 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation CAN LM: A Pretrained Language Model For Automotive CAN Data
Jan 31, 2026The Controller Area Network (CAN) bus provides a rich source of vehicular signals increasingly leveraged for applications in automotive and auto insurance domains, including collision detection, predictive maintenance, and driver risk modeling. Despite this potential, existing pipelines largely train isolated task-specific models on raw CAN data, with only limited efforts exploring decoded signals. Such fragmentation prevents shared representation learning and limits cross-task generalization. By contrast, natural language processing (NLP) and computer vision (CV) have been transformed by the foundation model paradigm: large-scale pretraining followed by task-specific adaptation. In this work, we introduce the foundation CAN model that demonstrates multi-objective downstream generalization using a single pretrained backbone. Our approach treats CAN data as a language: we pretrain on large-scale, unlabeled decoded CAN signals and fine-tune across heterogeneous auto insurance tasks. To enable this, we propose a unified tokenization scheme for mixed discrete-continuous signals and address challenges of temporal complexity and trip-specific variability. Our results show that one pretrained CAN model can adapt effectively to diverse predictive tasks, validating that the foundation modeling paradigm, proven in NLP and CV, also holds for CAN data. This establishes a new direction for generalizable representation learning in automotive AI.
Action Engine: An LLM-based Framework for Automatic FaaS Workflow Generation
Nov 29, 2024Function as a Service (FaaS) is poised to become the foundation of the next generation of cloud systems due to its inherent advantages in scalability, cost-efficiency, and ease of use. However, challenges such as the need for specialized knowledge and difficulties in building function workflows persist for cloud-native application developers. To overcome these challenges and mitigate the burden of developing FaaS-based applications, in this paper, we propose a mechanism called Action Engine, that makes use of Tool-Augmented Large Language Models (LLMs) at its kernel to interpret human language queries and automates FaaS workflow generation, thereby, reducing the need for specialized expertise and manual design. Action Engine includes modules to identify relevant functions from the FaaS repository and seamlessly manage the data dependency between them, ensuring that the developer's query is processed and resolved. Beyond that, Action Engine can execute the generated workflow by feeding the user-provided parameters. Our evaluations show that Action Engine can generate workflows with up to 20\% higher correctness without developer involvement. We notice that Action Engine can unlock FaaS workflow generation for non-cloud-savvy developers and expedite the development cycles of cloud-native applications.
A Multi-Level Approach for Class Imbalance Problem in Federated Learning for Remote Industry 4.0 Applications
Sep 24, 2024



Deep neural network (DNN) models are effective solutions for industry 4.0 applications (\eg oil spill detection, fire detection, anomaly detection). However, training a DNN network model needs a considerable amount of data collected from various sources and transferred to the central cloud server that can be expensive and sensitive to privacy. For instance, in the remote offshore oil field where network connectivity is vulnerable, a federated fog environment can be a potential computing platform. Hence it is feasible to perform computation within the federation. On the contrary, performing a DNN model training using fog systems poses a security issue that the federated learning (FL) technique can resolve. In this case, the new challenge is the class imbalance problem that can be inherited in local data sets and can degrade the performance of the global model. Therefore, FL training needs to be performed considering the class imbalance problem locally. In addition, an efficient technique to select the relevant worker model needs to be adopted at the global level to increase the robustness of the global model. Accordingly, we utilize one of the suitable loss functions addressing the class imbalance in workers at the local level. In addition, we employ a dynamic threshold mechanism with user-defined worker's weight to efficiently select workers for aggregation that improve the global model's robustness. Finally, we perform an extensive empirical evaluation to explore the benefits of our solution and find up to 3-5% performance improvement than baseline federated learning methods.
