 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked LSTM Based Deep Recurrent Neural Network with Kalman Smoothing for Blood Glucose Prediction
Jan 18, 2021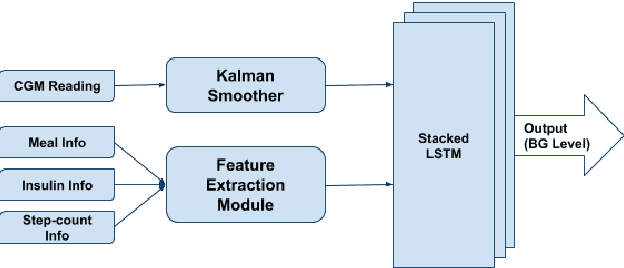
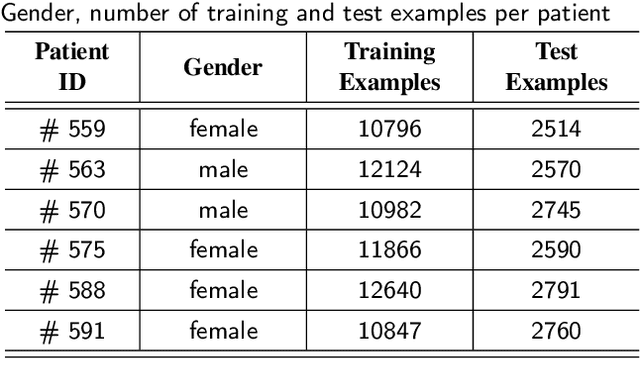
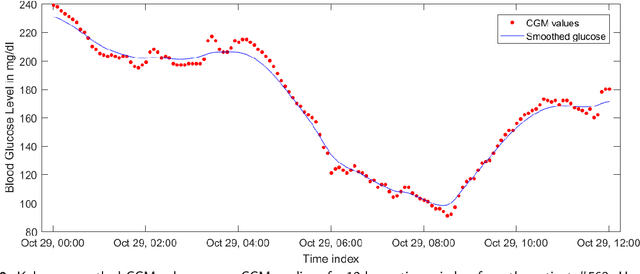
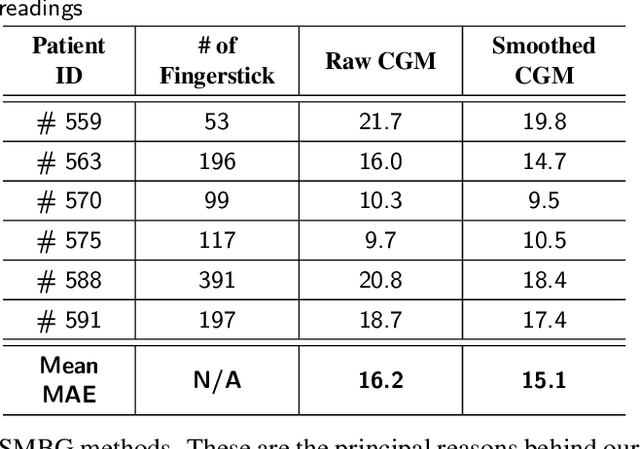
Blood glucose (BG) management is crucial for type-1 diabetes patients resulting in the necessity of reliable artificial pancreas or insulin infusion systems. In recent years, deep learning techniques have been utilized for a more accurate BG level prediction system. However, continuous glucose monitoring (CGM) readings are susceptible to sensor errors. As a result, inaccurate CGM readings would affect BG prediction and make it unreliable, even if the most optimal machine learning model is used. In this work, we propose a novel approach to predicting blood glucose level with a stacked Long short-term memory (LSTM) based deep recurrent neural network (RNN) model considering sensor fault. We use the Kalman smoothing technique for the correction of the inaccurate CGM readings due to sensor error. For the OhioT1DM dataset, containing eight weeks' data from six different patients, we achieve an average RMSE of 6.45 and 17.24 mg/dl for 30 minutes and 60 minutes of prediction horizon (PH), respectively. To the best of our knowledge, this is the leading average prediction accuracy for the ohioT1DM dataset. Different physiological information, e.g., Kalman smoothed CGM data, carbohydrates from the meal, bolus insulin, and cumulative step counts in a fixed time interval, are crafted to represent meaningful features used as input to the model. The goal of our approach is to lower the difference between the predicted CGM values and the fingerstick blood glucose readings - the ground truth. Our results indicate that the proposed approach is feasible for more reliable BG forecasting that might improve the performance of the artificial pancreas and insulin infusion system for T1D diabetes management.
