 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepFakes: Detecting Forged and Synthetic Media Content Using Machine Learning
Sep 07, 2021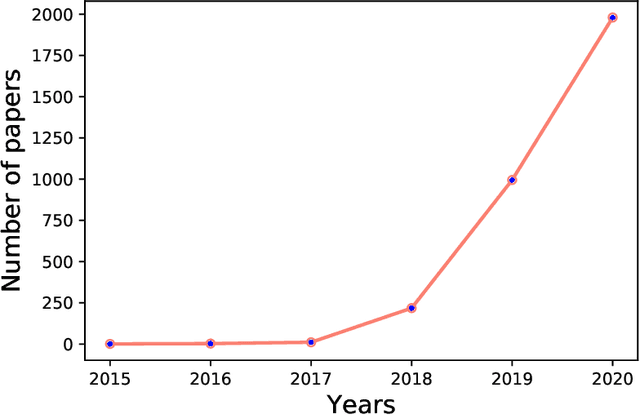
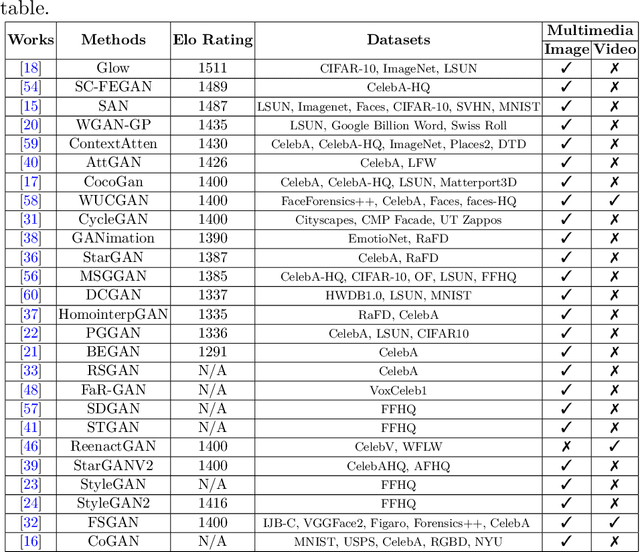
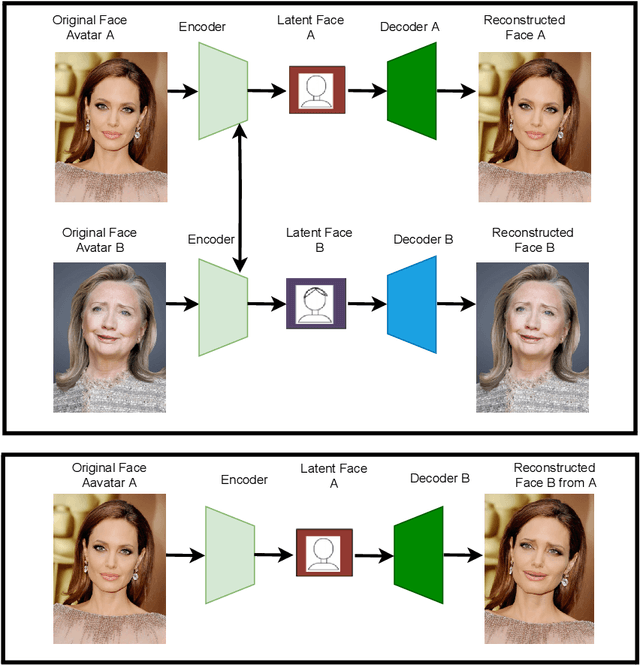
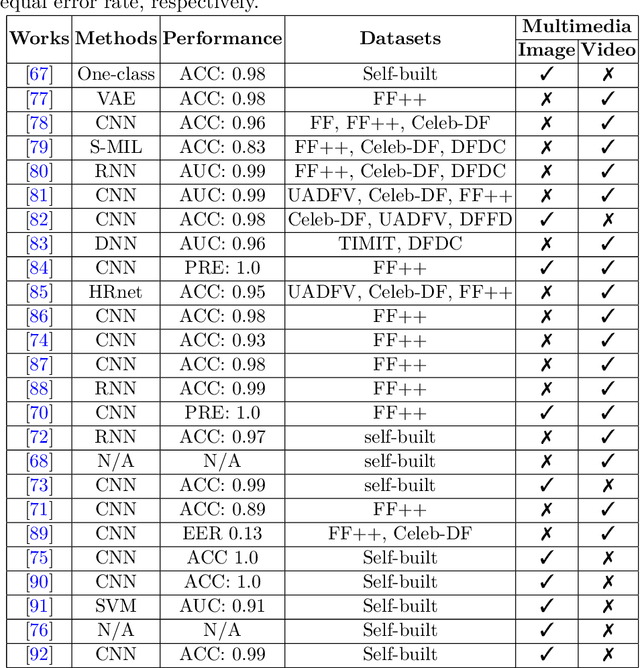
The rapid advancement in deep learning makes the differentiation of authentic and manipulated facial images and video clips unprecedentedly harder. The underlying technology of manipulating facial appearances through deep generative approaches, enunciated as DeepFake that have emerged recently by promoting a vast number of malicious face manipulation applications. Subsequently, the need of other sort of techniques that can assess the integrity of digital visual content is indisputable to reduce the impact of the creations of DeepFake. A large body of research that are performed on DeepFake creation and detection create a scope of pushing each other beyond the current status. This study presents challenges, research trends, and directions related to DeepFake creation and detection techniques by reviewing the notable research in the DeepFake domain to facilitate the development of more robust approaches that could deal with the more advance DeepFake in the future.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