Edge-MultiAI: Multi-Tenancy of Latency-Sensitive Deep Learning Applications on Edge
Nov 14, 2022



Smart IoT-based systems often desire continuous execution of multiple latency-sensitive Deep Learning (DL) applications. The edge servers serve as the cornerstone of such IoT-based systems, however, their resource limitations hamper the continuous execution of multiple (multi-tenant) DL applications. The challenge is that, DL applications function based on bulky "neural network (NN) models" that cannot be simultaneously maintained in the limited memory space of the edge. Accordingly, the main contribution of this research is to overcome the memory contention challenge, thereby, meeting the latency constraints of the DL applications without compromising their inference accuracy. We propose an efficient NN model management framework, called Edge-MultiAI, that ushers the NN models of the DL applications into the edge memory such that the degree of multi-tenancy and the number of warm-starts are maximized. Edge-MultiAI leverages NN model compression techniques, such as model quantization, and dynamically loads NN models for DL applications to stimulate multi-tenancy on the edge server. We also devise a model management heuristic for Edge-MultiAI, called iWS-BFE, that functions based on the Bayesian theory to predict the inference requests for multi-tenant applications, and uses it to choose the appropriate NN models for loading, hence, increasing the number of warm-start inferences. We evaluate the efficacy and robustness of Edge-MultiAI under various configurations. The results reveal that Edge-MultiAI can stimulate the degree of multi-tenancy on the edge by at least 2X and increase the number of warm-starts by around 60% without any major loss on the inference accuracy of the applications.
FELARE: Fair Scheduling of Machine Learning Applications on Heterogeneous Edge Systems
Jun 09, 2022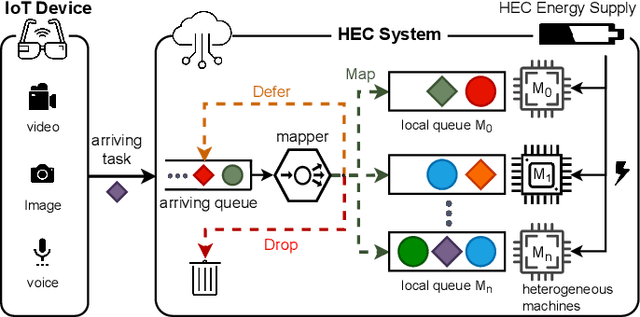
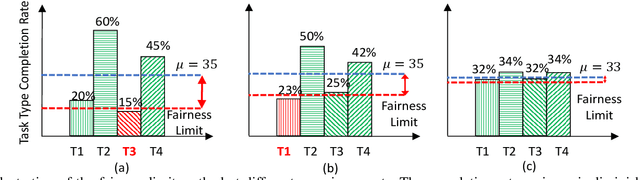
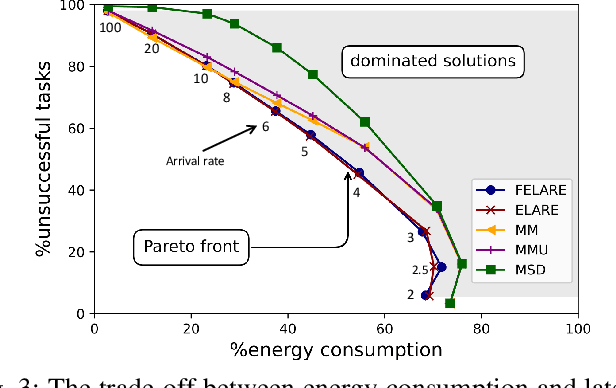
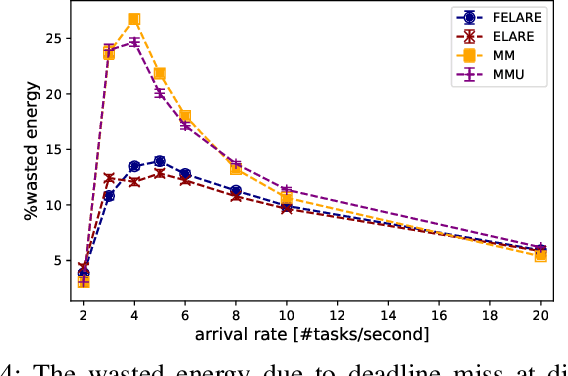
Edge computing enables smart IoT-based systems via concurrent and continuous execution of latency-sensitive machine learning (ML) applications. These edge-based machine learning systems are often battery-powered (i.e., energy-limited). They use heterogeneous resources with diverse computing performance (e.g., CPU, GPU, and/or FPGAs) to fulfill the latency constraints of ML applications. The challenge is to allocate user requests for different ML applications on the Heterogeneous Edge Computing Systems (HEC) with respect to both the energy and latency constraints of these systems. To this end, we study and analyze resource allocation solutions that can increase the on-time task completion rate while considering the energy constraint. Importantly, we investigate edge-friendly (lightweight) multi-objective mapping heuristics that do not become biased toward a particular application type to achieve the objectives; instead, the heuristics consider "fairness" across the concurrent ML applications in their mapping decisions. Performance evaluations demonstrate that the proposed heuristic outperforms widely-used heuristics in heterogeneous systems in terms of the latency and energy objectives, particularly, at low to moderate request arrival rates. We observed 8.9% improvement in on-time task completion rate and 12.6% in energy-saving without imposing any significant overhead on the edge system.