Generalizing Complex/Hyper-complex Convolutions to Vector Map Convolutions
Sep 09, 2020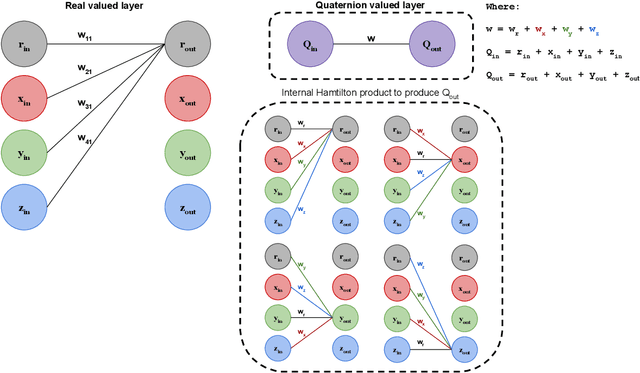
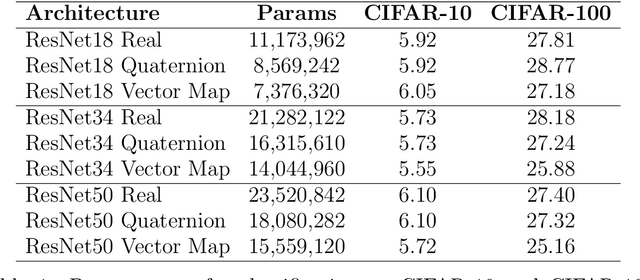
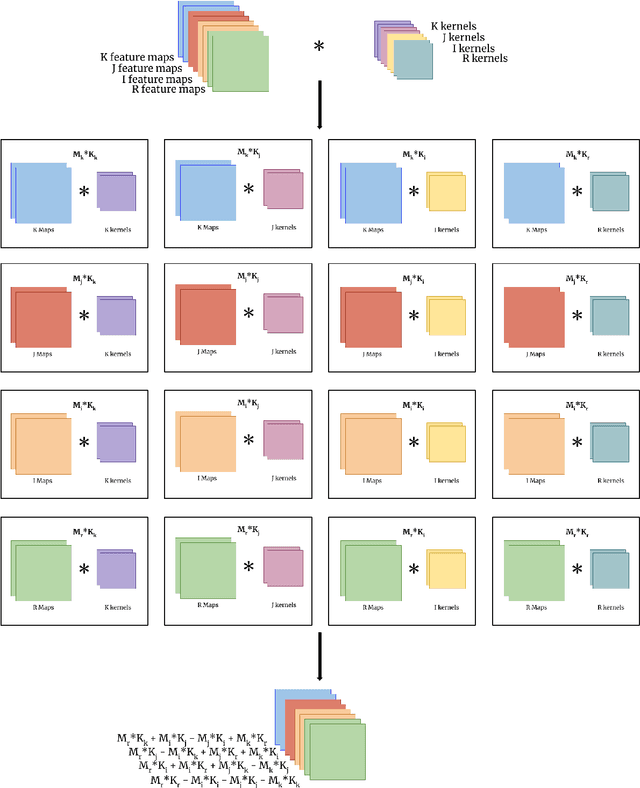

We show that the core reasons that complex and hypercomplex valued neural networks offer improvements over their real-valued counterparts is the weight sharing mechanism and treating multidimensional data as a single entity. Their algebra linearly combines the dimensions, making each dimension related to the others. However, both are constrained to a set number of dimensions, two for complex and four for quaternions. Here we introduce novel vector map convolutions which capture both of these properties provided by complex/hypercomplex convolutions, while dropping the unnatural dimensionality constraints they impose. This is achieved by introducing a system that mimics the unique linear combination of input dimensions, such as the Hamilton product for quaternions. We perform three experiments to show that these novel vector map convolutions seem to capture all the benefits of complex and hyper-complex networks, such as their ability to capture internal latent relations, while avoiding the dimensionality restriction.