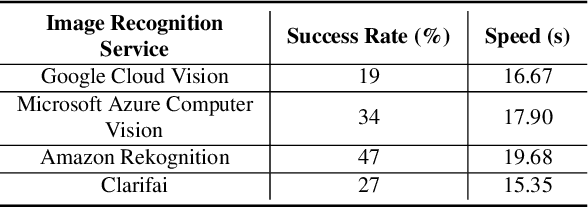
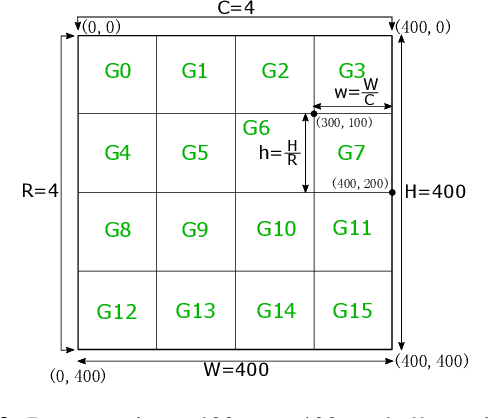
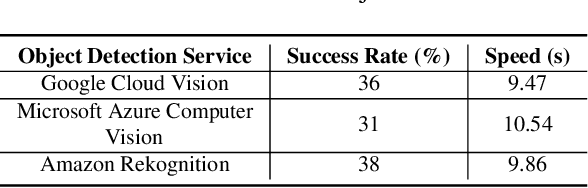
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.
SensPick: Sense Picking for Word Sense Disambiguation
Feb 10, 2021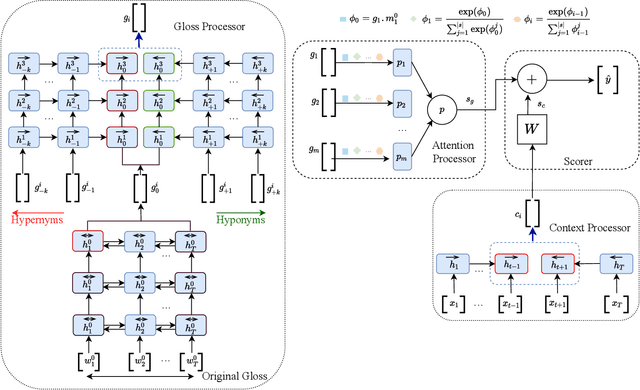
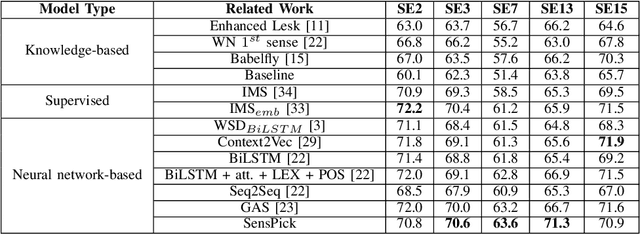
Word sense disambiguation (WSD) methods identify the most suitable meaning of a word with respect to the usage of that word in a specific context. Neural network-based WSD approaches rely on a sense-annotated corpus since they do not utilize lexical resources. In this study, we utilize both context and related gloss information of a target word to model the semantic relationship between the word and the set of glosses. We propose SensPick, a type of stacked bidirectional Long Short Term Memory (LSTM) network to perform the WSD task. The experimental evaluation demonstrates that SensPick outperforms traditional and state-of-the-art models on most of the benchmark datasets with a relative improvement of 3.5% in F-1 score. While the improvement is not significant, incorporating semantic relationships brings SensPick in the leading position compared to others.