Exploring the Impact of Virtualization on the Usability of the Deep Learning Applications
Dec 17, 2021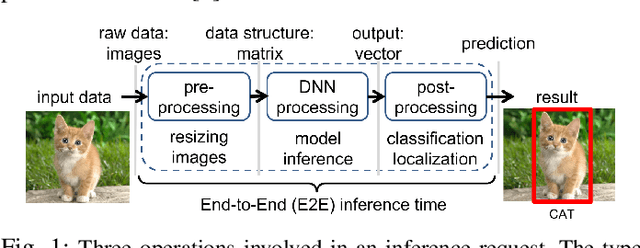
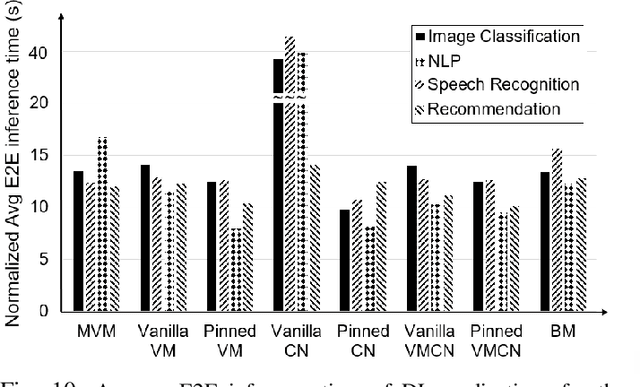
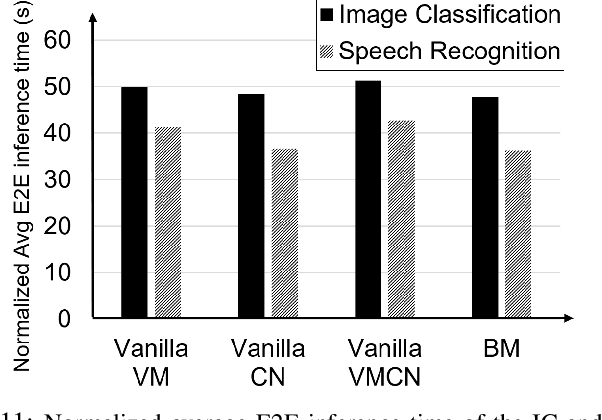
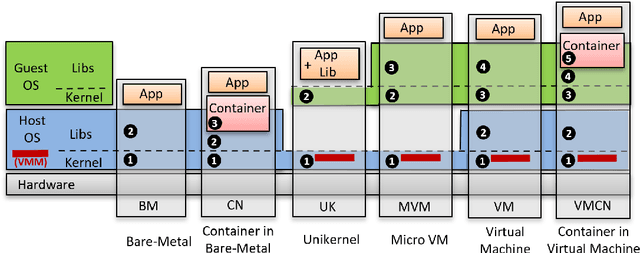
Deep Learning-based (DL) applications are becoming increasingly popular and advancing at an unprecedented pace. While many research works are being undertaken to enhance Deep Neural Networks (DNN) -- the centerpiece of DL applications -- practical deployment challenges of these applications in the Cloud and Edge systems, and their impact on the usability of the applications have not been sufficiently investigated. In particular, the impact of deploying different virtualization platforms, offered by the Cloud and Edge, on the usability of DL applications (in terms of the End-to-End (E2E) inference time) has remained an open question. Importantly, resource elasticity (by means of scale-up), CPU pinning, and processor type (CPU vs GPU) configurations have shown to be influential on the virtualization overhead. Accordingly, the goal of this research is to study the impact of these potentially decisive deployment options on the E2E performance, thus, usability of the DL applications. To that end, we measure the impact of four popular execution platforms (namely, bare-metal, virtual machine (VM), container, and container in VM) on the E2E inference time of four types of DL applications, upon changing processor configuration (scale-up, CPU pinning) and processor types. This study reveals a set of interesting and sometimes counter-intuitive findings that can be used as best practices by Cloud solution architects to efficiently deploy DL applications in various systems. The notable finding is that the solution architects must be aware of the DL application characteristics, particularly, their pre- and post-processing requirements, to be able to optimally choose and configure an execution platform, determine the use of GPU, and decide the efficient scale-up range.