A Spiking Network that Learns to Extract Spike Signatures from Speech Signals
Mar 12, 2017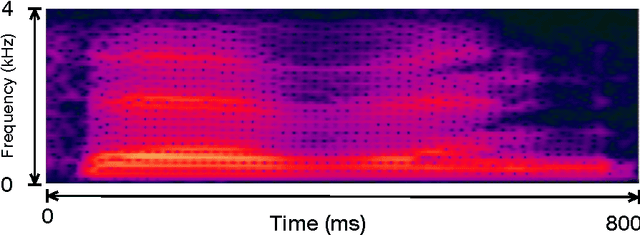

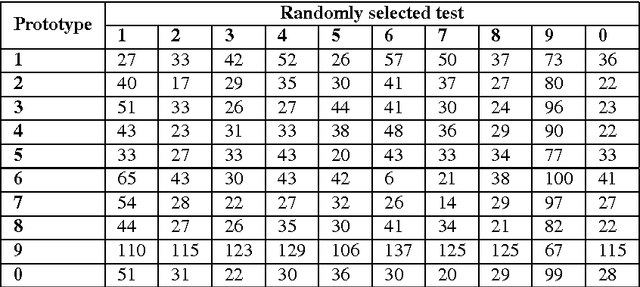
Spiking neural networks (SNNs) with adaptive synapses reflect core properties of biological neural networks. Speech recognition, as an application involving audio coding and dynamic learning, provides a good test problem to study SNN functionality. We present a simple, novel, and efficient nonrecurrent SNN that learns to convert a speech signal into a spike train signature. The signature is distinguishable from signatures for other speech signals representing different words, thereby enabling digit recognition and discrimination in devices that use only spiking neurons. The method uses a small, nonrecurrent SNN consisting of Izhikevich neurons equipped with spike timing dependent plasticity (STDP) and biologically realistic synapses. This approach introduces an efficient and fast network without error-feedback training, although it does require supervised training. The new simulation results produce discriminative spike train patterns for spoken digits in which highly correlated spike trains belong to the same category and low correlated patterns belong to different categories. The proposed SNN is evaluated using a spoken digit recognition task where a subset of the Aurora speech dataset is used. The experimental results show that the network performs well in terms of accuracy rate and complexity.
* Published in Neurocomputing Journal, Elsevier
Acquisition of Visual Features Through Probabilistic Spike-Timing-Dependent Plasticity
Nov 09, 2016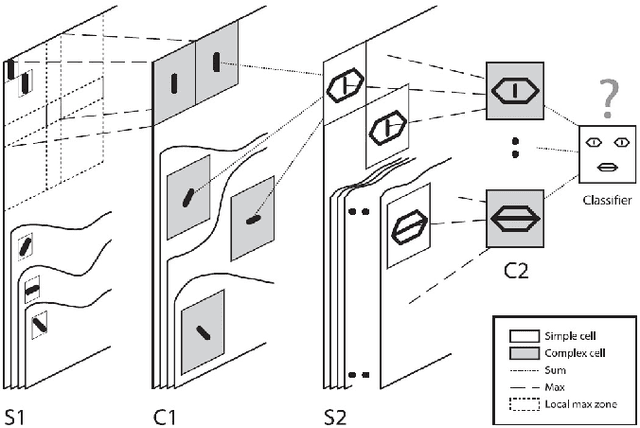

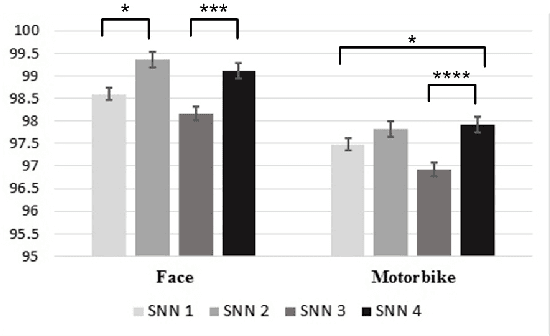
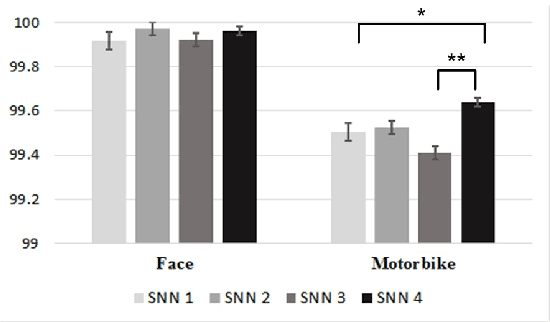
The final version of this paper has been published in IEEEXplore available at http://ieeexplore.ieee.org/document/7727213. Please cite this paper as: Amirhossein Tavanaei, Timothee Masquelier, and Anthony Maida, Acquisition of visual features through probabilistic spike-timing-dependent plasticity. IEEE International Joint Conference on Neural Networks. pp. 307-314, IJCNN 2016. This paper explores modifications to a feedforward five-layer spiking convolutional network (SCN) of the ventral visual stream [Masquelier, T., Thorpe, S., Unsupervised learning of visual features through spike timing dependent plasticity. PLoS Computational Biology, 3(2), 247-257]. The original model showed that a spike-timing-dependent plasticity (STDP) learning algorithm embedded in an appropriately selected SCN could perform unsupervised feature discovery. The discovered features where interpretable and could effectively be used to perform rapid binary decisions in a classifier. In order to study the robustness of the previous results, the present research examines the effects of modifying some of the components of the original model. For improved biological realism, we replace the original non-leaky integrate-and-fire neurons with Izhikevich-like neurons. We also replace the original STDP rule with a novel rule that has a probabilistic interpretation. The probabilistic STDP slightly but significantly improves the performance for both types of model neurons. Use of the Izhikevich-like neuron was not found to improve performance although performance was still comparable to the IF neuron. This shows that the model is robust enough to handle more biologically realistic neurons. We also conclude that the underlying reasons for stable performance in the model are preserved despite the overt changes to the explicit components of the model.