Stacked LSTM Based Deep Recurrent Neural Network with Kalman Smoothing for Blood Glucose Prediction
Jan 18, 2021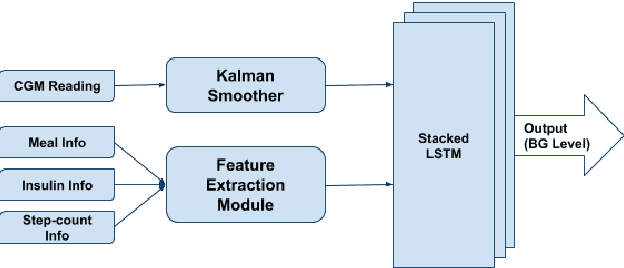
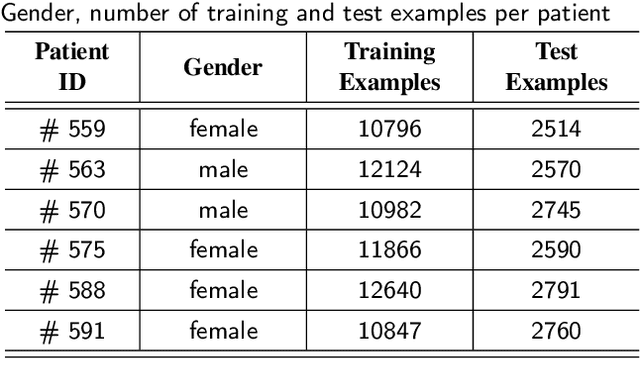
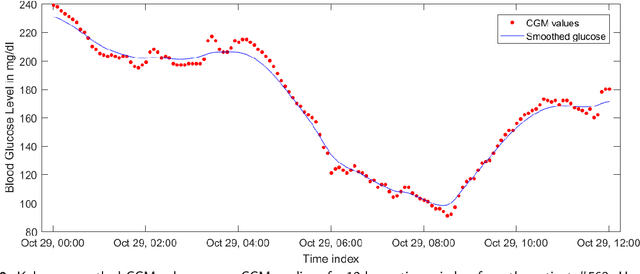
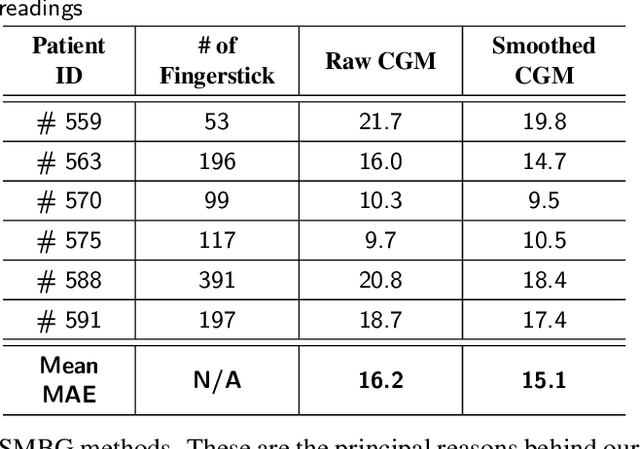
Blood glucose (BG) management is crucial for type-1 diabetes patients resulting in the necessity of reliable artificial pancreas or insulin infusion systems. In recent years, deep learning techniques have been utilized for a more accurate BG level prediction system. However, continuous glucose monitoring (CGM) readings are susceptible to sensor errors. As a result, inaccurate CGM readings would affect BG prediction and make it unreliable, even if the most optimal machine learning model is used. In this work, we propose a novel approach to predicting blood glucose level with a stacked Long short-term memory (LSTM) based deep recurrent neural network (RNN) model considering sensor fault. We use the Kalman smoothing technique for the correction of the inaccurate CGM readings due to sensor error. For the OhioT1DM dataset, containing eight weeks' data from six different patients, we achieve an average RMSE of 6.45 and 17.24 mg/dl for 30 minutes and 60 minutes of prediction horizon (PH), respectively. To the best of our knowledge, this is the leading average prediction accuracy for the ohioT1DM dataset. Different physiological information, e.g., Kalman smoothed CGM data, carbohydrates from the meal, bolus insulin, and cumulative step counts in a fixed time interval, are crafted to represent meaningful features used as input to the model. The goal of our approach is to lower the difference between the predicted CGM values and the fingerstick blood glucose readings - the ground truth. Our results indicate that the proposed approach is feasible for more reliable BG forecasting that might improve the performance of the artificial pancreas and insulin infusion system for T1D diabetes management.