SAED: Edge-Based Intelligence for Privacy-Preserving Enterprise Search on the Cloud
Mar 11, 2021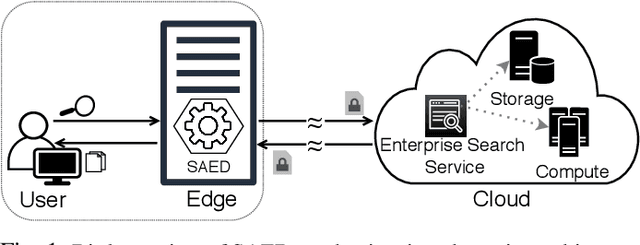
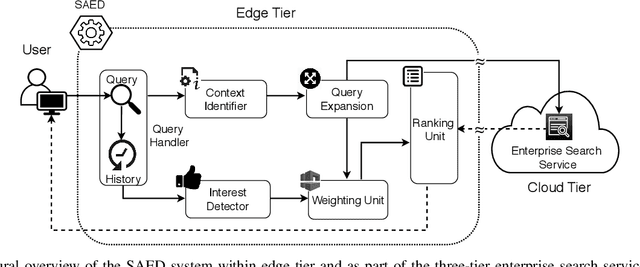
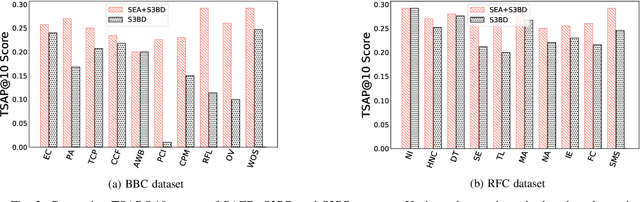
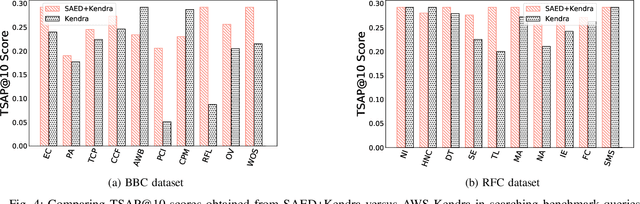
Cloud-based enterprise search services (e.g., AWS Kendra) have been entrancing big data owners by offering convenient and real-time search solutions to them. However, the problem is that individuals and organizations possessing confidential big data are hesitant to embrace such services due to valid data privacy concerns. In addition, to offer an intelligent search, these services access the user search history that further jeopardizes his/her privacy. To overcome the privacy problem, the main idea of this research is to separate the intelligence aspect of the search from its pattern matching aspect. According to this idea, the search intelligence is provided by an on-premises edge tier and the shared cloud tier only serves as an exhaustive pattern matching search utility. We propose Smartness At Edge (SAED mechanism that offers intelligence in the form of semantic and personalized search at the edge tier while maintaining privacy of the search on the cloud tier. At the edge tier, SAED uses a knowledge-based lexical database to expand the query and cover its semantics. SAED personalizes the search via an RNN model that can learn the user interest. A word embedding model is used to retrieve documents based on their semantic relevance to the search query. SAED is generic and can be plugged into existing enterprise search systems and enable them to offer intelligent and privacy-preserving search without enforcing any change on them. Evaluation results on two enterprise search systems under real settings and verified by human users demonstrate that SAED can improve the relevancy of the retrieved results by on average 24% for plain-text and 75% for encrypted generic datasets.