* IEEE-IJCNN 2016
Training a Hidden Markov Model with a Bayesian Spiking Neural Network
Jul 20, 2016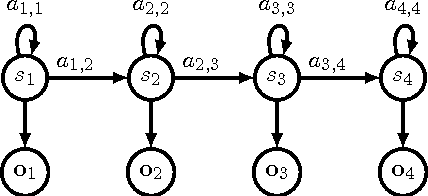
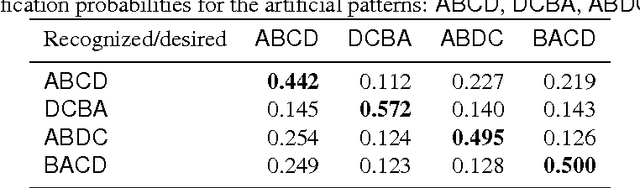
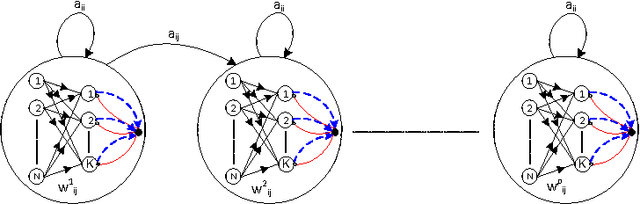
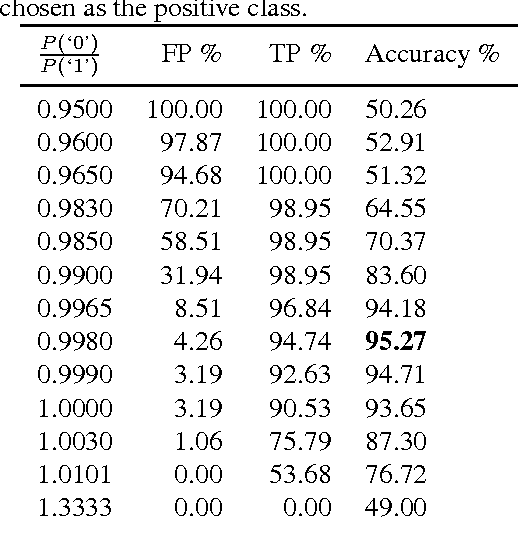
It is of some interest to understand how statistically based mechanisms for signal processing might be integrated with biologically motivated mechanisms such as neural networks. This paper explores a novel hybrid approach for classifying segments of sequential data, such as individual spoken works. The approach combines a hidden Markov model (HMM) with a spiking neural network (SNN). The HMM, consisting of states and transitions, forms a fixed backbone with nonadaptive transition probabilities. The SNN, however, implements a biologically based Bayesian computation that derives from the spike timing-dependent plasticity (STDP) learning rule. The emission (observation) probabilities of the HMM are represented in the SNN and trained with the STDP rule. A separate SNN, each with the same architecture, is associated with each of the states of the HMM. Because of the STDP training, each SNN implements an expectation maximization algorithm to learn the emission probabilities for one HMM state. The model was studied on synthesized spike-train data and also on spoken word data. Preliminary results suggest its performance compares favorably with other biologically motivated approaches. Because of the model's uniqueness and initial promise, it warrants further study. It provides some new ideas on how the brain might implement the equivalent of an HMM in a neural circuit.
* Bayesian Spiking Neural Network, Revision submitted: April-27-2016