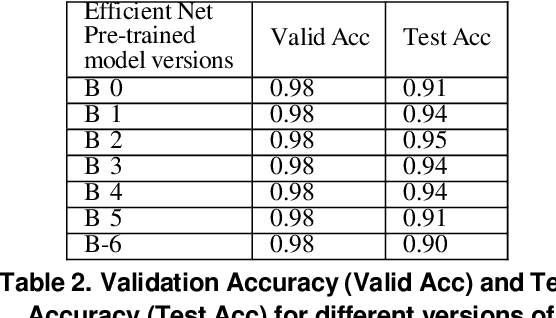
Recent studies demonstrated that X-ray radiography showed higher accuracy than Polymerase Chain Reaction (PCR) testing for COVID-19 detection. Therefore, applying deep learning models to X-rays and radiography images increases the speed and accuracy of determining COVID-19 cases. However, due to Health Insurance Portability and Accountability (HIPAA) compliance, the hospitals were unwilling to share patient data due to privacy concerns. To maintain privacy, we propose differential private deep learning models to secure the patients' private information. The dataset from the Kaggle website is used to evaluate the designed model for COVID-19 detection. The EfficientNet model version was selected according to its highest test accuracy. The injection of differential privacy constraints into the best-obtained model was made to evaluate performance. The accuracy is noted by varying the trainable layers, privacy loss, and limiting information from each sample. We obtained 84\% accuracy with a privacy loss of 10 during the fine-tuning process.
Universal Spam Detection using Transfer Learning of BERT Model
Feb 07, 2022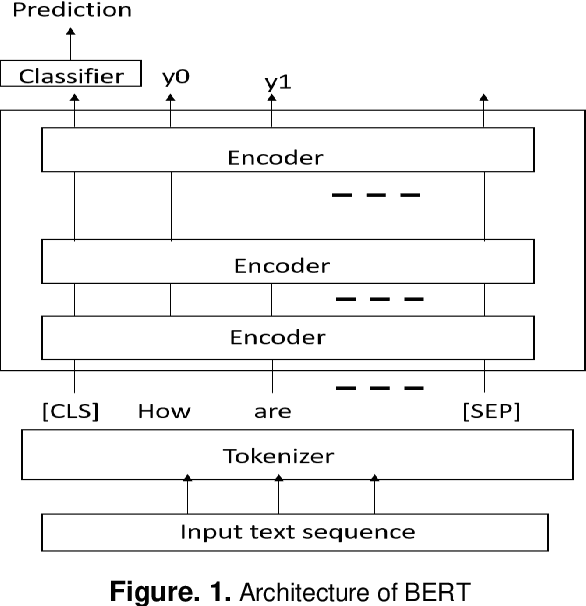



Deep learning transformer models become important by training on text data based on self-attention mechanisms. This manuscript demonstrated a novel universal spam detection model using pre-trained Google's Bidirectional Encoder Representations from Transformers (BERT) base uncased models with four datasets by efficiently classifying ham or spam emails in real-time scenarios. Different methods for Enron, Spamassain, Lingspam, and Spamtext message classification datasets, were used to train models individually in which a single model was obtained with acceptable performance on four datasets. The Universal Spam Detection Model (USDM) was trained with four datasets and leveraged hyperparameters from each model. The combined model was finetuned with the same hyperparameters from these four models separately. When each model using its corresponding dataset, an F1-score is at and above 0.9 in individual models. An overall accuracy reached 97%, with an F1 score of 0.96. Research results and implications were discussed.