SensPick: Sense Picking for Word Sense Disambiguation
Feb 10, 2021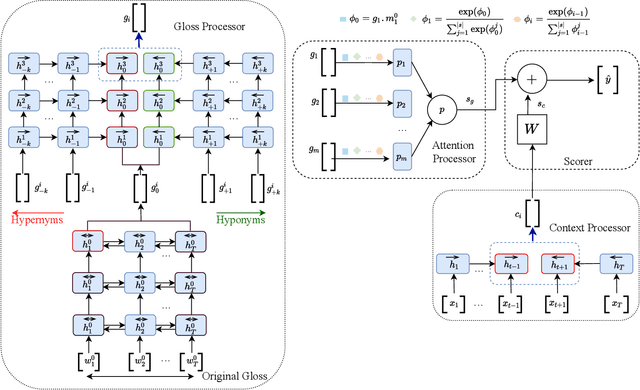
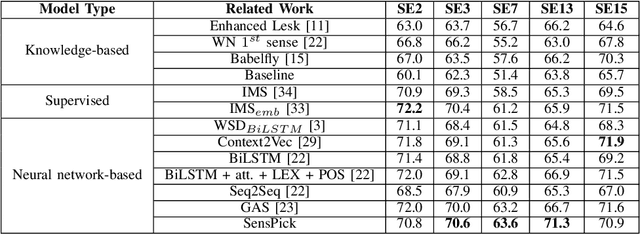
Word sense disambiguation (WSD) methods identify the most suitable meaning of a word with respect to the usage of that word in a specific context. Neural network-based WSD approaches rely on a sense-annotated corpus since they do not utilize lexical resources. In this study, we utilize both context and related gloss information of a target word to model the semantic relationship between the word and the set of glosses. We propose SensPick, a type of stacked bidirectional Long Short Term Memory (LSTM) network to perform the WSD task. The experimental evaluation demonstrates that SensPick outperforms traditional and state-of-the-art models on most of the benchmark datasets with a relative improvement of 3.5% in F-1 score. While the improvement is not significant, incorporating semantic relationships brings SensPick in the leading position compared to others.
Analyzing the Performance of Smart Industry 4.0 Applications on Cloud Computing Systems
Dec 11, 2020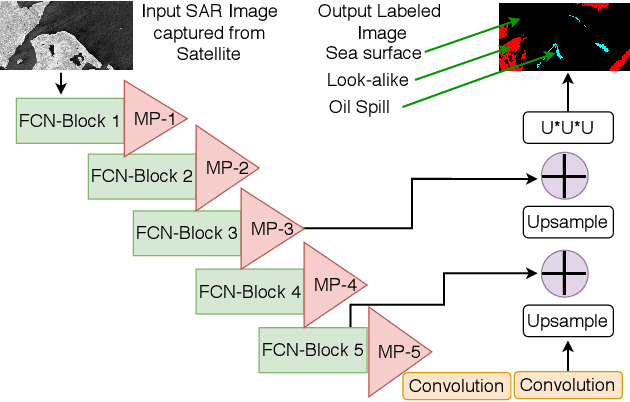

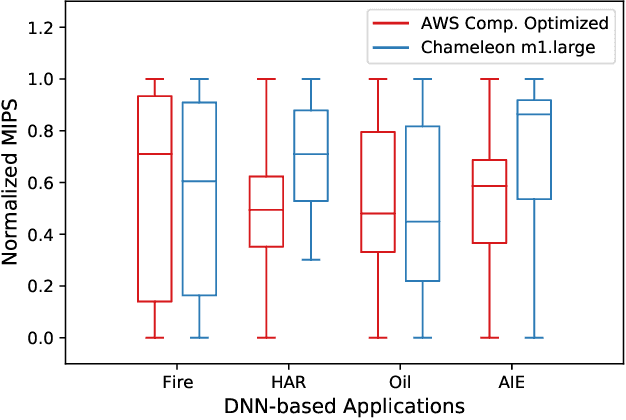
Cloud-based Deep Neural Network (DNN) applications that make latency-sensitive inference are becoming an indispensable part of Industry 4.0. Due to the multi-tenancy and resource heterogeneity, both inherent to the cloud computing environments, the inference time of DNN-based applications are stochastic. Such stochasticity, if not captured, can potentially lead to low Quality of Service (QoS) or even a disaster in critical sectors, such as Oil and Gas industry. To make Industry 4.0 robust, solution architects and researchers need to understand the behavior of DNN-based applications and capture the stochasticity exists in their inference times. Accordingly, in this study, we provide a descriptive analysis of the inference time from two perspectives. First, we perform an application-centric analysis and statistically model the execution time of four categorically different DNN applications on both Amazon and Chameleon clouds. Second, we take a resource-centric approach and analyze a rate-based metric in form of Million Instruction Per Second (MIPS) for heterogeneous machines in the cloud. This non-parametric modeling, achieved via Jackknife and Bootstrap re-sampling methods, provides the confidence interval of MIPS for heterogeneous cloud machines. The findings of this research can be helpful for researchers and cloud solution architects to develop solutions that are robust against the stochastic nature of the inference time of DNN applications in the cloud and can offer a higher QoS to their users and avoid unintended outcomes.